基于RFM模型对某平台客户运营价值分析的项目案例
一、需求
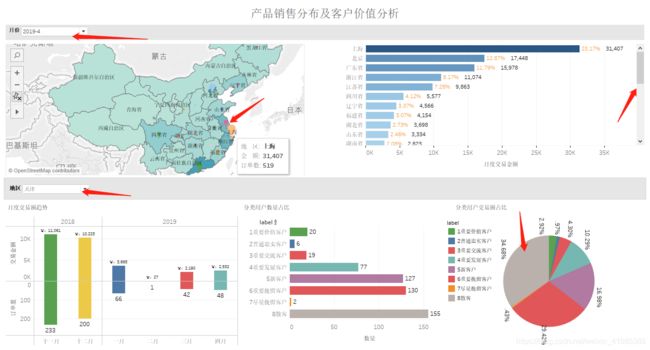
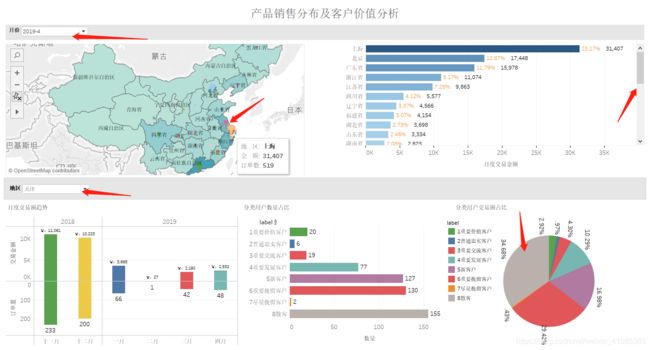
1.根据某*电商平台的某*店铺历史交易数据进行整体的统计分析,按月统计销售数量及交易金额的变化趋势,统计各省份的销售情况,及销售环比情况。
2.根据某*电商平台的某*店铺历史交易数据进行历史客户价值分析。考虑用户对店铺的贡献,复购率、对品牌的忠诚等因素,为用户贴标签,客户更加精准地进行划分,从而实现针对性的营销运营,降低营销成本,同时提高营销效果。
工具:mysql+python+tableau
可视化截图
二、获取源数据
数据存在公司数据库,在做数据分析测试阶段,我们提取2018.11-2019.5的数据集用于做前期的数据分析。
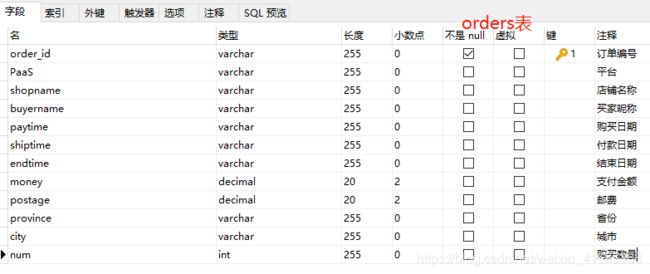
数据字段及解释如下:orders(订单明细)表和failedorder(交易未达成)表。

#pandas库连接mysql获取数据
import pandas as pd
import pymysql
from sqlalchemy import create_engine
# 初始化数据库连接,使用pymysql模块
# MySQL的用户:root, 密码:123456, 端口:3306,数据库:lean2
con = create_engine('mysql+pymysql://root:123456@localhost:3306/rfm')
sql01 = '''select * from orders;'''
sql02 = '''select * from failedorder;'''
# read_sql_query的两个参数: sql语句, 数据库连接
orders = pd.read_sql_query(sql01, con = con)
failedorder = pd.read_sql_query(sql02,con=con)
print(orders.shape,failedorder.shape) #-->(28809, 12) (1040, 2)三、数据清洗(工具:python)
1、合并表
df=orders.merge(failedorder,how='left',on="order_id") #表合并
#合并后failed_state字段如果为空,则表示交易成功
df['failed_state'] = df['failed_state'].fillna("交易成功")
display(df.head())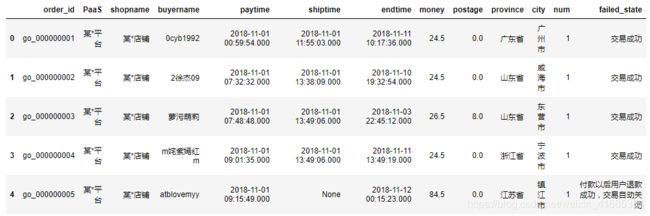
2、数据过滤,删除交易失败的数据集
df = df[df['failed_state']== "交易成功"] #布尔过滤
# df = df.query("failed_state == '交易成功'") #query()过滤
display(df.shape) #(27769, 13)3、获取统计信息,初步发现异常值
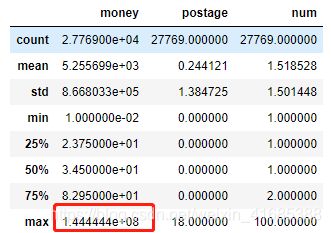
display(df.describe()) #获取统计信息
display(df.info()) #发现缺失值
display(df[['money','postage','num']].describe()) #数值型变量单独统计
display(df[df.duplicated(subset=['order_id'],keep='first')])#发现重复值
4、查看异常值并处理
df = df.drop_duplicates(subset=['order_id'],keep='first',inplace=False) #删除重复值
display(df[df["paytime"].isnull()]) #查看paytime为空的行信息
df["paytime"] = df["paytime"].fillna('2018-11-03 10:24:06.000')
display(df.loc[28808:28809])
display(df[df["money"].isnull()]) #查看money为空的行信息,无,已被连带删除
