CUDA 进阶编程 Thrust库使用-vector
文章目录
- Thrust库的介绍
- Vector
- 简单示例
- 底层实现
- 使用技巧
- 利用vector传输数据
- 不要一个个的复制数据
Thrust库的介绍
thrust是NVIDIA推出的一个高性能的GPU版本并行开发库,thrust提供了丰富的算法和容器, 我们可以使用这些工具来简化我们的编程
thrust的库的API都是STL like的, 对于STL比较熟悉的人学习起来会比较简单, 当然thrust库提供了很多C++11和C++17 风格的接口,如果对于C++11 和 C++17 不熟悉的人学习起来还是有点吃力,推荐在学习thrust库前先把C++11 和 C++17的库学习下, thrust库提供的不过都是这些接口的并行版本
C++参考网页
thrust库虽然提供了高性能的接口,帮我们简化了很多代码,但是本质上还是依赖于CUDA的底层那套机制,无非是cudaMemcpy之类的, 所以在实际项目中,推荐还是要会这一套接口, 否则在使用的过程中, 但是很容易写出低效的版本
Vector
vector是thrust最基础也是最简单的容易,分为host_vector和device_vector
host_vector就是指在CPU和内存里面的数据
device_vector就是指GPU里面的数据
vector提供iterator进行遍历等操作, 所有thrust的容器都支持迭代器
简单示例
#include 上面只是一个简单的示例, 可以看到基本跟我们使用STL的vector差不多, 但是内部实现不同
底层实现
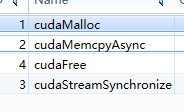
上面的图片是跑了示例后用Nsight查看的结果, 可以看到vector还是使用cudaMalloc和cudaMemcpyAsync来进行操作的, 所以在使用这些库之前,还是要先了解下这些函数
使用技巧
利用vector传输数据
之前自己用CUDA传输数据的时候,都要用cudaMalloc和cudaMemcpy, cudaFree等一系列函数, 非常麻烦,使用vector后, 可以简化这些数据的传输
thrust::device_vector<int> D = H;
thrust::device_ptr<int> p = D.data();
不要一个个的复制数据
D[0] = H[0];
D[1] = H[1];
这段代码如果在之前的STL是没问题的,数据量少的时候也没问题, 但是因为D是device_vecto, 开辟的是显存,H是host_vector, 开辟的是内存, 这里将会触发2次内存拷贝, 在数据量多的时候,效率会非常低, 非常不建议这样内存, 建议内存还是一次性拷贝好, 直接调用 = 就只会调用一次