数据挖掘中的模式发现(七)GSP算法、SPADE算法、PrefixSpan算法
这前两个算法真是出人意料地好理解
GSP算法
GSP算法是AprioriAll算法的扩展算法,其算法的执行过程和AprioriAll类似。
其核心思想是:在每一次扫描(pass)数据库时,利用上一次扫描时产生的大序列生成候选序列,并在扫描的同时计算它们的支持度(support),满足支持度的候选序列作为下次扫描的大序列。第1次扫描时,长度为1的频繁序列模式作为初始的大1—序列。
接下来会演示一下GSP如何产生候选集的。
GSP算法最大的特点就在于,GSP引入了时间约束、滑动时间窗和分类层次技术,增加了扫描的约束条件,有效地减少了需要扫描的候选序列的数量,同时还克服了基本序列模型的局限性,更切合实际,减少多余的无用模式的产生。
另外GSP利用哈希树来存储候选序列,减小了需要扫描的序列数量,同时对数据序列的表示方法进行转换,这样就可以有效地发现一个侯选项是否是数据序列的子序列。
但是这些方法都不算是GSP的核心思想,只是一些剪枝的优化而已,与其他很多算法的方式极其类似,无论是ACM-ICPC还是其他机器学习、深度学习的算法都有类似的优化,所以不再赘述。
演示
我们现在有如下的数据库,并设置最小支持度min_support = 2
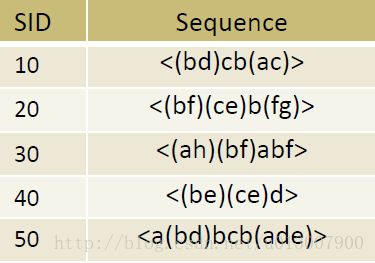
我们先进行第一次扫描。
得到如下的序列

这全部的就是候选集,然后没有打叉的就是序列模式。这里的思想和之前讲过的Apriori算法完全一样。
现在我们来产生长度为2的候选集,只是候选集而已。

我们来稍微解释一下,如 <aa> ,这个的意思就是先发生了一次a再发生了一次a,而不是同时发生的。每个a都是一个元素。

这里就不存在类似于 <(aa)> 这样的序列了,这里是产生只含有一个元素的序列。
我们这里总共产生了候选集 6×6+6×5÷2=51 个。
如果没有使用剪枝,而是直接使用类似于广度优先搜索(bfs)的算法生成,则会有 8×8+8×7÷2=92 个。
然后再进行筛选,直到不能进行了为止。
哈希树
使用数据结构对序列进行存储能够方便管理,节约空间。就有一些类似蛤夫曼树压缩编码那样。
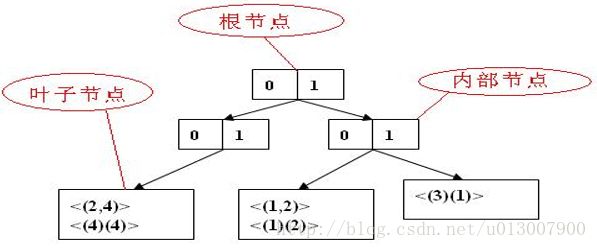
GSP采用哈希树存储候选序列模式。哈希树的节点分为三类:
- 根节点;
- 内部节点;
- 叶子节点。
根节点和内部节点中存放的是一个哈希表,每个哈希表项指向其它的节点。而叶子节点内存放的是一组候选序列模式。
代码请见
SPADE算法
SPADE算法依旧使用传统的先验性质,即连接步+剪枝步的经典组合,思想跟GSP大致相同,但是引入了垂直列表数据库。
SPADE算法寻找1-序列和2-序列频繁项集方法跟GSP完全形同,在之后的3-候选集及之后的频繁项计算中,采取了一种“作弊”的办法获得候选集,该办法套用了三种屡试不爽的公式,如下:
- 如果诸如成员PA,PD这样的形式出现在2频繁项集中,则能推导出PBD这样的三成员元素。
- 如果出现诸如PB,P->A这样的形式出现在2频繁项集中,则能推导出PB->A这样的三成员元素。
- 如果出现诸如P->A,P->F这样的形式出现在2频繁项集中,则能推导出P->AF或P->A->F或P->F->A这样的三成员元素。
同时还要注意,如果想要A和F得出AF,那么A发生的序列号要与F发生的序列号相同,而且A的时间序列号要小于F的时间序列号。想相反的情况也是一样的,要得出FA,则要F的时间序列号要小于A的时间序列号。
演示
现有如下的数据库

其中时间序列号(或称为元素序列号)表示在一个序列中排序的位置,因为越大的排序在越后面。
在本例中AB,AF是两个频繁的2成员项,那么有可能存在且仅存在ABF这样的3成员频繁项,经过10次计算遍历了一遍data发现ABF确实是频繁的。
然后这样也是一点一点做直到没有办法。
PrefixSpan
算法思想:采用分治的思想,不断产生序列数据库的多个更小的投影数据库,然后在各个投影数据库上进行序列模式挖掘。
相关定义
前缀:设每个元素中的所有项目按照字典序排列。给定序列 α=<e1e2…en> , β=<e′1e′2…e′m>(m≤n) ,如果 e′i=ei(i≤m−1),e′m⊆em ,并且 (em−e′m) 中的项目均在 e′m 中项目的后面, 则称 β 是 α 的前缀。
例:序列 <(ab)> 是序列 <(abd)(acd)> 的一个前缀;序列 <(ad)> 则不是。
投影:给定序列 α 和 β ,如果 β 是 α 的子序列,则 α 关于 β 的投影 α′ 必须满足: β 是 α′ 的前缀, α′ 是 α 的满足上述条件的最长子序列。
例:对于序列 α=<(ab)(acd)> ,其子序列 β=<(b)> 的投影是 α′=<(b)(acd)> ; <(ab)> 的投影是原序列 <(ab)(acd)> 。
后缀:序列 α 关于子序列 β=<e1e2…em−1e′m> 的投影为 α′=<e1e2…en>(n≥m) ,则序列 α 关于子序列 β 的后缀为 <e′′mem+1…en> , 其中 e′′m=(em−e′m)
例:对于序列 <(ab)(acd)> ,其子序列 <(b)> 的投影是 <(b)(acd)> ,则 <(ab)(acd)> 对于 <(b)> 的后缀为 <(acd)> 。
投影数据库:设 α 为序列数据库S中的一个序列模式,则 α 的投影数据库为S中所有以 α 为前缀的序列相对于 α 的后缀,记为 S|α 。
投影数据库中的支持度:设 α 为序列数据库S中的一个序列,序列 β 以 α 为前缀,则 β 在 α 的投影数据库 S|α 中的支持度为 S|α 中满足条件 β⊆α.γ 的序列 γ 的个数。
演示

1-序列都是一如既往地计算。
然后就根据每一个1-序列得出对应的投影数据库
再结合每一个投影数据库中序列的前缀,从而得到2-序列。
Clospan
用来计算闭合序列模式的方法,大家可以看看论文。
闭合序列模式 s : 不存在一个超序列 s′ ,其中 s′כs ,而且 s′ 和 s 有着相同的支持度。
其中 <abcd> 和 <abcde> 是闭合序列模式。
用两种算法Backward Subpattern和Backward Superpattern来合并数据库,实现Clospan。
论文:Greatly enhances efficiency (Yan, et al., SDM’03)
如果大家看到MathJax的公式最后都有一个奇怪的竖线,应该是CSDN自己的解析出现了问题,看起来确实挺奇怪的。