display(df[df["city"].isnull()]) #查看city为空的行信息
df["city"]=df["city"].fillna("未知")
display(df[df["city"]=="未知"])![]()
5、离群值检验与处理
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt #最常用的绘图库
mpl.rcParams["font.family"]="SimHei" #使用支持的黑体中文字体
mpl.rcParams["axes.unicode_minus"]=False # 用来正常显示负号 "-"
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
# % matplotlib inline #jupyter中用于直接嵌入图表,不用plt.show()
import warnings
warnings.filterwarnings("ignore") #用于排除警告
#画布
figure = plt.figure(num="箱型图",figsize=(8,3),dpi=80,facecolor="LightGray",edgecolor="blue",frameon=True)
# 数据
money = df["money"]
num = df["num"]
axes1= plt.subplot(1,2,1)
plt.title("money箱型图")
plt.xlabel("money")
plt.ylabel("value")
axes1.boxplot(money,sym="o",whis=1.5)
axes2= plt.subplot(1,2,2)
plt.title("num箱型图")
plt.xlabel("num")
plt.ylabel("value")
axes2.boxplot(num,sym="o",whis=1.5)
plt.show()
display(df[df["money"]==df["money"].max()])
df = df.drop(28796, inplace=False, axis=0) #删除#在看图
figure = plt.figure(num="箱型图",figsize=(8,3),dpi=80,facecolor="LightGray",edgecolor="blue",frameon=True)
# 数据
money = df["money"]
axes1= plt.subplot(1,2,1)
plt.title("money箱型图")
plt.xlabel("money")
plt.ylabel("value")
axes1.boxplot(money,sym="o",whis=1.5)
plt.show()
display(df[df["money"]>1000])
# 查看数据,发现交易数量也比较多,所以属于正常值,不再做数据处理,实际工作中还可以咨询相关业务员人员查验数据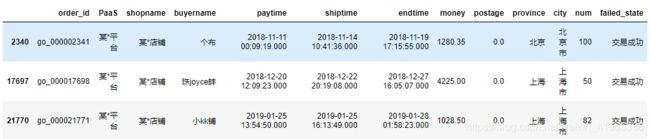
6、保存清洗后的数据
#保存清洗后的数据
import pandas as pd
import pymysql
from sqlalchemy import create_engine
# 初始化数据库连接,使用pymysql模块
# MySQL的用户:root, 密码:123456, 端口:3306,数据库:lean2
con = create_engine('mysql+pymysql://root:123456@localhost:3306/rfm')
#直接写入数据-->mydf-->mydf表会自动创建
# 将新建的DataFrame储存为MySQL中的数据表,储存index列
df.to_sql('orders_new', con, index=True)
print('Read from and write to Mysql table successfully!')四、建立用户标签的RFM模型
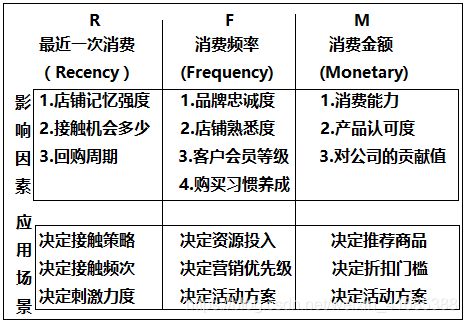
1.什么是RFM模型?
