汽车消费网用户投诉数据爬取及其数据处理,强烈建议观看时间部分数据处理!!!
汽车消费网用户投诉数据爬取及其数据处理,强烈建议观看时间部分数据处理!!!
汽车现在是不可或缺的一种生活交通工具了,在“车”时代的洪流下,对于汽车的需求量日益剧增。而对于汽车制造商来讲,既是一种机遇也是一项挑战,因为一种型号的汽车在出厂调试的时候不可能做到面面俱到。近年来汽车投诉问题也是汽车制造商面临的巨大的实际商业问题。基于这个问题,我们不妨来爬取一下用户们到底投诉的问题是什么,让我们当一把汽车制造商的市场调研员吧。(猴子又回来了hhh)
1、网址网站的观察
本次进军的网站是汽车消费网:
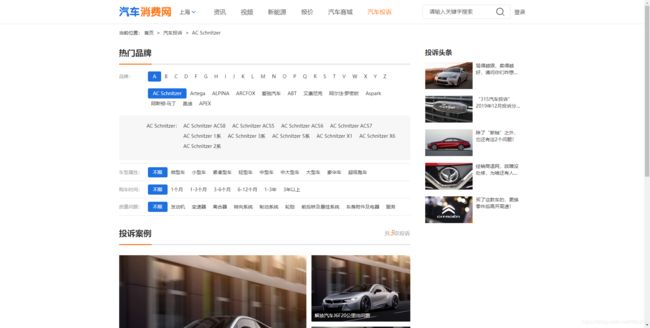
详情页(第一个为例)
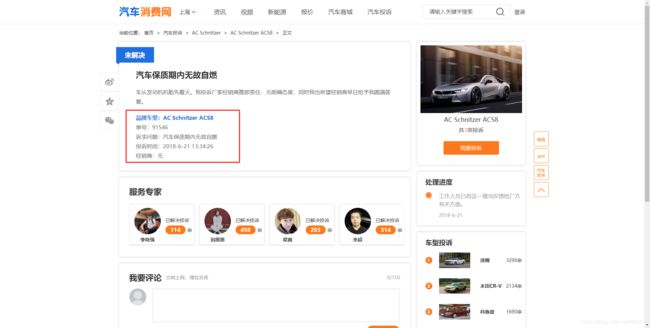
这次爬取的思路是
1、得到所有品牌详情页网址。
2、得到每个品牌的每个问题车俩的详情网址。
3、循环访问每个问题车俩的详情网址,爬取红框里的内容。
1、首先我们打开网页的检查设置:
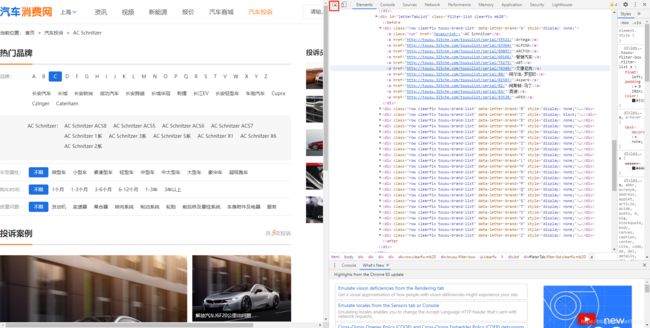
这里先用抓包工具(红框部分)点击网页上的品牌一栏,可以发现每个字母下都有每个品牌的详情网址(这就很舒服了)我们就可以用Xpath把所有品牌的网址拿下来。
2、得到每个品牌下每个问题汽车详情页
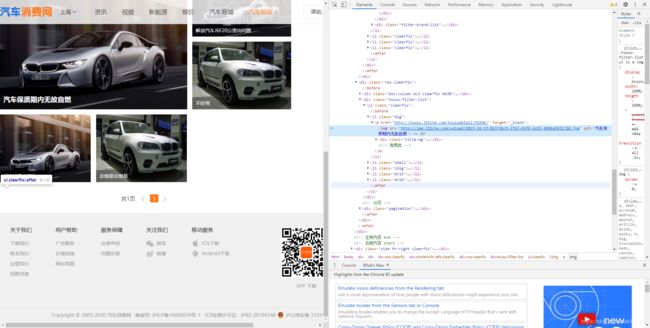
在对每个品牌的网址访问到以后,需要对每个问题车俩的网址得到,因为上面默认设置是车型不限,所以需要对每个问题车俩进行详情页链接的得到,然后进行翻页处理得到所有问题车俩的网页链接。在上面的截图中就可看出每个问题车俩的链接网址,用同样的Xpath解析就可以得到这个链接了。
那么这一步的难点在那里呢?
主要在以下两个方面:
1、
这种就是有很多页,需要一页一页的翻,得到所有的网址,而前面的“共***页”就是一个得到总页数的绝妙切入点。
2、
第2种就是这样,在这个品牌下没有问题车俩,我们在网页上看不到“共***页”也就无法定位,那么如果用通用的方法去写代码,就会出问题,所以考虑到用判断语句!!!
