CentOS7虚拟机两台
java8、ssh
Hadoop: 2.7.3
安装java-devel用于调试
1、准备工作
修改两台虚拟机主机名master、slave
[root@master /]# hostname master
配置Hosts
[root@master /]# vim /etc/hosts
192.168.1.240 master
192.168.1.241 slave
配置完成之后,互相ping一下,看能否连通
ping master
ping slave
2、配置免密码登录
在所有机器上都生成私钥和公钥,一路回车
ssh-keygen -t rsa
需要让机器能互相访问,需要把slave节点上的 id_rsa.pub发给master
在master上,将所有公钥加到用于认证的公钥文件authorized_keys中
将公钥文件authorized_keys分发给每台slave
scp ~/.ssh/id_rsa.pub root@master:~/.ssh/id_rsa.pub.slave
cat ~/.ssh/id_rsa.pub*>>~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys root@slave:~/.ssh/
验证免密码通信
ssh master
ssh slave
3、配置JAVA环境变量
注意通过yum安装的java的jre路径
[root@master /]# vim ~/.bashrc
在其内添加如下内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el73.x8664/jre
export PATH=JAVA_HOME/bin:PATH
[root@master /]# source ~/.bashrc
4、安装配置Hadoop
官网下载Hadoop2.7.3
解压到/usr/local/hadoop2.7.3
配置hadoop环境变量
[root@master /]# vim ~/.bashrc
添加如下内容:
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export PATH=JAVA_HOME/bin:HADOOP_HOME/bin:$PATH
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
[root@master /]# source ~/.bashrc
进入hadoop/etc/hadoop/目录下,配置以下文件hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml
[root@master /]# cd $HADOOP_HOME
[root@master hadoop-2.7.3]# cd etc/hadoop/
1、进入hadoop-env.sh,该文件为hadoop集群启动检查相关环境变量的文件,注意检查JAVA_HOME环境变量的路径是否是对的
2、进入yarn-env.sh,同样检查JAVA_HOME
3、进入slaves,配置如下内容,其内配置的是集群内的所有主机的主机名,用来启动DataNode存储
master
slave
4、修改core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/usr/local/hadoop-2.7.3/tmp
5、修改hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.namenode.name.dir
file:///usr/local/hadoop-2.7.3/dfs/name
dfs.datanode.data.dir
file:///usr/local/hadoop-2.7.3/dfs/data
dfs.replication
2
6、修改mapred-site.xml
mapreduce.framework.name
yarn
7、修改yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop-namenode
将配置好的hadoop-2.7.3文件夹分发给所有slave吧,本例就一台slave
scp -r /usr/local/hadoop-2.7.3/ root@slave:/usr/local/
启动Hadoop
[root@master hadoop-2.7.3]# sbin/start-all.sh
master上执行jps查看以下进程是否都存在
13312 ResourceManager
19555 Jps
13158 SecondaryNameNode
12857 NameNode
13451 NodeManager
12989 DataNode
slave上执行jps查看
14112 Jps
9300 NodeManager
9179 DataNode
初次搭建,需要格式化namenode
[root@master hadoop-2.7.3]# bin/hadoop namenode -format
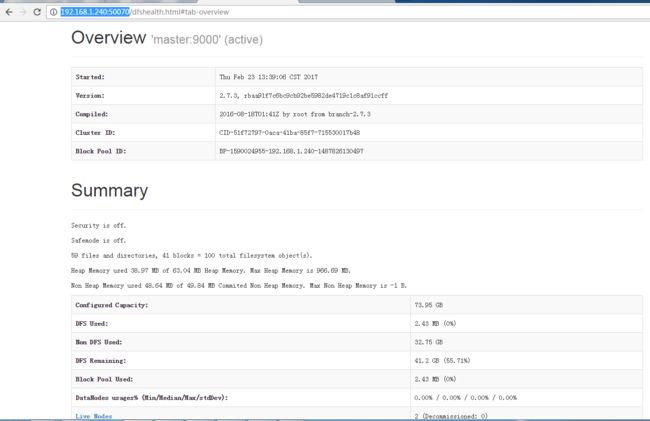
Hadoop相关管理界面
Hadoop集群管理界面http://192.168.1.240:50070/
从中可以查看节点启动的相关信息,也可以通过日志定位启动过程中的问题
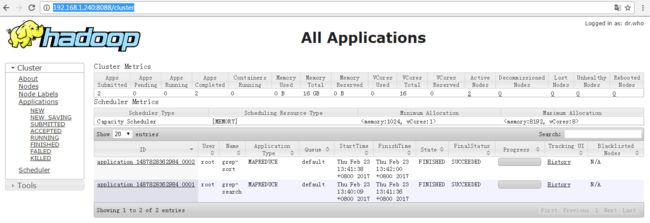
mapreduce任务执行管理界面http://192.168.1.240:8088
执行Hadoop自带MR示例程序
hadoop提供的示例程序做了这件事:用正则表达式dfs[a-z.]+来搜索所有的输入文件,对搜索出的结果汇总并排序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep /user/test1/input /user/test1/output 'dfs[a-z.]+'
其中输出文件目录需要制定hdfs的绝对目录,否则,会输出到/user/root下
任务执行进度可以在http://192.168.1.240:8088上查看,执行完毕后执行下面的命令查看结果
[root@localhost hadoop-2.7.3]# bin/hdfs dfs -cat /user/test/output/*
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.period
2 dfs.audit.log.maxfilesize
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.replication
1 dfs.file
FAQ:
1、环境搭建好,启动hadoop时,NameNode进程无法启动
初次启动,没有执行格式化命令
2、配置文件中注意格式和路径,写错了很难查出来
3、Hadoop启动hdfs时,datanode无法启动的问题
问题描述:java.io.IOException: Incompatible clusterIDs in /home/lxh/hadoop/hdfs/data: namenode clusterID = CID-a687ed3c-45d2-456c-828d-bc5d8af2a0cf; datanode clusterID = CID-2169f5c7-b111-4af8-a899-56be4bc64702
原因:执行hdfs namenode -format后,current目录会删除并重新生成,其中datanode/current/VERSION文件中的clusterID也会随之变化,而datanode的datanode/current/VERSION文件中的clusterID保持不变,造成两个clusterID不一致。
解决方法:所以为了避免这种情况,可以再执行的namenode格式化之前,删除datanode的current文件夹,或者修改datanode的VERSION文件中出clusterID与namenode的VERSION文件中的clusterID一样,然后重新启动dfs。
3、注意关闭防火墙(以及关闭防火墙的开机启动)
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动