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。
该模型通过一个客户的近期购买行为R、购买的总体频次(F)以及消费金额(M)三项指标来描述该客户的价值状况,把客户更加精准地进行划分,从而实现针对性的营销,降低营销成本,同时提高营销效果。
详细来说,R指的是客户最后一次下单时间距离今天多少天了,该指标与客户的复购和流失直接相关。F指标指的是客户的下单频次,即客户在某个时间段内共消费了多少次,该指标用于衡量客户消费的活跃度。M指标是客户在该时间段内共消费了多少钱,该指标用于反应客户对于公司的贡献值。
RFM模型给每一个用户进行分层。这里我们需要建立一个评判标准,由于RFM模型本身就是需要根据不同场景和业务需求来建立的,因此这个分层标准,也是需要我们沟通业务后,得到最后的分层标准。
2、特征选取
从模型所需字段来看,我们只需要用户名称、交易金额两个字段即可,但考虑到地域分布,所以把地区相关的字段也加入,其次我们说R是最近一次购买距离现在多少天,所日期字段需要进行处理。
import pandas as pd
import pymysql
from sqlalchemy import create_engine
# 初始化数据库连接,使用pymysql模块
# MySQL的用户:root, 密码:123456, 端口:3306,数据库:lean2
con = create_engine('mysql+pymysql://root:131129@localhost:3306/rfm')
sql = '''select buyername,shiptime,money,province,city from orders_new;'''
# read_sql_query的两个参数: sql语句, 数据库连接
df = pd.read_sql_query(sql, con = con)
display(df.head())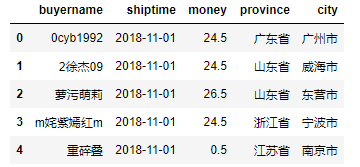
#由于训练数据集固定的原因,先假定今天为2019年6月1日
df["day_s"]=(pd.to_datetime("2019/6/1") - pd.to_datetime(df['shiptime'],errors='coerce')).dt.days
display(df.tail())
3、特征值转化
每个用户最近一次购买到今天的天数R,每个用户购买的总体频率(F)以及消费金额(M)
group_df = df[["buyername",'province','city','money','day_s']].groupby(["buyername",'province','city']).agg({"day_s":"min","money":["count","sum"]})
group_df.head()
group_df.columns = ["R","F","M"]
display(group_df[group_df["F"]>5])
4、客户分类
display(group_df.describe()) #查看三特征变量的统计信息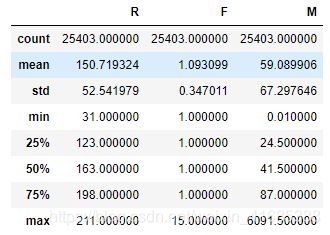
如果以上三个维度将数据划分为5个数据等级,这样就能够细分出5x5x5=125类用户,再根据每类用户精准营销……显然不可能为125类用户量体定制营销策略。实际运用上,我们把每个维度划分为2个数据等级(按照均值/中位数划分),这样在3个维度上我们依然得到了8组用户,基本达到我们的需求。优质客户等级用1表示,易流失、消费频次低、消费金额少用0表示
RFM模型分析
- 重要价值客户(111):最近消费时间近、消费频次和消费金额都很高。
- 普通忠实客户(110):最近消费时间较近、消费频次高,但消费金额不高。
- 重要交流客户(011):最近消费时间较远,但消费频次和金额都很高,说明这是个一段时间没来的忠诚客户,我们需要主动和他保持联系。
- 重要发展客户(101):最近消费时间较近、消费金额高,但频次不高,忠诚度不高,很有潜力的用户,必须重点发展。
- 新客户(100):最近消费时间较近,但消费频次和金额都不高。
- 重要挽留客户(001):最近消费时间较远、消费频次不高,但消费金额高的用户,可能是将要流失或者已经要流失的用户,应当极力挽留措施。
- 尽量挽留客户(010):最近消费时间较远、消费频次高,消费金额低的用户,原来的普通忠实客户,可能即将要流失或者已经流水,普通公司还得靠这群人支撑。这层级的用户多,那么就要考虑产品自身的因素了。
- 散客(000):最近消费时间较远、消费频次不高,消费金额也不高的用户。
这里我们按照中位数划分,中位数划分的好处在于受离群点的影响比均值更小。
#计算每个维度的中位数,按照中位数划分
R_median= group_df.median()["R"]
F_median= group_df.median()["F"]
M_median= group_df.median()["M"]
display(R_median,F_median,M_median)# 客户分类
#注意时间天数是越小越好。
