R语言初级作业
- 打开
Rstudio告诉我它的工作目录。
getwd()
- 新建6个向量,基于不同的
原子类型。(重点是字符串,数值,逻辑值)
# 首先明确6种不同的原子类型(atomic vectors):1.numberic(数值) 2. character(字符), 3. logical(逻辑型) 4. interger(整数) 5. complex(复数) 6. raw(原始)
v1=c(1,2,3,4,5)
v2=c("a","b","c")
v3=c(TRUE,TRUE,FALSE)
v4=3L
v5=2i+1
v6=charToRaw('raw')
- 新建一些数据结构,比如矩阵,数组,数据框,列表等重点是数据框,矩阵)
# 数据结构,在R中主要有:1. vectors|向量 2.Lists|列表 3. Matrics|矩阵 4. Arrays|数组 5. Factors |因子 6. DataFrames|数据框
v1<- c(1:15)
list_1<- list(v1,"3",FALSE)
mat_1<- matrix(c(1:15),nrow=3,byrow=T)
arr_1<- array(c("a","b"),dim=c(3,2,2))
fac_1<-factor(v1)
df_1<- data.frame(roomates=c("xl","xw","xl"),
height=c("174","180","145"),
weight=c("70","80","145"),
age=c("19","21","120"),
glass=c("na","d","na"),
food=c("lamian","mifan","xiangjiao"))
- 在你新建的数据框进行切片操作,比如首先取第1,3行, 然后取第4,6列
df_1[1,] #第1行
df_1[3,] #第3行
df_1[c(1,3),] #第1行与第3行
df_1[,4]#第4列
df_1[,6]#第6列
df_1[,c(4,6)] #第4列与第6列
- 使用data函数来加载R内置数据集
rivers描述它。
rivers
head(rivers)
typeof(rivers)
summary(rivers)
tail(rivers)
length(rivers)
str(rivers)
plot(rivers)
- 下载 https://www.ncbi.nlm.nih.gov/sra?term=SRP133642 里面的
RunInfo Table文件读入到R里面,了解这个数据框,多少列,每一列都是什么属性的元素。
rm(list = ls())
options(stringsAsFactors = F)
a=read.csv(file = "SraRunTable (1).txt",sep = '\t',header = T)
class(a)
dim(a)
str(a)
- 下载 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE111229 里面的
样本信息sample.csv读入到R里面,了解这个数据框,多少列,每一列都是什么属性的元素。
# 这次试一下getGEO的方法
library(GEOquery) #加载GEOquery这个包
gset<-getGEO('GSE111229',getGPL = F) #使用getGEO函数下载数据
save(gset,file='gset.Rdata') #数据下载好之后先保存为Rdata
load("gset.Rdata") #导入数据
pdata<- pData(gset[[1]]) #我们要操作的东西都在gset这个大list的第一个List下面,pData功能可以调用数据里的实验内容
class(pdata)
dim(pdata)
colnames(pdata) #geo_accession就是样品名
- 把前面两个步骤的两个表(
RunInfo Table文件,样本信息sample.csv)关联起来,使用merge函数。
colnames(a)#因为根据两个表格共有的样本名来进行merge,看一下在不同表格中的列名
df_merge=merge(a,pdata,by.x='Sample_Name',by.y='geo_accession')
- 对前面读取的
RunInfo Table文件在R里面探索其MBases列,包括 箱线图(boxplot)和五分位数(fivenum),还有频数图(hist),以及密度图(density) 。
