深度之眼Paper带读笔记NLP.3:句和文档的embedding
文章目录
- 前言
- 第一课 论文导读
- 句子分布式表示简介
- 句子分布式表示:
- 历史模型 History Model
- Bag-of-words Model
- 加权平均法Weighted Averaging Method
- 深度学习模型Deep Learning Model
- 子分布式表示相关方法
- 前期知识储备
- 第二课 论文精读
- 论文整体框架
- 传统/经典算法模型
- 基于语言模型的词向量训练Word Embedding with Language Model
- 论文提出改进后的模型
- 分布式句向量训练模型
- 无序句向量训练模型Paragraph Vector without Word ordering
- 实验和结果
- 数据集
- 实验结果
- 讨论和总结
- 讨论
- 总结
- 第三课时:代码精读
- 学习方法
- 任务定义:
- 数据来源:
- 运行环境:
- 运行结果:
- 如何实现:
- 论文代码:
- 准备工作
- 数据预处理
- 切词
- 统计单词并构建词表
- 编号表示
- 窗口数据集构建
- 训练模型
- 运行过程
- 训练结果
- 测试模型
- 讨论与总结
前言
本课程来自深度之眼,部分截图来自课程视频。
文章标题:Distributed representations of sentences and docments
句子和文档的分布式表示学习
作者:Quoc Le and Tomas Mikolov
单位:Google
发表会议及时间:ICML2014
在线LaTeX公式编辑器
基于TensorFlow的代码复现:https://github.com/pvop/NLP_Paper_Projects
第一课 论文导读
a. 分布式句子表示概念和几种传统方法
分布式句子表示就是将句子表示成向量,这个向量能够包括句子中词的语法和句子的语义信息。介绍了两类句子分布式方法,一种是Bag-of-words也就是词袋模型,还有一种就是基于词向量的方法。
b. 词向量以及其学习到的语法和语义特征的含义
词向量就是将一个词映射成一个连续空间中的向量,其中使用word2vec等方法学习到的词向量可以学习到词的语法和语义信息,语法信息就是将动词聚集在一块,名词聚集在一块。而语义特征就是将语义近的词聚集在一块,比如powerful和strong,并且还有更加独特的性质,king的词向量减去queen的词向量等于man的词向量减去woman的词向量。
c. 基于语言模型的词向量学习方法
使用语言模型学习词向量是2003年Bengio的文章,其中通过预测下一个词的任务来学习到每个词的词向量并且学习到一个非常好的语言模型。本次讲解的论文也是根据这个模型改进的,而且之后需要讲的ELMO,BERT等都是基于语言模型的
句子分布式表示简介
文档可以看做是很长的句子,所以,把句子的分布式表示弄明白后,文档的分布式表示自然就没问题了。
句子分布式表示:
句子的分布式表示就是将一句话或者一段话(本次课程将句子和文档同等看代,文档相当于较长的句子)用固定长度的向量表示。
意义:如果能够用一个向量准确地表示一句话,那么可以直接用这个向量用于文本分类、信息检索、机器翻译等等各个领域。

历史模型 History Model
基于统计的句子分布式表示
1、Bag-of-words
2、Bag-of-n-grams
基于深度学习的句子分布式表示
1.加权平均法
2.深度学习模型
Bag-of-words Model
算法:
1.构建一个词表,词表中每个元素都是一个词。
2.对于一句话s,统计词表中每个词在s中出现的次数。
3.根据词表中每个词在s中出现的次数,构造一个词表大小的向量。
对于Bag-of-n-gram,词表中的元素可以为词也可以为n-gram短语。
思考:Bag-of-words的缺点,并思考如何改进。
答:当词表很大(看训练语料的大小),得到的向量就很大,一般如果语料很大,但是我们要处理的文档不会用到语料库中所有的词,或者说有很大一部分的词使用的频率很低,这个时候可以只取出现频率最高的10%-20%的词来构造词表,词表构造好后,用词表来表示某个句子,依然会出现非常稀疏的结果,这个时候可以用到PCA等降维的方法来进行处理。
同班(move)同学的答案:
词袋模型:忽视了词的顺序关系和词语的相似度关系。维度高,容易产生稀疏矩阵
N-gram模型:容易造成维度灾难,无法考虑到全局的上下文关系和词语相似度。
词向量:把单词表示成计算机能处理的形式同时尽量保留原始的文本信息。

上图中形成的向量就是(2,1,1,1,1,1)
加权平均法Weighted Averaging Method
算法:
1.构建词表,词表中每个元素都是词。
2.使用词向量学习方法(skip-gram等)学习每个词的词向量表示。
3.对句子s中的每个词(W1,Wz.…,Wa)对应的词向量(e1,ez…en)加权平均,结果为句子s的分布式表示:
e s = 1 n ∑ i = 1 n e i e_s=\frac{1}{n}\sum_{i=1}^ne_i es=n1i=1∑nei
深度学习模型Deep Learning Model