def func1(x):
if xF_median:
return 1
else:
return 0
def func3(x):
if x>M_median:
return 1
else:
return 0
group_df["R_median"] = group_df["R"].apply(func1)
group_df["F_median"] = group_df["F"].apply(func2)
group_df["M_median"] = group_df["M"].apply(func3)
display(group_df.sample(10)) 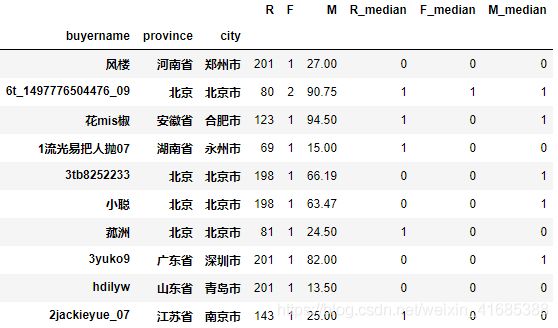
5、客户贴标签
#用户贴标签
def fun_abel(x):
if x.iloc[0]==1 and x.iloc[1]==1 and x.iloc[2]== 1:
return "1重要价值客户"
elif x.iloc[0]==1 and x.iloc[1]==1 and x.iloc[2]== 0:
return "2普通忠实客户"
elif x.iloc[0]==0 and x.iloc[1]==1 and x.iloc[2]== 1:
return "3重要交流客户"
elif x.iloc[0]==1 and x.iloc[1]==0 and x.iloc[2]== 1:
return "4重要发展客户"
elif x.iloc[0]==1 and x.iloc[1]==0 and x.iloc[2]== 0:
return "5新客户"
elif x.iloc[0]==0 and x.iloc[1]==0 and x.iloc[2]== 1:
return "6重要挽留客户"
elif x.iloc[0]==0 and x.iloc[1]==1 and x.iloc[2]== 0:
return "7尽量挽留客户"
elif x.iloc[0]==0 and x.iloc[1]==0 and x.iloc[2]== 0:
return "8散客"
group_df["label"]=group_df[['R_median','F_median','M_median']].apply(fun_abel,axis=1)
display(group_df.head())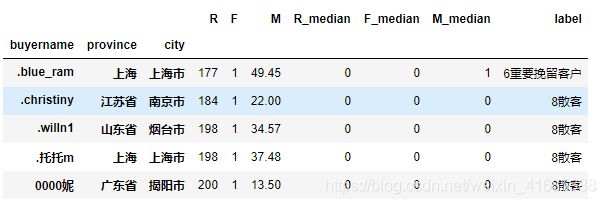
6、保存RFM及labal数据
import pandas as pd
import pymysql
from sqlalchemy import create_engine
#转化一下表,去除多个索引
df2 = group_df.reset_index(0, drop=False)
df2 = df2.reset_index(0, drop=False)
group_df = df2.reset_index(0, drop=False)
display(group_df.head())
# 初始化数据库连接,使用pymysql模块
# MySQL的用户:root, 密码:123456, 端口:3306,数据库:lean2
con = create_engine('mysql+pymysql://root:131129@localhost:3306/rfm')
#直接写入数据-->mydf-->mydf表会自动创建
# 将新建的DataFrame储存为MySQL中的数据表,储存index列
group_df.to_sql('orders_rfm', con, index=True)
print('Read from and write to Mysql table successfully!')7、统计分类客户人群分布
label_df = group_df.groupby('label').agg({'label':"count"})
label_df.columns = ['count']
display(label_df.T )
label_df=label_df.sort_index(axis=0, ascending=False)
x=label_df.index.values
y=label_df["count"]
figure = plt.figure(num="用户分类",figsize=(8,4),dpi=80,facecolor="LightGray",edgecolor="blue",frameon=True)
axes1=figure.add_subplot(1,1,1)
plt.barh(x, y, align='center',color=['gray','orange','r','y','c','m','y','g'], ecolor='black')
plt.title("用户分类数量图")
plt.xlabel("数量")
for y, x in enumerate(y):
plt.text(x+1, y, "%s" %x)
plt.show()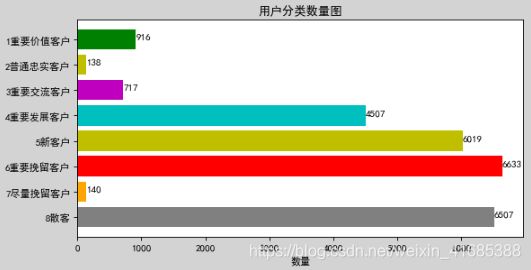
8、代码封装
略
五、可视化展示