详解Spark核心算子 : aggregateByKey和combineByKey
详解Spark核心算子 : aggregateByKey和combineByKey
aggregateByKey
aggregateByKey有三种声明
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)
(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int)
(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U)
(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
第一个可以指定多指定一个分区器(不指定默认Hashpartitioner),第二个可以指定分区数量。
下面用的是第三种普通的aggregateByKey。
aggregateByKey和aggregate(可以先看看这个算子)参数列表雷同,原理上还是有些差别的。
柯里化两个参数列表,第一个参数列表中的参数是初始值,第二个参数列表中传两个函数,seqOp作用于每个分区中的每个key相同的数据集。aggregate中这个函数作用于每个分区,combOp函数作用于不同分区之间,上一个函数处理完的丶key相同的数据集,硬想有些难,下面看栗子。
object Demo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("aa")
val sc = new SparkContext(conf)
val list = List((1,2),(2,7),(1,3),(2,8),(3,9),(3,10)
,(1,4),(1,5),(2,6),(2,11),(3,12),(3,13))
val listRDD = sc.parallelize(list,2)
println(listRDD.getNumPartitions)
val rs = listRDD.aggregateByKey(0)((a,b)=>{
println("diyige"+a+","+b)
math.max(a,b)
},(x,y)=>{
println("dierge"+x+","+y)
x+y
}).collect().foreach(println)
}
前6个元素会分到第一个分区,后6个会分到第二个分区
zeroValue
zeroValue是参数调用aggregateByKey时传入的初始值,可以理解为第零个元素,
在aggregate中seqOp和combOp两个函数计算的时候都需要用到zeroValue,
在aggregateByKey中只有seqOp函数需要zeroValue。
累加器
seqOp函数的第一个参数是累加器,第一次执行时,会把zeroValue赋给累加器。,第一次之后会把返回值赋给累加器,作为下一次运算的第一个参数。seqOP函数每个分区下的每个key有个累加器,combOp函数全部分区有几个key就有几个累加器。如果某个key只存在于一个分区下,不会对他执行combOp函数
seqOp
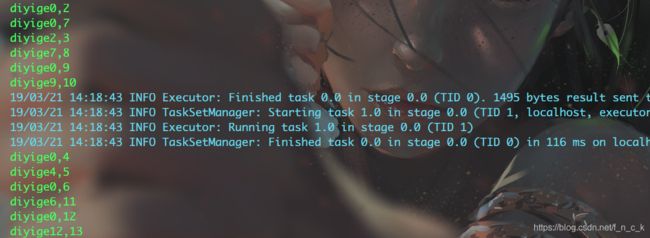
seqOp函数会遍历分区内所有
(a,b)
遍历到第一个元素<1,2>的时候,a是key为1的累加器,会把初始值zeroValue赋给这个累加器,b代表键值对的值2,之后将返回值赋回给这个累加器。
遍历到第二个元素<2,7>的时候,a是key为2的累加器,也会把zeroValue赋给这个累加器,b代表键值对的值7
遍历到第三个元素<1,3>的时候,a是key为1的累加器,b代表这个键值对的值3
以此类推
遍历元素的时候,遍历到的键值对的key只有两种,一种是第一次见,一种是已经见过的,第一次见就会初始化属于这个key的累加器,b置为这个键值对的值。如果不是第一次见,a就置为这个key上一次运算后的累加器,b置为这次的键值对的值。
combOp
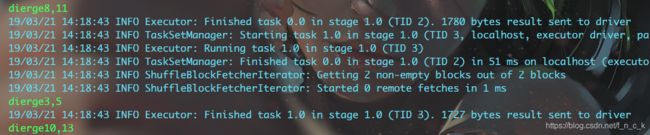
这个栗子中有两个分区,每个分区有三个key,一共最后有6条数据。
combOp会计算所有分区key相同的数据集,如果某个key只存在于一个分区中,这个key的数据不会计算combOp函数,在aggregateByKey中,zeroValue不作用于combOp函数,所以combOp函数只作用于存在于多个分区间key相同的数据集。
combOp函数遍历所有中间结果,遇到一个从没见过的key时,记录下,之后遇到其他分区的这个key的累加器时,把x置为第一次遇到这个键对应的累加器,把y置为第二次遇到这个键对应的累加器。
可以理解为,有所有分区中所有的key的数量的combOp函数,一个key对应一个combOp函数。
某个key相同的累加器的数量就是这个key对应的combOp函数执行的次数+1,两个累加器执行一次,三条执行两次。

至此结束
未完待续