好!!!在得到所有问题车俩的网页链接后,就需要对字段进行爬取了!!!(加油!加油!)
继续分析。。。
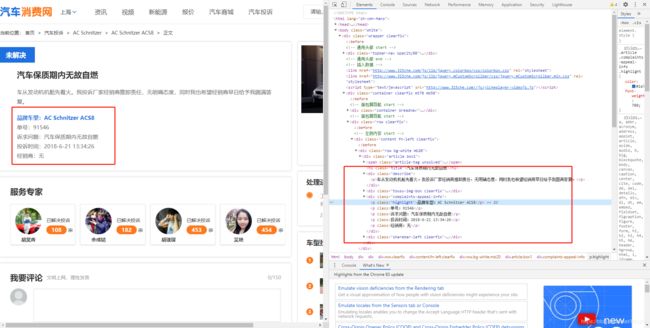
进入到一个问题车俩的详细页,按部就班的打开检查,利用抓包工具,很快我们就看到了我们需要的部分(hhhh,胜利在望了!!!),那么我们就可以去循环访问这些链接,然后得到数据啦!!!
2、万众瞩目的代码环节来啦!!!(快坐好!快坐好!)
import requests
from lxml import etree
import pandas as pd
import re
import time###导入库
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'Cookie': 'UM_distinctid=172451f1e3d5c0-087a218a188407-d373666-1fa400-172451f1e3e852; ip_che_curr_city=sh%2C9%2C0; Hm_lvt_59a0ccce5f22f1f9f19ce468f5250bca=1590299104; ip_che_city=sh%2C9%2C0; Hm_lpvt_59a0ccce5f22f1f9f19ce468f5250bca=1590302879; CNZZDATA30010794=cnzz_eid%3D860918270-1590292283-%26ntime%3D1590308523; CNZZDATA1257409530=427422905-1590296648-%7C1590307493'}
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'Cookie': 'UM_distinctid=172451f1e3d5c0-087a218a188407-d373666-1fa400-172451f1e3e852; ip_che_curr_city=sh%2C9%2C0; Hm_lvt_59a0ccce5f22f1f9f19ce468f5250bca=1590299104; ip_che_city=sh%2C9%2C0; Hm_lpvt_59a0ccce5f22f1f9f19ce468f5250bca=1590302879; CNZZDATA30010794=cnzz_eid%3D860918270-1590292283-%26ntime%3D1590308523; CNZZDATA1257409530=427422905-1590296648-%7C1590307493'}###设置请求头
url='http://tousu.315che.com/tousulist/serial/55467/'
res=requests.get(url,headers=headers)###访问主网址
res.encoding='utf8'###内容解码
ht=etree.HTML(res.text)###继续Xpath前的标准化操作
a=ht.xpath('//div[@class="row clearfix tousu-brand-list"]/a/@href')###得到每个品牌的链接
a[0]=url###因为主网站就是第一个品牌,所以需要将得到的第一个网址替换(原始得到的第一个不是网址)
urll=[]###用来装每个问题车辆的网址
for i in range(len(a)):
ress=requests.get(a[i],headers=headers)
ress.encoding='utf8'
htt=etree.HTML(ress.text)
page=''.join(htt.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[2]/div[3]/div/span/text()'))###得到页码
if page !='':###这就是判断语句了,如果得到的不是空,那么就爬取页码
page=re.search('共(\d+)页',page).group(1)###取出页码的数字
for j in range(1,int(page)+1):
resss=requests.get(a[i]+'/0/0/0/'+str(j)+'.htm',headers=headers)
resss.encoding='utf8'
httt=etree.HTML(resss.text)
urll=urll+httt.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[2]/div[2]/ul/li/a/@href')###得到所有问题车俩网址
time.sleep(2)###让机器歇一歇
print(i)
de={'网址':url}
det=pd.DataFrame(de)###得到网址
结果:

看起来非常可观阿,那就继续爬取有效字段吧
name=[]
ID=[]
question=[]
times=[]
dealer=[]
for m in range(len(det['网址'])):
ressss=requests.get(det['网址'][m],headers=headers)
ressss.encoding='utf8'
htttt=etree.HTML(ressss.text)
name.append(''.join(htttt.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div/div[3]/p[1]/text()')))
ID.append(''.join(htttt.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div/div[3]/p[2]/text()')))
question.append(''.join(htttt.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div/div[3]/p[3]/text()')))
times.append(''.join(htttt.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div/div[3]/p[4]/text()')))
dealer.append(''.join(htttt.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div/div[3]/p[5]/text()')))
time.sleep(1)
print(m)
da={'车型':name,'ID':ID,'问题':question,'时间':times,'经销商':dealer}
data=pd.DataFrame(da)
data
前面说那么多,代码就简单几行,轻轻松松解决问题啦!!让我们看看数据吧!

啊哦,数据似乎有杂音阿,那让我们来整容吧!!!
3、数据的处理,时间部分处理建议收藏!!!
