sequelize指引手册2020(包含自动生成models)
笔者最近使用koa2 + mySQL + ts写后台,使用sequelize作为orm语言,虽然是第二次使用,但是由于场景和设备更换,搜索引擎得到的资料分散等等问题,使用sequelize时还是发生了一系列不愉快的事情,掉了很多坑,以此作为一个完整的记录,希望之后大家都少踩一些坑。可能后期为了便于搜索,还是会把这篇博客再拆出几篇来。
注意⚠️:笔者使用的是mysql,下边一些sequelize安装配置的操作对齐的都是mysql
什么是orm,什么是sequelize,为什么使用它?
- 首先ORM是一个缩写【O->Object,RM->Relational (关系) Mapping(映射)】,它是一种把数据库映射成对象的手段,然后我们就可以通过操作对象去达到间接操作数据库的目的。
- 它的优势是不需要去直接接触SQL,但是遇到很复杂的查询时性能会比较差,但是一般情况使用起来还是没有问题的。
- sequelize就是nodejs的一种orm框架,还有一些其他的框架诸如TypeORM,ORM2,目前star数量最多的就是sequelize
sequelize的初步使用
安装:
$ npm install --save sequelize
$ npm install --save mysql2
sequelize连接数据库,以及连接位置
建议把数据库的信息抽离成配置文件,修改以及多人协同开发会方便一些:
// config.ts
exports const config = {
database: {
dbName: 'management',
host: 'localhost',
port: 3306,
user: 'root',
password: '12345678'
}
}
连接数据库:
// db.js
import { Sequelize } from 'sequelize';
import { config } from './config';
const { dbName, host, port, user, password } = config;
export const sequelize = new Sequelize(dbName, user, password, {
dialect: 'mysql',
host,
port,
logging: true,
timezone: '+08:00',
define: {
// create_time && update_time
timestamps: true,
// delete_time
paranoid: true,
createdAt: 'created_at', //自定义时间戳
updatedAt: 'updated_at',
deletedAt: 'deleted_at',
// 把驼峰命名转换为下划线
underscored: true,
pool: {
max: 5,
min: 0,
acquire: 30000,
idle: 10000
},
/* scopes: {
bh: {
attributes: {
exclude: ['password', 'updated_at', 'deleted_at', 'created_at']
}
},
iv: {
attributes: {
exclude: ['content', 'password', 'updated_at', 'deleted_at']
}
}
} */
}
})
注: 如果使用的是vscode,可以在插件那里找一个mysql,安装后按照指引可以在vscode直接操作数据库的数据字段等,懒癌星人必备。
sequelize-automate自动映射
- 连接数据库后,第一步就需要建立对应的Model,很多文档教手写model,但是每个字段就要定义类型、默认值、是否为NULL、字段名等,表中字段越多就越麻烦,我还是偏好自动生成model,而sequelize-automate所作正是连接数据库,并从数据库中读出所有表,生成对应的模型文件。
- 去年第一次使用的时候我选择的是sequelize-auto,但是更换设备后安装依赖后一直有sequelize-auto找不到的情况,网上找了很多解决办法也无济于事,可能是sequelize-auto本身也太过年久失修,打算开始手写model时,刚好找到了它——sequelize-automate!而且它还支持ts!!