boxplot(a$MBases)
fivenum(a$MBases)
[1] 0 8 12 16 74
boxplot(a$MBases)
fivenum(a$MBases)
hist(a$MBases)
density(a$MBases)
- 把前面读取的
样本信息表格的样本名字根据下划线分割看第3列元素的统计情况。第三列代表该样本所在的plate
title=pdata$title
class(title)
title
plate=unlist(lapply(title, function(x){
x
strsplit(x,'_')[[1]][3]
}))
plate
table(plate)
plate
0048 0049
384 384
- 根据plate把关联到的
RunInfo Table信息的MBases列分组检验是否有统计学显著的差异。
# plate是指两个384孔板,编号分别是48号与49号;这个之前有所困惑,在原文搜索plate才解答了疑问,也是因为没有做过单细胞测序的流程,不知道需要用到384孔板
t.test(df_merge$MBases~plate)
data: df_merge$MBases by plate
t = 2.3019, df = 728.18,
p-value = 0.02162
- 分组绘制箱线图(boxplot),频数图(hist),以及密度图(density) 。
# 由于这里也不知道MBases的M是什么意思,所以还是有一点疑问。
boxplot(df_merge$MBases~plate)
e=df_merge[,c("MBases","Sample_Name")]
e$plate=plate
head(e)
tail(e)
# hist问题
hist(e$MBases,breaks = "plate") #这样会报错,还没有查到原因
- 使用ggplot2把上面的图进行重新绘制。
## https://www.cnblogs.com/muchen/p/5430536.html 参照这个代码的
#boxplot
e$plate=factor(e$plate)
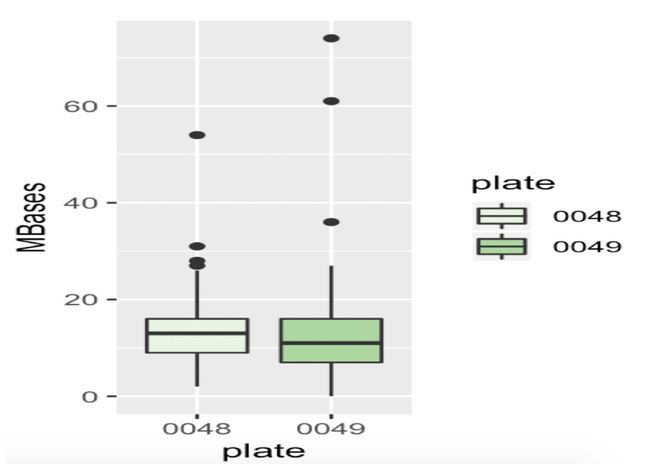
ggplot(e,aes(x=plate,y=MBases,fill=plate))+
geom_boxplot()+
scale_fill_brewer(palette = 'Paste12')
#hist
library(ggplot2)
e$plate=factor(e$plate) #将plate转换为因子类型
e$plate
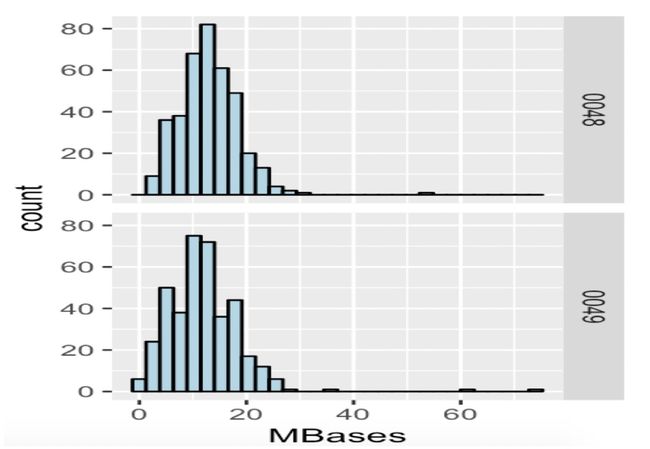
ggplot(e,aes(x=MBases))+
geom_histogram(fill='lightblue',colour='black')+
facet_grid(plate ~ .)
#密度图
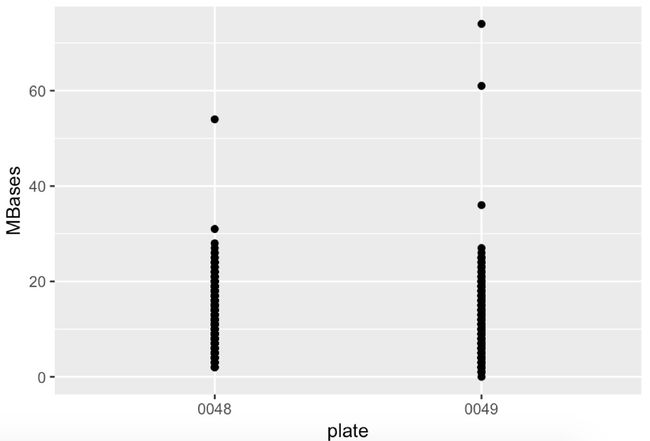
ggplot(e,aes(x=plate,y=MBases))+
geom_point()+
stat_density2d(aes(alpha=..density..),geom="raster",contour=F)
boxplot.jpg
density.jpg
histgram.jpg
- 使用ggpubr把上面的图进行重新绘制。
# 直接试了答案的代码
library(ggpubr)
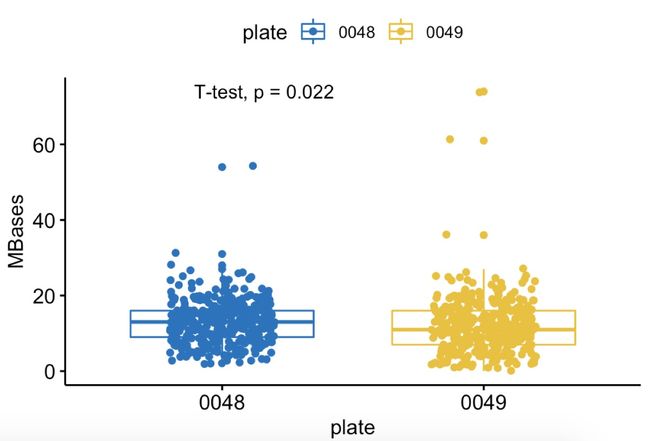
p<-ggboxplot(e,x="plate",y="MBases",
color = "plate",palette = 'jco',
add = 'jitter')
p+stat_compare_means(method = 't.test')
last.jpg
- 随机取384个MBases信息,跟前面的两个plate的信息组合成新的数据框,第一列是分组,第二列是MBases,总共是384*3行数据。
#使用sample函数,不知道有没有理解对题目
new=sample(e[,1],385,replace = F)
new
new_1=e[new,]
new_1=new_1[,c(3,1,2)]
花费时间总共5个小时,主要卡在了对于实验设计的不理解,plate那里不是很懂,内置的hist以及density也没有搜到好用的教学,可能得从头翻一下视频。