2019独角兽企业重金招聘Python工程师标准>>> 
linux内核list分析一:前言
链表list是linux内核最经典的数据结构之一,不过在深入学习链表的实现之前,需要了解几个知识:offsetof、typeof、container_of
1、offsetof
offsetof的作用是返回结构体中的某个成员在该结构体中的偏移量,请看下面的例子:
struct person
{
int height;
int weight;
};
printf("%u\n", offsetof(struct person, height)); // 0
printf("%u\n", offsetof(struct person, weight)); // 4 |
而offsetof的真实面目是
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) |
这里巧妙的利用了0地址。也许有人会产生疑问,怎么可能会对0地址进行操作呢?为了更容易理解,下面都使用struct person为例。其实,0是一个具体的常量值,它是一个地址,而(struct person *)0则是一个指针,而且是一个指针常量(即指针本身是常量,但它指向的地址里的内容可以改变)。只要我们不去对一个空指针进行读写,就不会存在非法访问内存的问题,例如:
// 读取操作
struct person *xiao_hua = 0;
struct person tmp = *xiao_hua; // error
// 写入操作
struct person *xiao_hua = 0;
struct person tmp = {180, 60};
*xiaohua = tmp; // error |
那么,其他的操作都是OK的。
offsetof(struct person, weight) 经过宏替换后变为 ((size_t) &((struct person )0)->weight)
1、(struct person )0 表示 一个指向struct person结构的指针,虽然这个struct person结构不存在,但只要不去对它进行读写就OK
2、(struct person )0)->weight 表示 1中的指针所指向的那个struct person结构的weight成员
3、&((struct person )0)->weight 表示 1中的指针所指向的那个struct person结构的weight成员的地址
4、weight成员的地址 减去 它所在的struct person结构的地址,就可以得出weight在struct person结构中的偏移量,但是此时,struct person结构的地址为0,所以weight成员的地址就是weight在struct person结构中的偏移量
2、typeof
typeof关键字是C语言中的一个新扩展,这个特性在linux内核中应用非常广泛。
typeof的参数可以是两种形式:表达式或类型。
(1) 表达式的例子:
// 以下示例声明了int类型的var变量,因为表达式foo()是int类型的。由于表达式不会被执行,所以不会调用foo函数。
extern int foo();
typeof(foo()) var; // 等价于 int var; |
(2) 类型的例子:
typeof(int *) a,b; // 等价于 int *a,*b; |
3、container_of
它的作用是根据一个结构体变量中的一个域成员变量的指针来获取指向整个结构体变量的指针。
#define container_of(ptr, type, member) ({ \
const typeof ( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( ( char *)__mptr - offsetof(type,member) );})
struct person xiao_hua = {180, 60};
struct person *p_xiao_hua = container_of(&xiao_hua.weight, struct person, weight);
printf("%d\n", p_xiao_hua->height); // 180 |
container_of(&xiao_hua.weight, struct person, weight) 宏替换后的结果为
const typeof ( ((struct person *)0)->weight ) *__mptr = (&xiao_hua.weight); (struct person *)( ( char *)__mptr - offsetof(struct person,weight) );}) |
第一个语句中的‘typeof ( ((struct person )0)->weight )’ 其实就是 ‘int’,所以第一个语句就是’const int __mptr = (&xiao_hua.weightr)’
第二个语句将weight的地址减去weight在struct person中的偏移量就得到了struct person结构变量的地址。
这里使用了一个中间变量__mptr,也许我们会质疑,它是多余的。但是,请看下面的情况
#define container_of(ptr, type, member) ({ \
(type *)( ( char *)ptr - offsetof(type,member) );})
struct person xiao_hua = {180, 60};
struct person *p_xiao_hua = container_of(&xiao_hua, struct person, weight); // 错误使用container_of
printf("%d\n", p_xiao_hua->height); |
所以中间变量__mptr这里起到了提醒开发者的功能。如果开发者传入的ptr指针指向的类型,与结构体中成员的类型不符,编译器在这里会打印一条warning,提示开发者可能存在的错误。
linux内核list分析二:双向循环链表
大学时代,我们就已经学过链表了,例如下面的例子
struct person
{
int height;
int weight;
struct person *prev, *next;
};
// 查找指定的person是否存在
int person_exists(struct person *head, struct person in_person)
{
struct person *p;
