SASBASE认证考试划重点
目录
一、SAS基本设置
proc import
infile选项控制输入
sas遇到错误会怎么处理
sas系统选项optinos
读取文件的input
贡献变量in选项
put输入格式
lable
二、函数
字符型函数
循环函数
平均函数的变量简写
条件判断IF/ELSEIF
数组命名方式
将字符型变量转换成数值型变量的方式:
排序函数
求和函数
first/last应用
retain的应用
scan函数
三、打印描述数据
数值型变量输出格式format
proc tabulate
proc report
report中break和rbreak用法
proc report 输出中添加统计量
proc means
输出output
四、数据合并:
set合并数据
MERGE合并数据
数据转换TRANSPOSE
过程中创建输出file/put对应从原始文件中读取数据infile/input
datasets步的选项
激活data步debug
_error_
format
五、报告输出
html输出
一、SAS基本设置
proc import
---
infile选项控制输入
FIRSTOBS= FIRSTOBS= 选项告诉SAS从哪一行开始读取数据,当数据开头有些说明信息,或者想要跳过某些行时,这个选项很有用。
OBS= OBS=告诉SAS一直读取到哪一行位置,注意是行而不是观测值(有的观测值占据多行)比如,如下的原始数据文件中,结尾处还有一句不需要的数据说明时。
sas遇到错误会怎么处理
数据错误:当sas遇到数据错误时候,缺失数据值以恰当的值代替,并继续执行程序。数据错误不会中止程序运行。
语法错误:程序将停止执行
sas系统选项optinos
OPTIONS语句 是SAS程序的一部分,并可影响之后的所有语句。由OPTIONS关键词开头,后面是相关选项。
OPTIONS语句既不属于数据步也不属于过程步,这个全局变量可以出现在程序的任何部分,但放在开头最有意义,你可以很容易看到哪些选项在发挥作用。如果OPTIONS语句只出现在数据步或者过程步中,那么它会影响那个过程。注意,后面的OPTIONS语句会覆盖前面的,即以后面的OPTIONS为主。
OPTIONS LINESIZE=80 NODATE; options date;在报告中显示时间
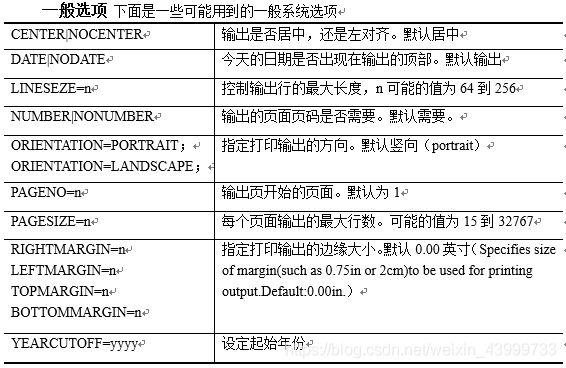
FIRSTOBS= n选项告诉SAS从哪一行开始读取数据,当数据开头有些说明信息,或者想要跳过某些行时,这个选项很有用。
YEARCUTOFF
选项“yearcutoff=" 选项可以在100年的时间跨度内为任意两位年份值指定所属的世纪,
例如yearcutoff=1950表示50到99之间的两位年份值对应于1950到1999年而00到49之间的两位年份值对应于2000到2049年;
读取文件的input
input的应用详见:点击这里
贡献变量in选项
| IN=*** 这个选项用来创建临时变量以追踪当前的观测是否来自该数据集。 |


put输入格式
data product;
date=put('13mar2019'd,ddmmyy10.);
date1=input('13mar2019'd,ddmmyy10.);
date3=input('13mar2019',ddmmyy10.);
date4=input('13mar2019',date9.);
date5=input('13032019',ddmmyy10.);
run;运行结果:
date的长度是10个字节;
input输入日期时,输入格式必须和后面的格式相对应;
lable
data步里给变量加永久标签,proc步里用lable只在当前过程有效。
如:proc print语法如下:
PROC PRINT DATA=data-set;SAS默认打印观测值数,noobs选项可以取消打印。SAS默认打印时用变量标签代替变量,用label可以改变取消标签:
PROC PRINT DATA=data-set NOOBS LABEL;
run;proc print data=bank label;
labne var_name='tep_lable';
run;
二、函数
字符型函数
data work.AreaCodes;
Phonenumber=3125551212;
Code='('!!substr(Phonenumber,1,3)!!')';
run;符号||、!!、¦¦,这三个符号都表示将字符串连接在一起。
data staff;
job="FA";
level="1";
job=job || level;
run;此程序执行的结果,job的值依然是“FA”并不会成为“FA1”;
data test;
first='ipswich,englang';
city=substr(first,1,7);
city_country=city!!','!!'england';
run;执行后city_country的结果是:ipswich ,england;长度23个字节;
循环函数
data work.inventory;
products=7;
do until (products gt 6);
products+1;
end;
run;
循环中do until先执行语句再进行判断;do while 先判断再执行程序;
data bank;
input name $ rate;
cards;
first 0.9
bank 0.98
distei 0.87
;
run;
data newbank;