下边比较官方的功能特性,可以看一看:
支持 MySQL / PostgreSQL / Sqlite / MariaDB / Microsoft SQL Server 等 Sequelize 支持的所有数据库
支持生成 JavaScript / TypeScript / Egg.js / Midway.js 等不同风格的 Models,并且可扩展
支持主键、外键、自增、字段注释等属性
支持自定义变量命名、文件名风格
接下来介绍使用方法:
第一种使用方法:
- 安装:
npm install sequelize-automate --save
到这里还需要安装使用的数据库对应的依赖包,前边连接数据库时我们已经安装过了,这里跳过。 - 在package.json的script中加一条:
"scripts": {
"sequelize-automate": "sequelize-automate -t ts -h localhost -d test -u root -p root -P 3306 -e mysql -o models"
},
解释一下上述sequelize-automate 命令的参数含义:
–type, -t 指定 models 代码风格,当前可选值:js ts egg midway
–dialect, -e 数据库类型,可选值:mysql sqlite postgres mssql mariadb
–host, -h 数据库 host
–database, -d 数据库名
–user, -u 数据库用户名
–password, -p 数据库密码
–port, -P 数据库端口,默认:MySQL/MariaDB 3306,Postgres 5432,SSQL: 1433
–output, -o 指定输出 models 文件的目录,默认会生成在当前目录下 models 文件夹中
–camel, -C models 文件中代码是否使用驼峰发命名,默认 false
–emptyDir, -r 是否清空 models 目录(即 -o 指定的目录),如果为 true,则生成 models 之前会清空对应目录,默认 false
–config, -c 指定配置文件,可以在一个配置文件中指定命令的参数
- 最后是生成model的命令:
npm run sequelize-automate
第二种使用方法:
- 全局安装sequelize-automate, mysql2
- 抽离一个配置文件:
// sequelize-automate.config.json
{
"dbOptions": {
"database": "management",
"username": "root",
"password": "12345678",
"dialect": "mysql",
"host": "localhost",
"port": 3306,
"logging": false
},
"options": {
"type": "ts",
"dir": "models"
}
}
// 或者
exports default const config = {
dbOptions: {
database: "management",
username: "root",
password: "12345678",
dialect: "mysql",
host: "localhost",
port: 3306,
logging: false
},
options: {
type: "ts",
dir: "models",
tsNoCheck: false, // 是否添加 `@ts-nocheck` 注释到 models 文件中
}
}
如果报错:SequelizeConnectionRefusedError: connect ECONNREFUSED 127.0.0.1:3306
在sequelize-automate和db配置的字段里加上dialectOptions试试
dialectOptions: {
socketPath: '/tmp/mysql.sock' // 指定套接字文件路径
}
其他参数配置看这里:options
3. 最后通过sequelize-automate -c sequelize-automate.config.json 使用。
注: ⚠️在没有写主键时,我这边使用ts生成是没有问题的,但是有主键之后再次生成ts会有同样一行报错,这里给出我这边的改动办法:

- 图中圈起来这个 本来是
type: 'BTREE',改成using: BTREE'后就好了 - 也可以粗暴一点,在配置sequelize-automate时的options中:
tsNoCheck: true
sequelize的增删查
增create,findOrCreate
create的如果是唯一的数据,在create之前一般建议进行一个判重操作,就是在create之前findOne,这种情况使用的即是 findOrCreate
findOrCreate:
// findOrCreate
// 检查项目名称是否重复,如果不重复项目表中插入新建的项目
await projectModel.findOrCreate({
where: {
proName,
},
defaults: {
proName: info.pro_name,
proDescrible: info.pro_describe,
creator: uId,
},
})
.spread((projects, created) => {
console.log(created);
if (created) { // true为添加成功
return ctx.body = { code: 200, msg: '添加项目成功!' };
} // false已经存在
return ctx.body = { code: 403, msg: '项目名称重复' };
});
};
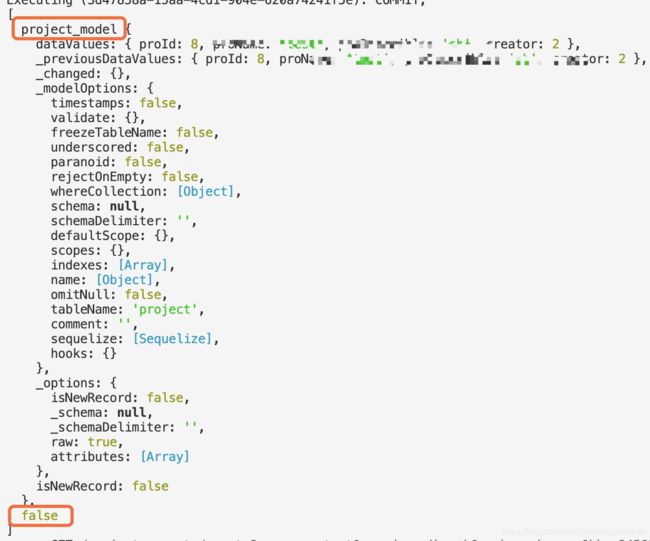
findOrCreate后打印的结果是这样的:
- 可以拿某个字段(假设是data)取接,用下标0和1取,data[1]就是是否添加成功
- 也可以像上边代码用
.spread((projects, created)的第二个参数取到
create:
await relationModel.create({ proId: project_id.proId, uId: uer_id });
删除
/* 删除数据库中对应article_Id的内容 */
await fileModel.destroy({
where: {
article_Id: req.article_Id,
},
});
这里注意一点 如果是想用来删除文件,不仅需要删除数据库内的记录,还要附加真实删除文件的操作。
简单查询findOne findAll find findAndCountAll
Model.findAll({
where: { // 过滤查询(相当于是筛选条件
authorId: 2
},
attributes: ['foo', 'bar'], // 选择展示的属性
raw: true,
});
- 如果去掉
raw: true,查询到的结果就是处理过的模型,如果想对其操作需要在参数中添加raw: true,返回的则是一个没有被包装过的数组了。 - 顾名思义,findOne是在数据库中找到一个合适的结果,findAll是找到一个集合
- 如果直接用findAll,随着数据量的增加查询速度会越来越慢,而使用分页操作就可以完美解决这个问题,由前端传递页码和每页的数量,每次数据库只处理一定数量的数据,压力减轻了不少。
- 分页操作时一般用到的是findAndCountAll,虽然在findAll之后加上limit和offset也可以控制查询条数和查询位置,但是findAndCountAll则可以查询到总数以及条件范围内的数据,一举两得。查询结果返回的是一个包括总数(cout)和数据(rows)的json对象。
await fileModel.findAndCountAll({
where: {
proId,
fileType,
},
limit: pageSize,
offset: current*pageSize, // 第x页*每页个数 // 前端提供
raw: true,
});
关联表查询情况
关联表进行查询这块尝试了网上许多方法,生成的sql和理解还是不太一样,比如说尝试了belongsTo,在find之前先用hasMany或者hasOne关联表,但是生成的sql的连接条件就是将两张表的主键相等;但是我这里的业务需求是连接fileModel表和relationModel表后,连接条件是fileModel里的proId和relationModel的proId相等(并不是主键),然后取出符合条件的文件。
export const dispalyList = async (uId, proId, fileType) => await fileModel.findAndCountAll({
include: [{
/* 关联写到外面就会默认两个主键进行等值连接 */
association: fileModel.hasMany(relationModel, {
foreignKey: 'proId',
sourceKey: 'proId',
/* 指定别名的时候一定要把单数和复数形式都指定了要不然就会报错了 */
as: {
singular: 'relation',
plural: 'relations',
},
}),
where: { uId },
attributes: [],
}],
where: {
proId,
fileType,
},
raw: true,
});
- 关于hasMany和hasOne的差别:只是显示的差别 用 hasOne 会得到展开的数据,用 hasMany 会得到一个数组,需要自己去展开。
- hasmOne

hasone - as字段是指定关联表(relationModel)的别名,舍去会报错,这里需要注意的是单数形式和复数形式的别名都需要写上,否则就会有一个离奇的坑——第一遍查询正常,第二遍就会报错。
- 上边代码中where的位置不同,查询的结果是不一样的,因为对应筛选的表是不一样的。
复杂查询情况(这里是一个搜索功能)
list = await projectModel.findAll({
include: [
{
/* 关联写到外面就会默认两个主键进行等值连接 */
association: projectModel.hasMany(relationModel, {
foreignKey: 'proId',
sourceKey: 'proId',
/* 指定别名的时候一定要把单数和复数形式都指定了要不然就会报错了 */
as: {
singular: 'relation',
plural: 'relations',
},
}),
where: { uId },
attributes: [],
},
],
// attributes: [ "proId", "proName", "creator" ],
where: {
// 模糊查询
proName: {
[Op.like]: `%${req.search_info}%`,
},
},
/* attributes起别名的方法————前面是数据库字段原名,后边是别名 */
attributes: [['proName', 'name'], ['proId', 'project_id']],
});
} else {
list = await fileModel.findAll({
include: [{
/* 关联写到外面就会默认两个主键进行等值连接 */
association: fileModel.hasMany(relationModel, {
foreignKey: 'proId',
sourceKey: 'proId',
/* 指定别名的时候一定要把单数和复数形式都指定了要不然就会报错了 */
as: {
singular: 'relation',
plural: 'relations',
},
}),
where: { uId: 2 },
attributes: [],
}],
where: {
fileName: {
[Op.like]: `%${req.search_info}%`,
},
fileType: req.search_type,
},
attributes: [['fileName', 'name'], ['proId', 'project_id']],
});
}