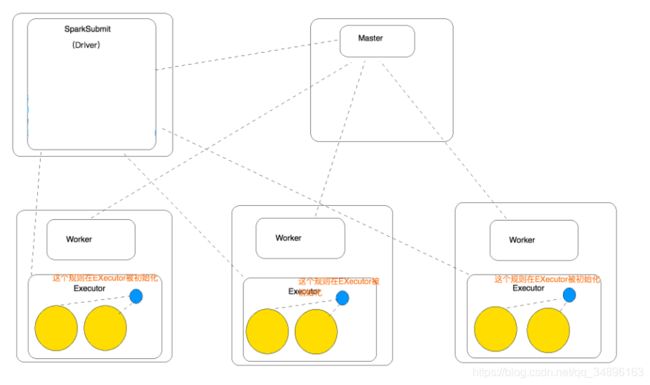
Spark自定义类在Driver和Executor端传输问题
方式一:自定义一个类,并且这个类需要实现Serializable接口
1.首先写一个class自定义类
class Rules extends Serializable {
val rulesMap = Map("hadoop" -> 2.7, "spark" -> 2.2)
//val hostname = InetAddress.getLocalHost.getHostName
//println(hostname + "@@@@@@@@@@@@@@@@")
}
2.写一个spark程序
val conf = new SparkConf().setAppName("SerTest")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0))
val r = lines.map(word => {
val rules = new Rules
val hostname = InetAddress.getLocalHost.getHostName
val threadName = Thread.currentThread().getName
(hostname, threadName, rules.rulesMap.getOrElse(word, 0), rules.toString)
})
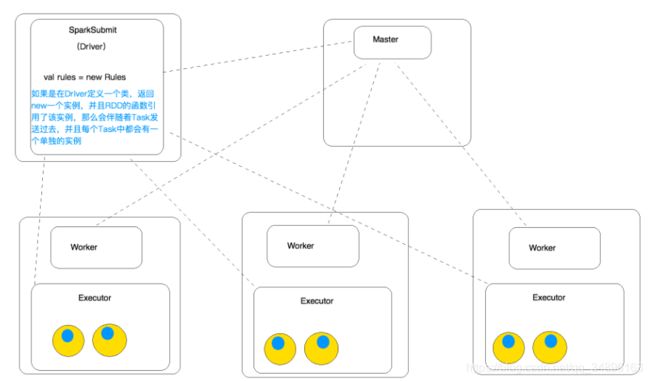
总结:如果采用这种方式的话,会导致rules对象被多次创建,因为map方法是对RDD中的每一条数据都执行那里面的算法的,所以说这种方式会造成资源的浪费。自定义的类要想在算子中使用的话,就必须将自定义的类进行序列化,也就是基层Serializable接口,不然会抛异常Rules对象应该在算子外面进行new,如下:
val conf = new SparkConf().setAppName("SerTest")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0))
val rules = new Rules
val r = lines.map(word => {
val hostname = InetAddress.getLocalHost.getHostName
val threadName = Thread.currentThread().getName
(hostname, threadName, rules.rulesMap.getOrElse(word, 0), rules.toString)
})
因为算子中的变量都会被发送到Executor端进行执行,所以Driver端new出来的对象会被发送到Executor端进行执行的,如果Executor端有多个task的话,那么这个实例就会被分发到多个task中,也就是每个task会保存一个实例,这样做会造成资源的浪费,具体细节如下图:
方式二:自定义一个object对象,这个对象同样要实现Serializable接口
1.自定义一个object对象,使用object修饰的话,这个类相当于java中的单例对象,只会被初始化一次。
在这里插入代码片object Rules extends Serializable {
val rulesMap = Map("hadoop" -> 2.7, "spark" -> 2.2)
val hostname = InetAddress.getLocalHost.getHostName
println(hostname + "@@@@@@@@@@@@@@@@!!!!")
}
2.实例化这个单例对象
val conf = new SparkConf().setAppName("SerTest")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0))
val rules = Rules
val r = lines.map(word => {
val hostname = InetAddress.getLocalHost.getHostName
val threadName = Thread.currentThread().getName
//rules的实际是在Executor中使用的
(hostname, threadName, rules.rulesMap.getOrElse(word, 0), rules.toString)
})
总结:这里的Rules的object对象是需要被序列化的,在scala中使用object修饰的类是单例的
在类加载的时候时候就会回被初始化,也就是说,因为这里rules是在map外面定义的,所以这个类只会被初始化一次,然后再task任务提交的时候,会见这个对象发送到对应的Executor上,并且每个worker上的Executor上多个task公用一个rules对象,这样做的好处是在同一个Executor中多个task可以公用一个rules对象。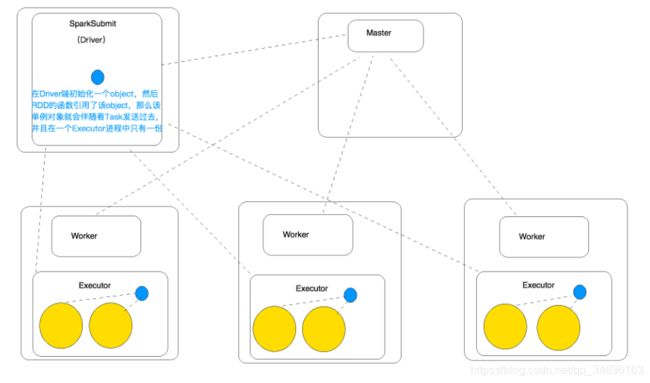
方式三:前两种方式都是在Driver端实例化这个对象的,在后期程序执行的时候会见这个实例化过的对象随着task对象的发送而发送到Executor端执行,如果数据量特别大的情况下,会造成网络带宽的消耗,最理想的方式就是直接在Executor端创建 这个实例化的对象,因为scala中object修饰的对象是单例的,所以最好的方式就是在Executor端直接调用这个单例对象:这里不进行序列化的原因是因为,不需要将对象从Driver端发送到Executor端,而是直接在Executor端生成
1.第三种方式,希望Rules在EXecutor中被初始化(不走网络了,就不必实现序列化接口)
object Rules {
val rulesMap = Map("hadoop" -> 2.7, "spark" -> 2.2)
val hostname = InetAddress.getLocalHost.getHostName
println(hostname + "@@@@@@@@@@@@@@@@!!!!")
}
2.编写spark程序
val conf = new SparkConf().setAppName("SerTest")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile(args(0))
val r = lines.map(word => {
//函数的执行是在Executor执行的(Task中执行的)
val hostname = InetAddress.getLocalHost.getHostName
val threadName = Thread.currentThread().getName
(hostname, threadName, Rules.rulesMap.getOrElse(word, 0), Rules.toString)
})
这里直接调用Rules单例对象,然后调用里面的静态方法,因为单例对象中的方法都是单例的,不需要再进行new obj ,而是直接调用的。这样做的好处就是最终 Rules会随着Task直接发送到Executor上,初始化的时候直接在Executor端进行了。可以将规则信息使用这种方式进行发送到对应的Executor中。