do year=1 to 3;
set bank;
capital+5000;
/* output;*/
end;
run;当data步中set语句在do循环里面,将会一条条输入数据,如上,如果循环里没有output则输出只有最后一条记录;
平均函数的变量简写
mean(of num1-num4);条件判断IF/ELSEIF
数组命名方式
array name (n) $ variable-list;
·name是数组名称
·n为数组中变量个数,括号可以用{} 或者[]代替
·如果变量是字符且之前没定义,需要添加$
将字符型变量转换成数值型变量的方式:
data bonus;
infile 'file-specification';
input salary $ 1-7 raise 9-11;
newsalary=input(salary,comma7.) + raise;
run;input语句将字符型变量salary变为数值型变量;
put语句将数值变成字符变量;
字符型和数值型变量相计算(加减乘除)
data retail;
cost='20';
total=.10*cost;
run;total的值可以计算,total最终的计算值是2;
data retail;
cost='$20,000';
dis=0.10*cost;
run;dis的值为空值,不可以计算,因为不能识别cost字符串里面的$和逗号‘,’;
用连接符将字符串和数值连在一起的结果:
data product;
num=567;
item='101';
item_num=item || '/' || num;
run;item_num的值是字符型,并且把数值型变量num变为字符型,由于数值型变量默认8个字节长度,所以变成字符串时有5个空格填充使得数值变量567,变成字符变量“ 567”,故最终item_num的结果是101/ 567;
排序函数
求和函数
first/last应用
retain的应用
scan函数
scan函数: scan(s,n,"char")表示从字串string中以char为分隔符提取第n个字符串;
scan(s,n<,list-of-delimiters>)如果指定分隔符,则只会按照该分隔符提取。
如果不指定,则按照常用的分隔符拆分,默认分隔符为:空格 . < ( + & ! $ *) ; ^ - / , % | 等之一或组合
如果|n|=0或大于字符s的个数,则该函数返回空格。
data test;
a='a tale of two citys,char,les,jdickens';
word=scan(a,3,',');
run;上面程序的运行结果word结果是les;word变量的长度和a的长度一样。
三、打印描述数据
数值型变量输出格式format
打印数据时,SAS会自动安排最好的格式,小数点位数、空格等。当不需要默认格式时,可以用SAS formats改变打印的外观。
data a;
b=110700;
b1=110701;
b2=110702;
b3=110703;
format b dollar11.2
b1 dollar8.2
b2 comma8.2
b3 comma11.2
;
run;输出结果:![]()
proc tabulate
PROC TABULATE 比proc mean和proc freq过程产生的报告更好看;
语句形式为:
PROC TABULATE;
CLASS classification-variable-list; 将数据分成不同部分
TABLE page,row,column;指定页、行、列,
data fl;
infile cards dlm=' ';
input name $ port $ loco $ type $ price length;
cards;
s maalea sail sch 95 64
am maalea sail yac 72.95 65
al lahaina sail cat 112 60
o maalea power cat 62 65
an maalea sail sch 177.5 52
ha maalea power cat 88.99 110
le maalea power yac 99.99 45
ka maalea power cat 69.5 70
re lahaina power yac 59.95 50
bl maalea sail cat 92.95 65
;
run;
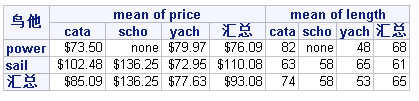
proc format;
value $typ "cat"="cata" "sch"="scho" "yac"="yach";
proc tabulate data=fl;
class loco type;
var price length;
format type $typ.;
table loco="" all="汇总",mean=""*(price="mean of price"*format=dollar9.2 length="mean of length"*format=6.0)*(type="" all="汇总") /box="鸟他" misstext="none";
run;
结果:
proc report
常用选项:
GROUP为变量的每一个唯一值创建一行;
ACROSS为变量的每一个唯一值创建一列;
ORDER为每一个观测创建一行,并且这些行按照排序变量的取值进行排列;
proc report中define的用法
define用来为单个变量指定一些选项
