TensorFlow中关于LeNet-5网络的一些小坑
本篇文章提到的一些坑主要来自于学习《TensorFlow实战Google深度学习框架》一书第6.4章节中关于使用LeNet5做MNIST
一 LeNet-5简介
LeNet-5模型是Yann LeCun教授于1998年在论文Gradient-based learning applied to document recognition中提出的,它是第一个成功应用于数字识别问题的卷积神经网络。LeNet-5模型一共有7层,LeNet-5模型的结果框架图如下: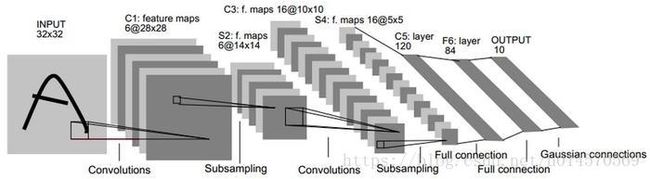
layer1:卷积层Conv1
接收输入层大小[32,32,1],经过尺寸为[5,5,6],步长为1的过滤器的无全0填充卷积运算,将得到[28,28,6]的卷积结果。
layer2:池化层Pool1
接收layer1,经过尺寸为[2,2],步长为2的过滤器进行最大值池化,得到[14,14,6]的池化结果。
layer3:卷积层Conv2
接收layer2,经过尺寸为[5,5,16],步长为1的过滤器的无全0填充卷积运算,将得到[10,10,16]的卷积结果。
layer4:池化层Pool2
接收layer3,经过尺寸为[2,2],步长为2的过滤器进行最大值池化,得到[5,5,16]的池化结果。
将[5,5,16]的结果转化成FC层可接收数据形式,即将[5,5,16]reshpe成[1,5*5*16]
layer5:全连接层FC1
接收layer4,将400个节点进行全连接,输出120个节点
layer6:全连接层FC2
接收layer5,将120个节点进行全连接,输出84个节点
layer7:全连接层SoftMax
接收layer5,将84个节点进行全连接,输出10个节点
二 书中示例代码
# -*- coding=utf-8 -*-
"""
LeNet网络结构代码
lenet_inference.py
"""
import tensorflow as tf
# 配置神经网络参数
INPUT_NODE = 784
OUTPUT_NODE = 10
# 配置图像数据参数
IMAGE_SIZE = 28
NUM_CHANNELS = 1
NUM_LABELS = 10
# 第一层卷积层尺寸和深度
CONV1_SIZE = 5
CONV1_DEEP = 32
# 第二层卷积层尺寸和深度
CONV2_SIZE = 5
CONV2_DEEP = 64
# 全连接层的节点个数
FC_SIZE = 512
def inference(input_tensor, train, regularizer):
# 定义第一层卷积层:输入28×28×1 输出28×28×32
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable('weight', [CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable('bias', [CONV1_DEEP], initializer=tf.constant_initializer(0.0))
# 使用5×5×32的过滤器,步长为1,全0填充
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
# 使用relu激活函数
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
# 定义第二层池化层:输入28×28×32 输出14×14×32
with tf.name_scope('layer2-pool1'):
# ksize和strides首尾必须为1,ksize过滤器尺寸,strides步长
pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 定义第三层卷积层:输入14×14×32 输出14×14×64
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable('weight', [CONV2_SIZE, CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias', [CONV2_DEEP], initializer=tf.constant_initializer(0.0))
# 使用5×5×64的过滤器,步长为1,全0填充
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
# 使用relu激活函数
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
# 定义第四层池化层:输入14×14×64 输出7×7×64
with tf.name_scope('layer4-pool2'):
# ksize和strides首尾必须为1,ksize过滤器尺寸,strides步长
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 将池化结果转化为全连接层的输入:输入7×7×64 输出3136×1
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
# 定义第5层全连接层:输入3136×1 输出512×1
with tf.variable_scope('layer5-fc1'):
# 只有全连接层的权重需要加入正则化
fc1_weights = tf.get_variable('weight', [nodes, FC_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
fc1_biases = tf.get_variable('bias', [FC_SIZE], initializer=tf.constant_initializer(0.1))
# 使用relu激活函数
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc1_weights))