for(p = head->next; p != head; p = p->next)
{
if(p->height == in_person.height && p->weight == in_person.weight)
return 1;
}
return 0;
} |
上面的代码定义了struct person这样的链表,通常会实现该链表的插入、删除、查找等操作。现在因为业务需求,又需要struct animal这样的链表,同样,我们也会实现该链表的插入、删除、查找等操作。
struct animal
{
int legs;
struct animal *prev, *next;
};
// 查找指定的animal是否存在
int animal_exists(struct animal *head, struct animal in_animal)
{
struct animal *p;
for(p = head->next; p != head; p = p->next)
{
if(p->legs == in_animal.legs)
return 1;
}
return 0;
} |
那如果再出现其他的数据类型也需要使用到链表的操作,我们也要为新增的数据类型编写新的链表插入、删除、查找等操作,这样就出现了大量的冗余代码。其实,查找person与anmial是否存在的代码处理逻辑都是一样的,只是数据类型不一样而已。所以为了解决这个问题,linux内核中把与链表有关的操作抽象出来,其他需要使用链表操作的数据类型只要使用内核定义的链表就OK,无需自己再开发与链表的基本操作相关的代码。
linux内核双向循环链表仅仅使用了一个数据结构struct list_head,即链表的头结点和数据结点都是使用struct list_head表示
struct list_head{
struct list_head *next, *prev;
}; |
让我们看看使用了struct list_head的struct animal是怎样的。下面代码中的INIT_LIST_HEAD、list_add、list_for_each_entry都是linux内核实现的。它的具体实现可以参考include/linux/list.h
struct animal
{
int legs;
struct list_head list;
};
// 初始化链表头结点
struct list_head animal_list;
INIT_LIST_HEAD(&animal_list);
// 初始化struct animal
struct animal animal1;
animal1.legs = 4;
INIT_LIST_HEAD(&animal1.list);
// 将animal1加入链表
list_add(&animal1, &animal_list);
// 加入其它animal到链表
.....
// 遍历 animal_list
struct animal *p_animal;
list_for_each_entry(p_animal, &animal_list, list)
{
printf("legs = %d\n", p_animal->legs);
} |
它的内存布局如下: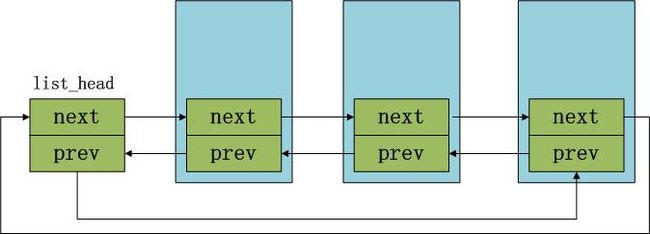
linux内核list分析三:哈希链表
linux内核里面的双向循环链表和哈希链表有什么不同呢?1、双向循环链表是循环的,哈希链表不是循环的 2、双向循环链表不区分头结点和数据结点,都用list_head表示,而哈希链表区分头结点(hlist_head)和数据结点(hlist_node)。与哈希链表有关的两个数据结构如下:
struct hlist_head {
struct hlist_node *first; //指向每一个hash桶的第一个结点的指针
};
struct hlist_node {
struct hlist_node *next; //指向下一个结点的指针
struct hlist_node **pprev; //指向上一个结点的next指针的指针
}; |
1、哈希链表为什么要区分头结点和数据结点?
头结点和数据结点如果都使用list_head的话,那岂不是更容易实现。内核list.h中描述得很明白:
/* * Double linked lists with a single pointer list head. * Mostly useful for hash tables where the two pointer list head is * too wasteful. * You lose the ability to access the tail in O(1). */ |
意思是说这种双向链表的头结点只有一个指针成员(即struct hlist_node *first),它主要使用在哈希表中。因为哈希表会有很多表项,每个表项如果使用list_head这样含有两个指针成员的数据结构的话,会造成内存空间的浪费。所以,为了尽可能的减少内存空间的浪费,就要使数据结构变得稍微复杂一些,鱼和熊掌不可兼得啊。
2、hlist_node的pprev成员为什么是struct hlist_node **类型的?
如果hlist_node的定义是下面这样的话
struct hlist_node {
struct hlist_node *next;
struct hlist_node *prev;
}; |
第一个数据结点的prev成员应该指向头结点,但是因为prev成员指向的是hlist_node的数据类型的指针,而头结点的数据类型是hlist_head,所以无法实现。为了解决这样的问题,才有了下面的hlist_node的定义
struct hlist_node {
struct hlist_node *next;
struct hlist_node **pprev;
}; |

在上图中,第一个数据结点的pprev成员(数据类型struct hlist_node **)指向头结点的first成员(数据类型struct hlist_node *),第二个数据结点的pprev成员(数据类型struct hlist_node **)指向第一个数据结点的next成员(数据类型struct hlist_node *),从而对于第一个数据结点的操作和非第一个数据结点的操作就没有区别了,都统一起来了。这样就不用对第一个数据结点进行特殊处理了,为编写代码带来了极大的好处,这种设计有点小艺术。
其他的hlist的初始化、插入、删除、遍历请自行参阅list.h源文件,源文件是最好的老师。