define var/options 'column-header';
define age/ORDER 'age at asimission';
该语句使sas生成的报表按变量age排序,并且用‘age at asimission’作为该变量的标题;例子:
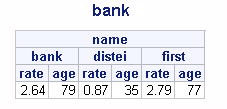
pro1:
data bank;
input name $ rate age;
cards;
first 0.9 23
first 0.93 25
first 0.96 29
bank 0.98 23
bank 0.88 29
bank 0.78 27
distei 0.87 35
;
run;
proc report data=bank nowindows headline;
title "bank";
column name,(rate age);
define name/across;
run;pro1:运行结果:
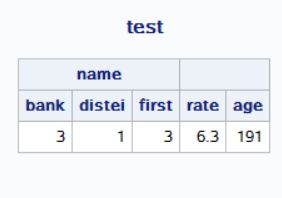
pro2:
proc report data=bank headline;
title "test";
column name rate age;
define name / across;
run;
pro2运行结果:
pro3:
proc report data=bank headskip;
title "test1";
column name rate age;
define name / group;
define rate/mean 'avg rate';
run;结果:define中group对name进行分组,每个唯一name观测只生成一条数据;
define中group对rate做的mean指的是对每个name值求平均,后面‘avg rate’是为变量重命名,如果‘avg/rate’则是变量名换行表示;
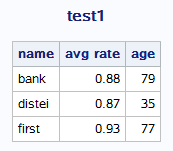
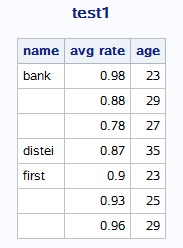
若将define中的group换为order,其他不变则结果是:
proc report data=bank;
column name age rate;
run;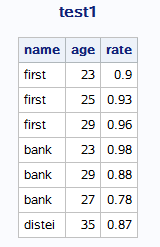
proc report data=bank;
column age rate;
run; 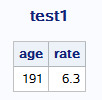
proc report中若column中全是数值型变量,则结果集是变量的求和;
report中break和rbreak用法
Break语句和Rbreak可以为报告增加分割,Break语句为指定变量每一个唯一值添加分割,而Rbreak为整个报表添加分割(如果使用by语句,则会为每个by分组添加分割)。语句的基本语法为:
BREAK location variable / options;
RBREAK location / options;
location有两个取值before、after 决定分割出现在报表特定部分之前还是之后。斜杠/后的选项通常有
page:开始新的一页
summarize:为数值变量插入汇总统计量
data parks;
input name $ type $ region $ rate age;
cards;
first nm west 1 2
first nm west 1 2
first nm east 3 4
first np west 5 6
bank nm east 7 8
bank nm west 1 2
bank np west 3 4
distei np west 5 6
;
run;
proc report data=parks;
column name type region rate age;
define region / order;
break after region/summarize;
/*rbreak after/summarize;*/
title "break and rbreak 3";
run;运行结果:
注意,使用break时,需要指定一个,并且这个变量必须是分组或者排序变量,即:需要在define语句中为该变量指定group或者order用法选项;
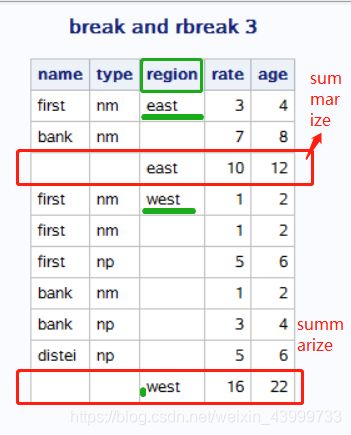
当吧break改为rbreak时,运行结果为:
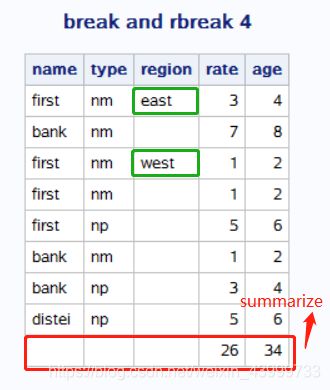
proc report 输出中添加统计量
report中添加统计量和tabulate过程means过程计算统计量是调用的同一个内部引擎实现的,report步中在column语句该变量名与统计量关键字之间插入逗号即可实现,如果是统计量N则不需要逗号,因为该统计量不针对具体的变量进行统计。
如:打印变量Age的中位数和观测数 COLUMN age,MEDIAN N;
若要对一个变量计算多个统计量,将多个统计量放到括号即可
COLUMN age,(MAX MIN) (height weight),MEAN;为age计算两个统计量,为变量height和weight计算同一个统计量;
proc report中添加计算变量
添加新变量是通过计算块实现的,而计算块是COMPUTE语句开始,ENDCOMP语句结束的一个语句块。在两个语句之间可以使用编程语句完成新变量的计算,编程语句仅限于:赋值语句、IF-THRN/ELSE、DO循环。不能为新变量指定DEFINE语句,如果指定,必须添加COMPUTED 选项,以表明该变量是通过计算块创建的;