# dropout避免过拟合:在训练过程中会随机将部分节点输出为0
if train: fc1 = tf.nn.dropout(fc1, 0.5)
# 定义第6层softmax层:输入512×1 输出10×1
with tf.variable_scope('layer6-fc2'):
# 只有全连接层的权重需要加入正则化
fc2_weights = tf.get_variable('weight', [FC_SIZE, NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2_biases = tf.get_variable('bias', [NUM_LABELS], initializer=tf.constant_initializer(0.1))
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc2_weights))
# 使用relu激活函数
logit = tf.matmul(fc1, fc2_weights) + fc2_biases
return logit# -*- coding:utf-8 -*-
'''
训练LeNet
lenet_train.py
'''
import os
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import lenet_inference as mnist_inference
# 配置神经网络参数
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.00010
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径和文件名
MODEL_SAVE_PATH = 'MNIST_MODEL'
MODEL_NAME = 'model.ckpt'
'''
训练模型
'''
def train(mnist):
# 定义输入输出的placeholder
x = tf.placeholder(tf.float32, [BATCH_SIZE, 28, 28, 1], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
# 定义L2正则化损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 前向传播
y = mnist_inference.inference(x, True, regularizer)
global_step = tf.Variable(0, trainable=False)
# 带滑动平均模型的前向传播
variable_averages = tf.train.ExponentialMovingAverage(decay=MOVING_AVERAGE_DECAY, num_updates=global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算损失函数
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y_, 1), logits=y)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 反向传播
# 设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY)
# 定义优化损失函数
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 更新参数[反向传播+滑动平均]
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train') # 什么也不做
# 初始化Tensorflow持久化类
saver = tf.train.Saver()
# 初始化会话并开始训练
with tf.Session() as sess:
# 初始化所有变量
tf.global_variables_initializer().run()
# 迭代训练神经网络
for i in range(TRAINING_STEPS):
# 产生本轮batch的训练数据,并运行训练程序
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs, (BATCH_SIZE, 28, 28, 1))
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys})
# 每1000轮保存一次模型
if i % 1000 == 0:
# 通过损失函数的大小了解本轮训练的基本情况
print("\rAfter %d training step(s), loss on training batch is %g" % (step, loss_value), end='')
# 保存模型,给出global_step参数可以让每个被保存的文件名末尾加上训练的轮数
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
# 主程序入口
def main(argv=None):
# 如果指定路径下没有数据,则自动下载
mnist = input_data.read_data_sets("MNIST_DATA", one_hot=True)
train(mnist)
# TensorFlow提供的一个主程序入口
if __name__ == '__main__':
tf.app.run()# -*- coding=utf-8 -*-
"""
测试神经网络准确率
lenet_eval.py
"""
import time
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import lenet_inference as lenet
import lenet_train as nt
# 每10秒加载一次最新模型,并计算其正确率
EVAL_INTERVAL_SECS = 10
BATCH_SIZE = 100
def evaluate(mnist):
