如何用python实现剔除列表中相同的元素
python实现剔除列表中相同的元素
问题描述:采用python实现剔除列表中相同的元素。
顾名思义,比如说有一列表listVal = [12, 34, 23, 12, 23, 34, 15],经过剔除之后,应该只剩下listVal = [15]。
起初,我的思路是这样的:遍历每一个元素a(称之为大的遍历),记元素a的位序为LocA,对于每一个元素再做遍历(小的遍历),小的遍历中应该是这样执行的:在LocA直到列表结尾查找跟a相同的位序SameLocA,如果找到了,则删除找到的SameLocA对应的元素跟a;如果没找到,则遍历下一个元素;一直这样做下去。下面即为代码:
listVal = [12, 34, 23, 12, 23, 34, 15]
print '原先列表中的元素; ', listVal
i = 0
while i < len(listVal)-1:
if listVal[i] in listVal[i+1:len(listVal)]:
# 说明一定有相同的元素
pos = listVal.index(listVal[i], i+1, len(listVal))
del listVal[i]
del listVal[pos-1]
i = i
else:
i += 1
print '剔除相同元素之后的列表: ', listVal然后运行结果如下:
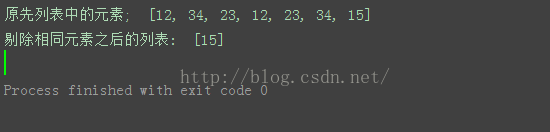
感觉上像是对了,有点小兴,然后,随意换了一组测试数据listVal = [12, 34,23, 12, 32, 34, 12, 34, 56, 56, 56, 56, 23, 1, 1, 1, 1, 1, 0],竟然不对劲了,如下图:

研究了一下代码,对代码加断点调试,才发现:原因在于每次找到的相同的数据元素只能找到第一个。所以就换了想法:应该是需要找到LocA之后的所有的与a相同的元素,并将其删除。这种想法外表上看没啥问题,但实现起来,代码却有点令人费解:
listVal = [12, 34, 23, 12, 32, 34, 12, 34, 56, 56, 56, 56, 23, 1, 1, 1, 1, 1, 0]
print '原先列表中的元素; ', listVal
i = 0
while i < len(listVal)-1:
if listVal[i] in listVal[i+1:len(listVal)]:
# 说明一定有相同的元素
count = listVal[i+1:len(listVal)].count(listVal[i])
j = 0
start = i+1
while j < count:
pos = listVal.index(listVal[i], start, len(listVal))
start += pos
del listVal[pos-1]
j += 1
del listVal[i]
#del listVal[pos-1] # 还有bug:原因在于每次找到的相同的数据元素只能找到第一个.---这就是问题所在
i = i
else:
i += 1
print '剔除相同元素之后的列表: ', listVal
结果发现,老是出现数组下标越界,一直都想不通这是为什么,断点调试了之后还是不能发现。。。直到吃饭时间还是不能想出来,没办法,先填饱肚子先。于是一边走在路上,一边在想这个问题:觉得大的“框架”没啥错,问题出在哪里呢,后来在拿着外卖回来的路上,脑袋一铮亮,终于想明白了几点:
一:是len在每一次del之后是会使得列表中的元素个数以及位序发生重组,所以总的遍历过程以及之后的i需要进行相应的变化
二:没必要去找LocA之后的切片列表中是否存在跟a相同的元素,而可以直接的在总的列表中查找a,获取总的列表跟a相同的元素的个数count,然后只需要进行count次循环的一次del操作,因为每次进行del操作之后,列表将进行重组,只需要赶在i的位序发生变化之前找到与a相同的元素的位置,然后进行del即可。
一下是我想了许久的代码,觉得很有意思,并不是说这个问题有多高级,也不是说这个问题有多难,代码有高级,而是我觉得这个思考的过程让我觉得很是刺激,兴奋,我喜欢这样的体验,哪怕是花很长时间。
# 终于正确的实现了
# listVal = [12, 34, 23, 1, 12, 32, 34, 1, 1, 12]
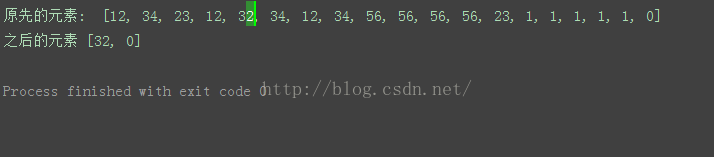
listVal = [12, 34, 23, 12, 32, 34, 12, 34, 56, 56, 56, 56, 23, 1, 1, 1, 1, 1, 0]
#listVal = [12, 34, 23, 12, 23, 34, 15]
print '原先的元素: ', listVal
i = 0
count = 0
while i < len(listVal):
value = listVal[i]
count = listVal[0:len(listVal)].count(value)
#print count
if 1 < count:
j = 0
while j < count:
#这里就是容易出错的地方:虽然len以及知道会发生动态变化,但差点就忽略了del也会让列表中元素位序发生变化。后来
#吃饭的路上一直都在想。。。。打个外卖回来的路上竟然想到了,嘻嘻。。。。
del listVal[listVal.index(value)]
j += 1
#这里也是关键:因为一旦删了元素a的位序LocA就会立马发生变化,当当前元素a被删了时候,
# 需要将其位序赋值给下一个元素b以保证b为当前列表中的LocA即 i=i;否则就代表压根没有相同的元素,则 i+=1 #
# 即进行下一个元素的操作
i = i
else:
i += 1
print '之后的元素', listVal
运行结果如下图:
以上还涉及列表的索引,分割等操作,就不再啰嗦了,自己可以百度或者上python教程看看。
欢迎诸位提出评论!