DEFINE income / COMPUTED;
COPMUTE income;
income=salary.SUM + bonus.SUM;
ENDCOMP;上面语句生成数值计算变量income,其值为salary和bonus的总和;
proc means
means过程提供数值变量的简单统计量,过程以关键词proc means开头,后面有以下选项:proc means options;
MACDEC=n 执行显示的小数位数;
MISSING 将缺失值视为有效的汇总组;

输出output
X Y
-- --
5 2
3 1
5 6
The following SAS program is submitted:
data SASUSER.ONE SASUSER.TWO OTHER;
set SASDATA.TWO;
if X eq 5 then output SASUSER.ONE;
if Y lt 5 then output SASUSER.TWO;
output;
run;
若没有最后一个output语句则输出的数据集中ONE和 TWO 有2个观测,OTHER无观测值;
但是上述代码中含有output,则输出结果中ONE和 TWO 有5个观测,OTHER有3个观测值;
四、数据合并:
set合并数据
data three;
set one two;
run;
data three;
set one two;
by x;
run;结果:
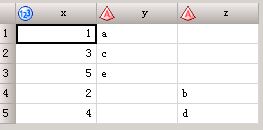 one数据集变量为x、y,two数据集变量为x、z;
one数据集变量为x、y,two数据集变量为x、z;
横向合并两个数据,若不加by变量则不对by变量排序,安装数据原来的顺序拼接;如果数据集two中含有和数据集one相同的变量,则two的变量会替换one里的变量;
data three;
set one;
set two;
run;若有两个set语句,则结果为:
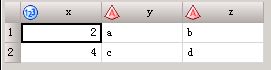
多个set语句时候,只保留观测最少数据集的个数,并且后面的数据集中的变量覆盖前面数据集中相同变量名里的观测值;
MERGE合并数据
MERGE 数据集必须先按BY变量排序,并且必须先按升序排序;
若MEGER 后面没有by ,则在处理数据时,就按行号进行连接数据,也就是a 的第一行接b的第一行,并且如果名称一样的变量会被后表覆盖。第二行接第二如,如此下去。
可以在merge某个或者两个数据集名字后添加in=contributor_variable(贡献变量)的选项,用于控制哪些观测值加入合并后的数据集。如果这个数据集对现在正在创建的观测值确实有贡献(即by变量上不上缺失值),那么贡献变量的值为真(1),否则值为假(0)。“IN=”选项创建的是一个临时变量,可以用在DAT步的任何地方,但不会添加到新数据集中。
BY变量在某个数据集中的变量名称不一样,可以用RENAME语句:
【注意rename在重命名时候旧名字=新名字】
MERGE MASTER TEST(IN=intest RENAME=(old_name=new_name));上语句能从TEST数据集中拿出一个观测值,将变量old_name重新命名为new_name,目的是用来合并,当再次打开TEST数据集,这个变量的名称仍然是old_name;
merge的运算和SQL里的left join 不一样,主要区别如下:
1、merge的运算多对一和一对多的结果是一样的
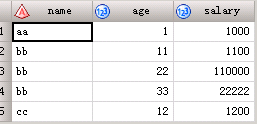
2、merge里A表B表分别都有3个相同的观察,在用by匹配时,相同观察会一一对应,如下:
A:
aa 1
bb 11
bb 22
bb 33
cc 12
B:
aa 1000
bb 1100
bb 110000
bb 22222
cc 1200
data c;
merge employee salary;
by name;
run;结果如下:
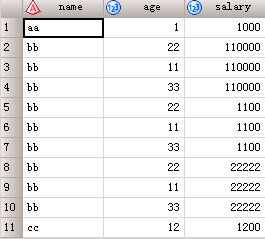
同样的数据集,如果用sql代码得出的结果完全不一样:
select a.*,b.salary from employee as a left join salary as b on a.name=b.name;结果如下:
数据转换TRANSPOSE
TRANSPOSE过程将观测转为变量,或者将变量转为观测,语句如下:
PROC TRANSPOSE DATA=data-set OUT=new-data-set;
BY variable-list;分组变量,转置数据集将会对每一个BY组将变量变成观测,数据集在转置前必须对这些BY变量排序;
ID variable-list;
VAR variable-list;
data baseball;
infile cards;
input team $ player type $ entry;
cards;
a 10 sa 43
a 12 sa1 51
b 8 sa 38
b 13 ba 12
c 12 ba 28
c 13 b1a 30
;
run;
proc sort data=baseball;
by team player;
run;
proc transpose data=baseball out=bb;
by team ;
id type;