# 准备验证数据
xs = mnist.validation.images
ys = mnist.validation.labels
print('xs.shape:{}, ys.shape:{}'.format(xs.shape, ys.shape))
reshaped_xs = np.reshape(xs, [xs.shape[0], 28, 28, 1])
with tf.Graph().as_default() as g:
# 定义输入输出的placeholder
x = tf.placeholder(tf.float32, [xs.shape[0], 28, 28, 1], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
validate_feed = {x: reshaped_xs, y_: mnist.validation.labels}
# 前向传播,测试不关注正则化
y = lenet.inference(x, train=False, regularizer=None)
# 计算模型预测精度
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# 将比尔型转化为float32并求平均值,即得一组数据的正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 通过变量重命名的方式来加载模型
# 这样在前向传播的过程中就不需要调用求滑动平均的函数来获取平均值
# 这样就可以完全共用mnist_inference.py中定义的前向传播过程
variable_averages = tf.train.ExponentialMovingAverage(nt.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
# 每隔EVAL_INTERVAL_SECS秒调用一次计算正确率的过程以检测训练过程中正确率的变化
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(nt.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict=validate_feed)
print('After %s training step(s), validation accuracy=%g' % (global_step, accuracy_score))
else:
print('No checkpoint file found')
return
time.sleep(EVAL_INTERVAL_SECS)
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_DATA", one_hot=True)
evaluate(mnist)
if __name__ == '__main__':
tf.app.run()三 运行代码之后遇到的大坑
当你兴高采烈地一行行敲完这三个代码,而且你还很确定自己基本了解了LeNet的结构以及在TensorFlow中该如何实现,想想以后就可以动手搭建自己的卷积网络还有点小兴奋。于是,你在Pycharm中Shift+Alt+F10开始运行自己的代码,结果你得到了下面的结果。
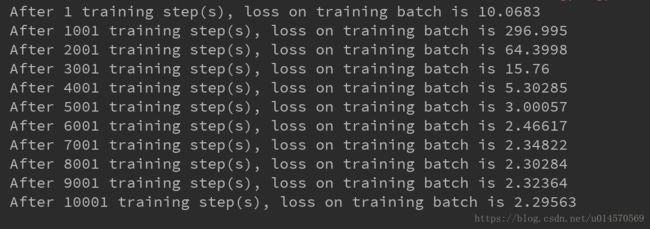
What???!!!这是什么鬼,损失函数这么大!!!
原因是书中对学习率设置的太高,只需将学习率调低即可
学习率:控制神经网络中参数更新的幅度,过大易导致结果在最优值两侧浮动,过小迭代次数过多
# lenet_train.py
LEARNING_RATE_BASE = 0.01修改之后再次运行起来,希望可以一切顺利,^_^
结果得到了下面的结果

What???!!!这是什么鬼,损失函数怎么还是比较大!!!
这个坑的具体原因我不太清楚,因为也是才接触。我的做法是将原书中代码的FC1层的正则化去掉,只在最后一层使用正则化。
# lenet_inference.py
# 定义第5层全连接层:输入3136×1 输出512×1
with tf.variable_scope('layer5-fc1'):
# 只有全连接层的权重需要加入正则化
fc1_weights = tf.get_variable('weight', [nodes, FC_SIZE],
initializer=tf.truncated_normal_initializer(stddev=0.1))
fc1_biases = tf.get_variable('bias', [FC_SIZE], initializer=tf.constant_initializer(0.1))
# 使用relu激活函数
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
# dropout避免过拟合:在训练过程中会随机将部分节点输出为0
if train: fc1 = tf.nn.dropout(fc1, 0.5)
# 定义第6层softmax层:输入512×1 输出10×1
with tf.variable_scope('layer6-fc2'):
# 只有全连接层的权重需要加入正则化
fc2_weights = tf.get_variable('weight', [FC_SIZE, NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2_biases = tf.get_variable('bias', [NUM_LABELS], initializer=tf.constant_initializer(0.1))
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc2_weights))
# 使用relu激活函数
logit = tf.matmul(fc1, fc2_weights) + fc2_biases运行结果如下:
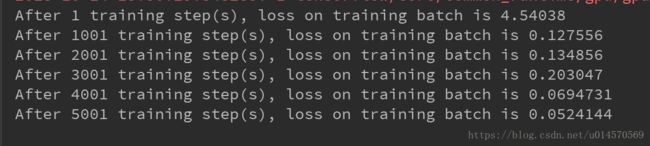
这样的结果才是正常的嘛?
如果有幸被哪位大牛看到这篇文章,请讲解一下为什么我只在最后一层使用正则化,运行结果才正常