flink table转换DataStream报错 (toAppendStream和toRetractStream区别)
代码实现功能: 统计单词个数
代码如下:
public static void main(String[] args) throws Exception {
String path = "D:\\cjj\\cjj.txt";
StreamExecutionEnvironment fbEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment fbTableEnv = StreamTableEnvironment.create(fbEnv);
SingleOutputStreamOperator<WordCount> sos = fbEnv.readTextFile(path).flatMap(new FlatMapFunction<String, WordCount>() {
@Override
public void flatMap(String s, Collector<WordCount> out) throws Exception {
for (String word : s.split("\\s")) {
if(!StringUtils.isNullOrWhitespaceOnly(word)) {
out.collect(new WordCount(word.trim(), 1));
}
}
}
});
fbTableEnv.createTemporaryView("test", sos);
Table table = fbTableEnv.sqlQuery("select word, sum(num) num from test group by word");
//将table转换成stream
fbTableEnv.toAppendStream(table, WordCount.class).print();
fbEnv.execute("fsdf");
}
运行代码报错
报错信息如下:
log4j:WARN No appenders could be found for logger (org.apache.flink.api.java.typeutils.TypeExtractor).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "main" org.apache.flink.table.api.ValidationException: Table is not an append-only table. Use the toRetractStream() in order to handle add and retract messages.
at org.apache.flink.table.planner.StreamPlanner.translateToType(StreamPlanner.scala:396)
at org.apache.flink.table.planner.StreamPlanner.org$apache$flink$table$planner$StreamPlanner$$translate(StreamPlanner.scala:180)
at org.apache.flink.table.planner.StreamPlanner$$anonfun$translate$1.apply(StreamPlanner.scala:117)
at org.apache.flink.table.planner.StreamPlanner$$anonfun$translate$1.apply(StreamPlanner.scala:117)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.flink.table.planner.StreamPlanner.translate(StreamPlanner.scala:117)
at org.apache.flink.table.api.java.internal.StreamTableEnvironmentImpl.toDataStream(StreamTableEnvironmentImpl.java:351)
at org.apache.flink.table.api.java.internal.StreamTableEnvironmentImpl.toAppendStream(StreamTableEnvironmentImpl.java:259)
at org.apache.flink.table.api.java.internal.StreamTableEnvironmentImpl.toAppendStream(StreamTableEnvironmentImpl.java:250)
at org.table.StreamTableExample.main(StreamTableExample.java:35)
Process finished with exit code 1
大概意思:table转换流实现的功能是更新模式因为我们sql中用到聚合函数和group by

用table和sql处理实时数据转换成流数据,我们通常使用toAppendStream和toRetractStream这两个方法。
toAppendStream和toRetractStream的区别
toAppendStream使用场景是追加模式,只有在动态Table仅通过INSERT更改修改时才能使用此模式,即它仅附加,并且以前发出的结果永远不会更新。如果更新或删除操作使用追加模式会失败报错;
缩进模式: 始终可以使用此模式。返回值是boolean类型。它用true或false来标记数据的插入和撤回,返回true代表数据插入,false代表数据的撤回。
当改成toRetractStream
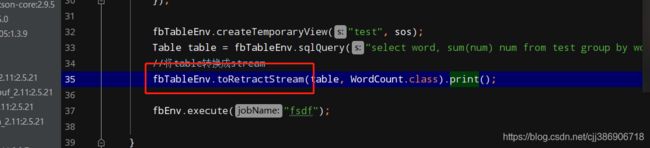
输出结果:
log4j:WARN No appenders could be found for logger (org.apache.flink.api.java.typeutils.TypeExtractor).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
9> (true,word = abc num = 1)
9> (false,word = abc num = 1)
9> (true,word = abc num = 2)
9> (false,word = abc num = 2)
4> (true,word = java num = 1)
4> (true,word = age num = 1)
8> (true,word = hhhj num = 1)
8> (true,word = bac num = 1)
9> (true,word = abc num = 3)
8> (true,word = python num = 1)
5> (true,word = hlooe num = 1)
3> (true,word = hollo num = 1)
5> (true,word = nihao num = 1)
8> (false,word = bac num = 1)
5> (true,word = hwllo num = 1)
5> (true,word = name num = 1)
5> (false,word = name num = 1)
5> (true,word = name num = 2)
5> (false,word = name num = 2)
5> (true,word = name num = 3)
12> (true,word = world num = 1)
5> (true,word = hello num = 1)
4> (true,word = cjj num = 1)
1> (true,word = hai num = 1)
4> (false,word = java num = 1)
4> (true,word = java num = 2)
5> (false,word = nihao num = 1)
5> (true,word = nihao num = 2)
4> (true,word = pu7thpon num = 1)
5> (false,word = nihao num = 2)
5> (true,word = nihao num = 3)
8> (true,word = bac num = 2)
1> (false,word = hai num = 1)
1> (true,word = hai num = 2)
5> (true,word = cj num = 1)
5> (false,word = name num = 3)
5> (true,word = name num = 4)
5> (false,word = name num = 4)
5> (true,word = name num = 5)
Process finished with exit code 0
通过过滤和转换算子获取到插入的数据
fbTableEnv.toRetractStream(table, WordCount.class).filter(
//true代表数据插入 false数据回撤
new FilterFunction<Tuple2<Boolean, WordCount>>() {
@Override
public boolean filter(Tuple2<Boolean, WordCount> tuple2) throws Exception {
return tuple2.f0;
}
}
).map(new MapFunction<Tuple2<Boolean, WordCount>, WordCount>() {
@Override
public WordCount map(Tuple2<Boolean, WordCount> booleanWordCountTuple2) throws Exception {
return booleanWordCountTuple2.f1;
}
}).print();