spark中的闭包与广播变量
Spark 任务调度图(以Spark Core为例)
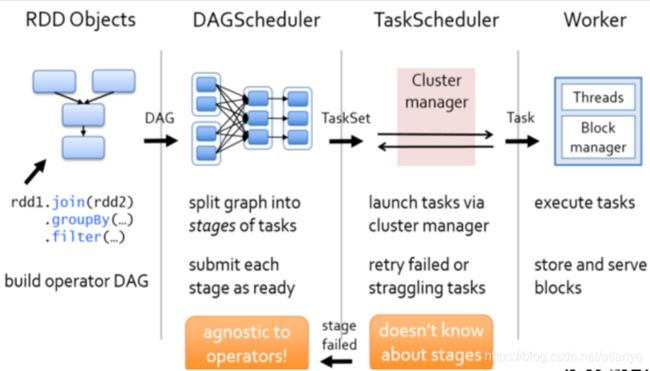
1. DAG的应用
Spark的Job(Application),从宏观上来看处理过程大致如下:
- 加载数据,获取RDD(或DF等)
- 转换数据
- 执行转换,获取结果并处理
整个计算过程是从上往下的(有方向),但是没有上下往复的处理(无循环),从图的角度我们可以将这个过程抽象为一个【DAG】(Directed Acyclic Graph)。
数据处理过程中的各个步骤(如filter、map、reduce等)是连续的,每个步骤处理的输入数据集我们称为“父数据集”,本步骤处理后的输出数据集我们成为“子数据集”,这两个数据集我们称它们之间有依赖关系(父数据集经过加工得到子数据集)。如果父数据集中的数据分散到了N多(N>1)个子数据集中,我们称这种依赖关系为【宽依赖】,否则为【窄依赖】。
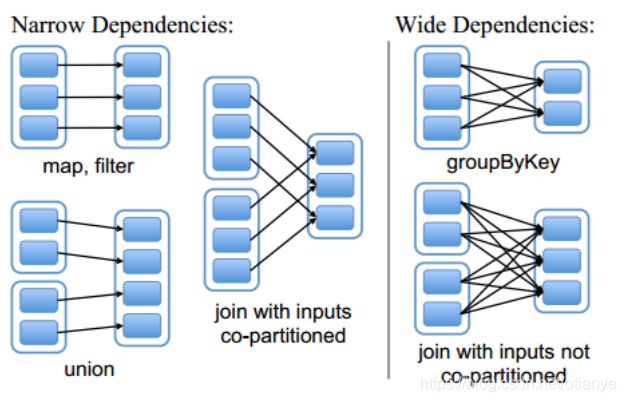
Spark中将DAG按宽依赖进行切割,每一部分称为一个【Stage】(阶段)。
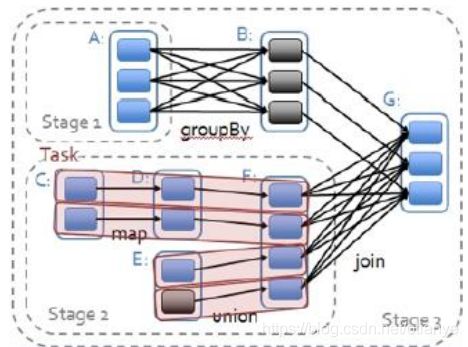
每个Stage中都有N个并行执行的计算,每个并行的计算称为一个pipe-line,或者称为一个【task】。
注意:①task是运行的最小单位;
②stage中会为每个需要计算的partition生成一个task——每个task只处理一个partition(数据的分片);
③每个task中的引用的数据都是独立的一份(互不干涉);
④task在执行器(Executor)中执行,每个Executor可以同时运行多个Task;
executor是一个独立的JVM进程,每个任务会有独立的线程来执行。
⑤集群中同时并行执行的task最大数量 = 所有executor的cores之和
configure ‘spark.default.parallelism’ depends on the cluster manager:
Local mode: number of cores on the local machine
Mesos fine grained mode: 8
Others: total number of cores on all executor nodes or 2, whichever is larger
由于每个task最少使用一个cpu core,所以集群中并行task的数量最多与所有executor的cores之和一致
如果集群中的executor配置一致,计算公式为: num-executors * (executor-cores / 每个task占用核心数)
关于参数设置,建议参考spark官网的资料(以spark 2.2.1为例,链接为https://spark.apache.org/docs/2.2.1/configuration.html)
2. 闭包
【闭包】:是一个函数,这个函数的执行结果由外部自由变量(不是函数的局部变量也不是函数的参数,也称字面量)决定——函数执行时,才捕获相关的自由变量(获取自由变量的当前值),从而形成闭合的函数。
spark执行一个Stage时,会为待执行函数(function,也称为【算子】)建立闭包(捕获函数引用的所有数据集),形成该Stage所有task所需信息的二进制形式,然后把这个闭包发送到集群的每个Executor上。
注意:由于每个task中引用的数据都是独立的(上文提到过),即使许多task使用同一个数据集(比如task需要将ID转为Name,这时需要一个ID-Name对照表),这个公共的对照表将在每个task中都创建一份。假设该对照表20M,某Job有1000个task需要引用该对照表,那么spark集群中2G(1000*20M)的内存空间资源将被该对照表占用。有没有更好的、更节约资源的方式?
3. 广播变量
当许多task需要访问同一个(不可变)的数据集时,更理想的方式是将这个数据集合共享使用。【广播变量】(broadcast)技术可以将公共的数据集缓存到Executor上,该Executor上所有的task都能共享这份数据(而不是每个task保存一份了)。广播变量对task闭包的常规处理进行扩展:
- 线程安全的
- 有点类似于java中的全局变量
- 在Driver定义,在Executor读取(不能修改)
- 在每个executor上将数据缓存为原始的java对象,这样就不用为每个task执行反序列化
- 在多个job、stage和task之间分享数据
广播变量的定义及使用示例:
import org.apache.spark._
/**
* 【spark 2.2.1】
*
* 广播变量(相当于java中的全局变量,用于executor上进行数据共享)
* 在Driver定义,在Executor读取
* Executor端不能修改
* 线程安全: 多线程下计算的结果与单线程一致
*
* by [email protected]
**/
object BroadcaseDemo {
def main(args: Array[String]): Unit = {
// spark configure
val conf=new SparkConf()
.setMaster("local")
.setAppName("BroadcaseDemo")
// spark context
val sc = new SparkContext(conf)
// block some str in 'names' file
val ary = Array (
"Hanhong",
"Fengjie",
"Wuyifan"
)
val rdd1 = sc.textFile("names")
rdd1.foreach { println }
println
/**
* 1. 使用普通方式
* 对task而言,ary属于外部变量,每个task都有一个ary的副本
* ☆ 如果task多 + ary大,会导致大量的堆内存占用
* */
rdd1.filter { !ary.contains(_) }.foreach { println }
/**
* 2. 使用集群思维【广播变量】
* Executor中的所有task共享这个变量,每个Executor只需要一个ary副本就可以了
*
* */
//定义广播变量boradAry
val boradAry = sc.broadcast(ary)
// 调用广播变量boradAry使用“boradAry.value”
rdd1.filter { !boradAry.value.contains(_) }.foreach { println }
// close spark context
sc.stop
}
}