计算机视觉领域经验分享(面向研一初学者)
深度学习入门:
第一件事:导论!万能的B站上有很多,建议看一下吴恩达的机器学习,大致过一两遍了解个大概就行了,集中时间看,一周之内就足够了。还有就是像python语言和opencv这类计算机视觉里常用的东西不需要太刻意去单独学习,用的时候单独敲几个小demo看看效果就行了。主要的学习过程在代码阅读过程中和不懂就百度的过程中慢慢的就会了。
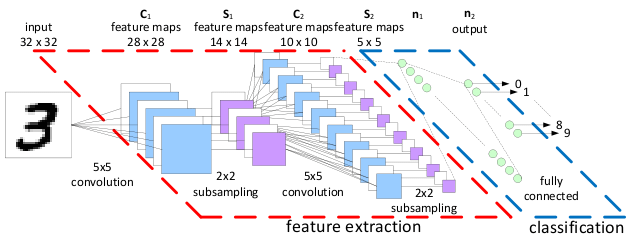
第二件事:动手!万能的mnist手写数字数据集,不管你的电脑是什么样的一种配置,都可以完美运行。mnist数据集的使用是深度学习技术中的Hello world!可能只有短短几行代码,多画图分析每一步的计算过程。不管是最开始的入门,还是后期实验需要某些零件(如LSTM,注意力机制等)都可以在Github上找到其实现源码,而且要求等运行环境简单。大致跑通,就可以对代码进行移植。

https://github.com/soloice/mnist-bn/blob/master/mnist_bn.py
https://github.com/zonghua94/mnist
https://github.com/2012013382/C3D-Tensorflow-slim/blob/master/C3D_model.py
https://github.com/rudylyh/attention_mnist/blob/master/attention_mnist.py
第三件事:环境。深度学习新手入门的鸿沟之一——环境配置,一定要学会自己搭环境,在初期可能是一个比较痛苦的一个过程,可能需要重复很多次才能成功。但是能熟练配置环境之后,就再也不需要担心环境之类的问题了。进而能专心在自己的代码上。环境配置是基本功,建议初学者一开始就学会安装使用ubuntu系统,而不是装虚拟机,虚拟机经常容易死机,受不了了再转向ubuntu,是一个比较大的弯路。深度学习新手入门的鸿沟之二——就是感觉基本计算方式、正反向传播计算公式很复杂,给自己灌输一种很难的感觉。如果不是想要开发一种新的神经网络计算模式的话,建议了解大概过程,不求甚解就可以了。每个计算过程了解其作用即可,设计自己的网络结构就像是搭积木,我们并不太用关心积木内部是什么分子结构,跑起来好用就行。



第四件事:深度学习框架。建议初学者一开始尝试一些阅读起来比较简洁的框架语言,如Tensorflow-slim、Keras等,都是高度封装的框架语言,易于初学者阅读和编写。而像原生Tensorflow语言编写的网络代码一般比较麻烦,不利于阅读和理解。在入门之后建议学习使用Pytorch,个人之前使用的Tensorflow-slim和Keras,感觉方便便捷。但是发现有很多源码是Pytorch版本的,不了解的话移植起来比较麻烦。不同的框架语言之间的张量是以不同的方式封装的,不能直接移植,而Tensorflow-slim和tensorflow原生代码是可以共同使用的。大家可以根据需要自己选择。