var entry;
run;BY分组变量保持变量名称,ID将变量里的不同观测变成每一个列变量名,VAR指定转置变量

过程中创建输出file/put对应从原始文件中读取数据infile/input
datasets步的选项
proc datasets lib=work;
contents data=homework varnum;
quit;VARNUM
上下文: [PROC DATASETS, CONTENTS 语句] VARNUM 选项
Prints a list of the variable names in the order of their logical position in the table.(the order they were created)
The physical position of the variable in the table is engine-dependent.
Put语句 当写入原始数据文件或者报告时,也可以在put语句中使用输出格式,在每个变量后面放置输出格式:
PUT Profit DOLLAR8.2 Loss DOLLAR8.2 SaleDate MMDDYY8.;
激活data步debug
data WORK.TEST / debug;
set WORK.PILOTS;
State=scan(cityState,2,' ');
if State='NE' then description='Central';
run;_error_
15.Which statement is true concerning the SAS automatic variable _ERROR_?
A. It cannot be used in an if/then condition.
B. It cannot be used in an assignment statement.
C. It can be put into a keep statement or keep= option.
D. It is automatically dropped.
Answer: D
Syntax errors are common types of errors. Some SAS system options, features of the Editor
window, and the DATA step debugger can help you identify syntax errors. Other types of
errors include data errors, semantic errors, and execution-time errors.
format
20. The data set WORK.REALESTATE has the variable LocalFee with a format of 9. and a variable CountryFee with a format of 7.;
The following SAS program is submitted:
data WORK.FEE_STRUCTURE;
format LocalFee CountryFee percent7.2;
set WORK.REALESTAT;
LocalFee=LocalFee/100;
CountryFee=CountryFee/100;
run;
What are the formats of the variables LOCALFEE and COUNTRYFEE in the output dataset?
A. LocalFee has format of 9. and CountryFee has a format of 7.
B. LocalFee has format of 9. and CountryFee has a format of percent7.2
C. Both LocalFee and CountryFee have a format of percent7.2
D. The data step fails execution; there is no format for LocalFee.
Answer: C
五、报告输出
html输出
打开HTML输出目标使用的语句形式为:ODS HTML BODY=‘body-filename.html’ options;
生成正文文件(body文件)包含结果内容。选项FILE=与选项BODY=是同样的功能。其他常用的选项有:
CONTENTS='filename' 创建一个链接到正文的目录文件
PAGE='filename' 创建一个页面链接的目录文件
FRAME='filename' 创建一个框架文件,可以同时查看正文、内容或者页面文件。
STYLE='filename' 指定样式模板,默认是HTMLBLUE
为什么写ods pdf close
sas程序默认的是listing输出格式,如果想要html或者pdf格式输出,在结尾处close可以节省系统资源;
六、总结
SAS9易错点总结:
这里的总结是考前最后一遍刷50题,70题,120题,220题,主要总结了自己未掌握牢固的知识点,每个童鞋的情况不一样,只做借鉴。
220题第12章
proc步里不能使用keep和drop选项,但是可以使用keep=,drop=选项
data步在程序结尾将变量输出到sas数据集中,
220题第13章
proc import datafile="c:\sas\abc.xlsx" out=b DBMS=EXCEL replace;