首先我们要把,品牌车型:,单号:,诉求问题:,投诉时间:,经销商:这些东西删去。正则!!!
re.sub()
前面博文中说到,这是一个好东西阿,在处理字符串时不可谓不是利器。上代码!!!
for c in range(len(data['车型'])):###对车型进行清洗
data['车型'][c]=re.sub('品牌车型:','',data['车型'][c])
for I in range(len(data['ID'])):##对ID进行清洗
data['ID'][I]=re.sub('单号:','',data['ID'][I])
for q in range(len(data['问题'])):###对诉求进行清洗
data['问题'][q]=re.sub('诉求问题:','',data['问题'][q])
for t in range(len(data['时间'])):###对时间进行初步清洗
data['时间'][t]=re.sub('投诉时间:','',data['时间'][t])
for d in range(len(data['经销商'])):###对经销商进行清洗
data['经销商'][d]=re.sub('经销商:','',data['经销商'][d])
data=data[data['车型']!='']###去除空值
对于最后一行代码我要说明一下,因为博主的网不行,访问太快了,导致有的网页没有访问进去,所以得到的都是空的,我们要将这些空行删除!!!但如果各位大佬的网稳的话,直接忽略掉。。。
让我们来看看数据吧!
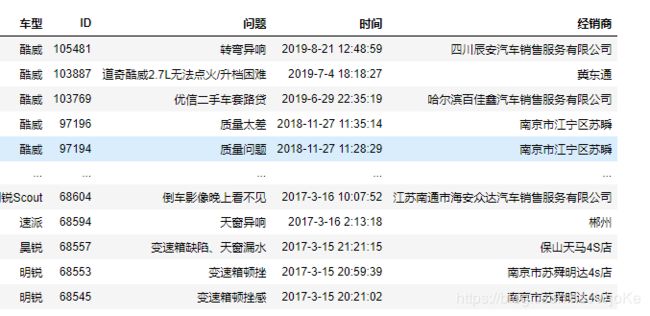
哇哦,干净!不对,好像少了点什么,对时间没有做处理。
害!时间这个处理可是把我整烦了,分析下来大致分为3个类型:
1、正常的24小时制的时间格式
2、使用12小时制的时间(也就是上午12小时,下午12小时,AM,PM之类的)
3、时间里面有韩文,日文之类的奇奇怪怪的东西。。。
那么我们的处理思路是什莫尼?统统变成24小时制!!!说干就干!!
对于AM,PM的上午的时间就简简单单的吧时间最后的AM删除,而下午的就把PM筛选出来,然后把小时的部分加上12,再把PM删除。对于韩文,日文的用正则直接替换。那就上代码吧!!!
import time###引入时间库
for i in range(len(data['时间'])):
data['时间'][i]=re.sub(u"[\uac00-\ud7ff]+",'',data['时间'][i])###将时间中的韩文乱码进行处理
data['时间'][i]=re.sub('\.\s','-',data['时间'][i])
for i in range(len(data['时间'])):###将时间转化为标准格式
if 'PM' in data['时间'][i]:
if int(re.match('.*?(\d+):',data['时间'][i]).group(1))==12:###先判断中午的时间避免24与0时重合
data['时间'][i]=data['时间'][i][:-2]###删去PM
a=time.strptime(data['时间'][i],'%b %d, %Y %H:%M:%S ')###转字符串为时间格式
data['时间'][i]=time.strftime('%Y-%m-%d %H:%M:%S',a)###改成想要的
else:
b=re.match('.*?,\s\d+\s',data['时间'][i]).group()+str(int(re.match('.*?(\d+):',data['时间'][i]).group(1))+12)+data['时间'][i][-9:]###找到小时,改造小时
data['时间'][i]=b[:-2]
a=time.strptime(data['时间'][i],'%b %d, %Y %H:%M:%S ')
data['时间'][i]=time.strftime('%Y-%m-%d %H:%M:%S',a)
if 'AM' in data['时间'][i]:
data['时间'][i]=data['时间'][i][:-2]
a=time.strptime(data['时间'][i],'%b %d, %Y %H:%M:%S ')
data['时间'][i]=time.strftime('%Y-%m-%d %H:%M:%S',a)
a=time.strptime(data['时间'][i],'%Y-%m-%d %H:%M:%S')
data['时间'][i]=time.strftime('%Y-%m-%d %H:%M:%S',a)
print(i)
在这里,可谓是把正则给用的淋漓尽致了,因为是时间是字符串形式,开始我想的是用数字的位置去定位小时,可是,时间前面的日期有一位有两位,例如2017-3-17和2017-12-7,他们的字符长度一样,但是所表示的实际位置不一样,前者的第5位是3,后者的第5位是1,这就不对了鸭!还好在小时部分有“:”可以作为判断将其拿出,用re.match()又只会得到第一个找出的结果,那么就把小时位置给定准了,接下来就水到渠成的写循环啦!!!
4、总结
爬取很简单,处理很复杂,多想办法,多去尝试。
遇到问题解决问题就好!