https://github.com/soloice/mnist-bn/blob/master/mnist_bn.py
https://github.com/bubbliiiing/retinanet-keras/blob/master/nets/resnet.py
https://blog.csdn.net/weixin_44791964/article/details/104327456
剩下的事:多跑源码多实践,阅读源码远比阅读论文有趣的多,论文的真正灵魂在代码中。一篇论文的全部代码可能是一个工程文件,可以在不懂的步骤下面打印输出,分析每一条代码的具体作用。论文是代码的说明书,搞懂之后就可以把别人的东西转化为自己实验方法的一部分。
论文方面:
先看综述性论文:
大体掌握该研究领域的历史进展,了解哪些方法别人已经提出来了,了解目前面临哪些主要问题。大致浏览通读即可。
再看最近几年的学术性论文:
这些论文一般是针对一些比较明确的目的,而提出自己的方法并加以介绍。
这些论文中的大多数也是不建议精读的,例如:技术比较老的方法,效果一般的方法,比较牵强的方法,看不懂的纯数学公式的方法。这些论文大多数只是在论文撰写阶段引用在引言或者相关工作中的,并不需要花费太多的时间,总结前人工作的时候一般只读这些论文的摘要就可以用一两句话来进行概括。
主要的精力还是要花费在近两年的目标论文上,例如:这个论文中的方法和我想要实现的代码功能有一定的关联,比如要参考别人神经网络的结构和实现思路等,尤其是实现代码开源的论文要精读,如果论文看完后找到源码并跑通再去对照论文和源码一起看,才能完全get到作者的思路,总结部分看一下作者的展望,还存在哪些不足,这些不足都可以为自己提供一个需要解决的问题。如果自己能够解决,这都将会是自己论文撰写中的一个点。
大多数工作都是建立在前人工作的基础之上,完全原创的工作一般都是科研巨巨。所以我们要做的其实大多数建立在前人的基础上,在他们的方法上进行拓展并解决前人所遗留的问题。
像研究院,每天要交日报,一定不要为了写上一句:今天精读了某论文而去漫无目的阅读,那样只会效率低下,时间长了也会丧失兴趣。要对一遍文章有一定的分辨力:能不能从中get到新东西从而受到启发,这篇论文中的方法的目的和依据是什么,能不能解决自己课题要解决的问题。如果都不能,那么看看摘要就可以了。一定要有针对性的阅读论文和源码,每天get一点点,长期的积累都会表现在实验效果上。
关于深度学习相关实验经验:
第一件事:观察。观察所要解决的具体问题的本质是什么。肉眼如何去辨识?
 ->
->
深度学习算法大多是针对某个数据集去专门的解决一类问题。虽然计算机看到的东西和我们眼睛看到的东西并不一样,但是过去的实验经历告诉我:只有我们看的清楚的东西,计算机才能看清;我们看不清的事物,计算机也同样辨识力比较弱。这就是为什么针对一些数据集,一定要有图像预处理层,只有将数据集处理的使我们看的更加清楚的信息,计算机才会更有辨识力。虽然某些情况下,分辨率高,并不一定效果好,但前提是在低分辨率的情况下,我们人也能看清楚,否则神经网络也是无法有效进行特征提取的。
https://blog.csdn.net/luolan9611/article/details/82804248
第二件事:思路。如何让神经网络get到问题的本质。如何用代码去辨识?
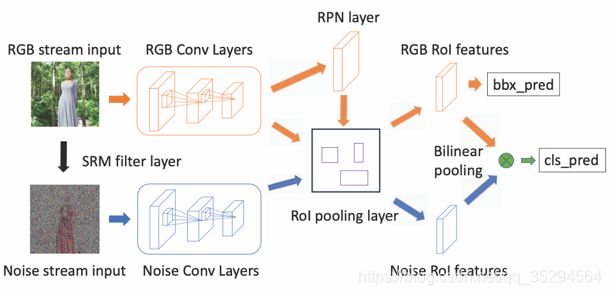
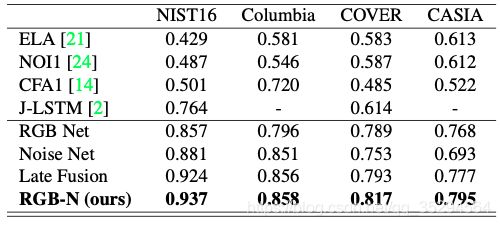
分析解决具体问题所需要的大致流程,并初步画出具体的方法步骤,初步设计网络结构。结合自己的思路,参考别人的代码原理,设计出自己的网络。因为不可能一下子就设计出效果很好的网络结构,可能需要多考虑一些设计思路,画出多个实现版本。创新一定是要猜的,然后用实验去论证。就像相对论提出之前是不可能用当时的任何公式推理出来的,虽然并远远不能相提并论,但道理都是一样的。要大胆的去猜测,最好是有一定依据的猜测,大不了只是一次失败的实验,从灯泡的起源我们知道只要坚持不懈,排除法就一定能起作用。
第三件事:实现。这一步就是拿一堆零件按照自己的思路和设计的算法结构将“小车”组装并能够跑起来的过程,100个人就有100种组装思路。
具体的代码实现可以基于一些与自己要实现的功能相近的小demo上进行代码改写和扩充,或者是在别人的工程代码的基础之上进行改造。因为深度学习代码一般主要为:神经网络结构的搭建、输入数据的处理、Loss函数的计算方案。因此没有很大必要从0开始编写,只需要在别人代码的基础之上对以上三部分进行改造,将自己的思路表现在代码中,最后调通代码,训练测试,验证自己想法的有效性。通常,不可能一开始就取得较好的结果,需要根据测试结果,不断的调整实验代码,使测试结果往好的方向发展。






参考文献:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8578214