SHEET="sheet_name";
RANGE="sheet-name$UL:LR";
run; 注:SHEET 和 RANGE不用加特殊符号都可以识别中文字符;
默认情况下IMPORT过程将电子表格第一行作为变量的名称,若不想这样做可以使用:GETNAMES=NO;
当excel一列中同时包含数值和字符,默认情况下,数值被转换成缺失值,为了将数值读为字符型使用:MIXED=YES;
sas函数
int()
round()
PROC FREQ DATA=mydata NLEVELS;
TABLE name age;
run;选项NLEVELS指出在table中出现的变量中有几个水平。
用小数据集测试程序,只读取部分数据,
- 在INFILE中写OBS=100,或者FIRSTOBS=100 OBS=200;
- Data步中用set语句读取sas数据集时也可以限制观测数,可以在set、merge、update语句中使用OBS= FIRSTOBS=;
DATA a;
Set cats(OBS=100);
Run;
修复无效数据
Data步里使用putlog=_all_;或者putlog var1= var2= var3=;
50T.27 50T.40 50T.41 50T.48
123T.7(当源文件中数值变量带$时候,若从$开始读取数据且不加读入格式,则读出的数据为缺失值,若从$下一个字节开始读数据,则读入的是数值数据)
123T.8使用input读取源文件时,当读完一个字节时,指针自动指到下一个字节位置;
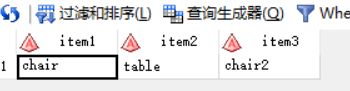
123T.12 infile中使用dlm=’,’时,源文件中连续两个逗号分隔符视为一个分隔符,data步继续读取下一个变量。当定义3个,且源文件中第一行有两个逗号分隔符,则第三个变量继续读取下一行的值;如下:
data a;
infile cards dlm=',';
input item1 $ item2 $ item3 $;
cards;
chair,,table
chair2,couth,table
;
run;
123T.19 rename
123T.34 data步里如果没有file只有put则输出在log里,若同时有put和file则输出为源文件,此时若想输出到log使用putlog=_all_
123T.38 data步里,使用set语句和do语句,观测数量是原set数据集的数量乘以do做的循环次数;
123T.39 当一个变量在input中未标识由多个空格组成时,data在读取时还是按空格分隔符读取,如下:
data homework;
infile datalines ;
input name $ age height;
if age LE 10;
datalines;
aa cc 35 71
bb dd 10 43
cc ee 9 37
;
run;
123T.41 123T.47 123T.57(if和do的用法)
data a;
a=intnx('year','05feb2010'd,3,'E');
format a mmddyy10.;
run;
123T.79将数值型变量变为字符变量时,字符长度变为12个字节,并且是右对齐;
123T.80-81,将字符变量变成数值和将数值变量变成字符;
123T.84
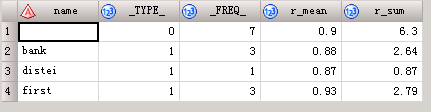
proc means data= bank;
class name;
var rate;
output out=sta mean(rate)=r_mean
sum(rate)=r_sum;
run;程序运行结果:
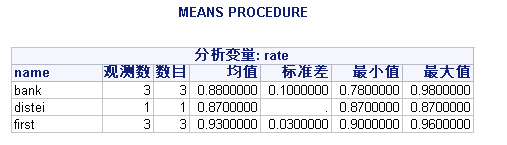
输出数据集out=sta的结果:
correctly invokes the DATA Step Debugger
data WORK.TEST / debug;
set WORK.PILOTS;
State=scan(cityState,2,' ');
if State='NE' then description='Central';
在编译阶段count的值赋值为0;
data WORK.NEW;
set WORK.OLD;
Count+1;
Total的初始值是缺失值;
data WORK.TOTAL_SALARY;
retain Total;
set WORK.SALARY;
by Department;
if First.Department
then Total=0;
Total=sum(Total, Wagerate);
if Last.Total;
run;
自定义的格式是存储在SAS catalog里面的;
These formats must be stored in the WORK.FORMATS or SASUSER.FORMATS catalog
70T.41
A. FullName=CATX(' ',EmpFName,EmpLName);
B. FullName=CAT(' ',EmpFName,EmpLName);
run;
SAS9.4总结:
SASBase的认证考试截止时间到2019.9.30,但目前为止英文版的SASBase9认证在中国已经没有考点了。并且在2019.9.30日将全部取消Base9的认证,统一改为SAS 9.4的认证。sas9和sas9.4考试有很大区别,很多第一次考sas9.4的同学都挂了。我比较幸运考过了,准备考证的同学可以一起交流。