音频信号的自相关与增强自相关
最近在做一些有关音频分析工作,用到Audacity分析音频的频率及音高,频率部分不做重点,网上很多资料。音频信号的自相关一般用来提取音频的基音,可以用来区分浊音与清音等。主要的概念是通过自相关提取信号的固定周期。参考https://blog.csdn.net/wordwarwordwar/article/details/63253470。
这里采用audacity分析一段音频信号的标准自相关图。

增强自相关图:
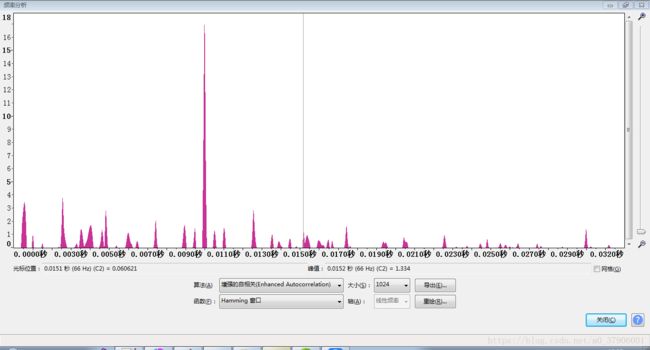
可以看出增强自相关的图像更能有效的反映出音频的基音。
这里贴出增强自相关的audacity的实现源码
/**********************************************************************
Audacity: A Digital Audio Editor
Spectrum.cpp
Dominic Mazzoni
*******************************************************************//*!
\file Spectrum.cpp
\brief Functions for computing Spectra.
*//*******************************************************************/
#include
#include "Spectrum.h"
#include "FFT.h"
#include "Experimental.h"
#include "SampleFormat.h"
bool ComputeSpectrum(const float * data, size_t width,
size_t windowSize,
double WXUNUSED(rate), float *output,
bool autocorrelation, int windowFunc)
{
if (width < windowSize)
return false;
if (!data || !output)
return true;
Floats processed{ windowSize };
for (size_t i = 0; i < windowSize; i++)
processed[i] = float(0.0);
auto half = windowSize / 2;
Floats in{ windowSize };
Floats out{ windowSize };
Floats out2{ windowSize };
size_t start = 0;
unsigned windows = 0;
while (start + windowSize <= width) {
for (size_t i = 0; i < windowSize; i++)
in[i] = data[start + i];
WindowFunc(windowFunc, windowSize, in.get());
if (autocorrelation) {
// Take FFT
RealFFT(windowSize, in.get(), out.get(), out2.get());
// Compute power
for (size_t i = 0; i < windowSize; i++)
in[i] = (out[i] * out[i]) + (out2[i] * out2[i]);
// Tolonen and Karjalainen recommend taking the cube root
// of the power, instead of the square root
for (size_t i = 0; i < windowSize; i++)
in[i] = powf(in[i], 1.0f / 3.0f);
// Take FFT
RealFFT(windowSize, in.get(), out.get(), out2.get());
}
else
PowerSpectrum(windowSize, in.get(), out.get());
// Take real part of result
for (size_t i = 0; i < half; i++)
processed[i] += out[i];
start += half;
windows++;
}
if (autocorrelation) {
// Peak Pruning as described by Tolonen and Karjalainen, 2000
/*
Combine most of the calculations in a single for loop.
It should be safe, as indexes refer only to current and previous elements,
that have already been clipped, etc...
*/
for (size_t i = 0; i < half; i++) {
// Clip at zero, copy to temp array
if (processed[i] < 0.0)
processed[i] = float(0.0);
out[i] = processed[i];
// Subtract a time-doubled signal (linearly interp.) from the original
// (clipped) signal
if ((i % 2) == 0)
processed[i] -= out[i / 2];
else
processed[i] -= ((out[i / 2] + out[i / 2 + 1]) / 2);
// Clip at zero again
if (processed[i] < 0.0)
processed[i] = float(0.0);
}
// Reverse and scale
for (size_t i = 0; i < half; i++)
in[i] = processed[i] / (windowSize / 4);
for (size_t i = 0; i < half; i++)
processed[half - 1 - i] = in[i];
} else {
// Convert to decibels
// But do it safely; -Inf is nobody's friend
for (size_t i = 0; i < half; i++){
float temp=(processed[i] / windowSize / windows);
if (temp > 0.0)
processed[i] = 10 * log10(temp);
else
processed[i] = 0;
}
}
for(size_t i = 0; i < half; i++)
output[i] = processed[i];
return true;
}
python语言实现
"""Perform enhanced autocorrelation on a wave file.
Based very loosely on https://bitbucket.org/yeisoneng/python-eac
which is based on Audacity's implementation. This version uses
Numpy features to significantly speed up processing."""
from __future__ import division
import numpy as np
from numpy.fft.fftpack import fft, rfft
from scipy.interpolate import interp1d
from scipy.signal import argrelextrema
def eac(sig, winsize=512, rate=44100):
"""Return the dominant frequency in a signal."""
s = np.reshape(sig[:len(sig)//winsize*winsize], (-1, winsize))
s = np.multiply(s, np.hanning(winsize))
f = fft(s)
p = (f.real**2 + f.imag**2)**(1/3)
f = rfft(p).real
q = f.sum(0)/s.shape[1]
q[q < 0] = 0
intpf = interp1d(np.arange(winsize//2), q[:winsize//2])
intp = intpf(np.linspace(0, winsize//2-1, winsize))
qs = q[:winsize//2] - intp[:winsize//2]
qs[qs < 0] = 0
return rate/qs.argmax()增强自相关原论文链接:https://download.csdn.net/download/m0_37906001/10676091