算法:
1.构建词表,词表中每个元素都是词。
2.使用词向量学习方法(skip-gram等)学习每个词的词向量表示。
3.将句子s中的每个向量作为输入送进深度神经网络模型(CNN or RNN),然后通过监督学习,学习每个句子的分布式表示。
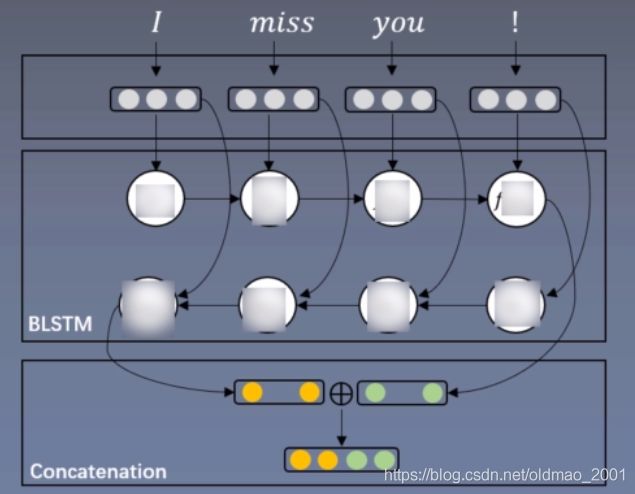
子分布式表示相关方法
前期知识储备
·熟悉词向量的相关知识。
·了解词向量矩阵,以及词向量学习到的语法以及语义信息的含义,参考论文:Efficient Estimation of Word Representations in Vector Space
·了解使用语言模型训练词向量的方法。
·了解通过语言模型来训练词向量的模型(论文A Neural Probabilistic Language Model)。
第二课 论文精读
论文整体框架
摘要
句向量表示的概念和意义。
Many machine learning algorithms require the input to be represented as a fixed-length feature vector.
以往的句向量表示模型以及它的缺点。
When it comes to texts, one of the most common fixed-length features is bag-of-words.
Despite their popularity, bag-of-words features have two major weaknesses: they lose the ordering of the words and they also ignore semantics of the words. For example, “powerful,” “strong” and “Paris” are equally distant.
本文提出的模型和该模型的优点。
In this paper, we
propose Paragraph Vector, an unsupervised algorithm that learns fixed-length feature representations from variable-length pieces of texts, such as sentences, paragraphs, and documents. Our algorithm represents each document by a dense vector which is trained to predict words in the document. Its construction gives our algorithm the potential to overcome the weaknesses of bag-ofwords models.
所提出模型的效果。
Empirical results show that Paragraph Vectors outperform bag-of-words models as well as other techniques for text representations. Finally, we achieve new state-of-the-art results on several text classification and sentiment analysis tasks.
1.介绍
2.句子分布式表示模型
3.实验
4.相关工作
5.结论
传统/经典算法模型
Bag-of-words Model:见上节
Bag-of-words模型缺点:
1.因为是词袋模型,所以丢失了词之前的位置信息
2.句向量只是单纯地利用了统计信息,而没有得到语义信息,或者只得到很少的语义信息。
Bag-of-n-grams模型缺点:
1.因为使用了n-gram,所以保留了位置信息,但是n-gram不会不太大,最多是4-gram,所以只保留了很少的位置信息。
2.N-gram同样没有学习到语义信息。
加权平均法:见上节
加权平均法缺点:对所有的词向量进行平均、丢失了词之前的顺序信息以及词与词之间的关系信息。例如:not bad只学习到bad,把not忽略掉了
深度学习模型缺点:只能使用标注数据训练每个句子的句向量,这样训练得到的向量都是任务导向的,不具有通用性。
基于语言模型的词向量训练Word Embedding with Language Model
语言模型:语言模型可以给出每个句子是句子的概率:(一句话的概率=词的概率相乘)
P ( s ) = ∏ i = 1 T P ( w i ) P(s)=\prod _{i=1}^TP(w_i) P(s)=i=1∏TP(wi)
而每个词的概率定义成n-gram形式,即每个词出现只与前n-1个词有关:(马尔科夫假设)
P ( w t ) = P ( w t ∣ w t − n + 1 t − 1 ) P(w_t)=P(w_t|w_{t-n+1}^{t-1}) P(wt)=P(wt∣wt−n+1t−1)
评价语言模型好坏的指标困惑度(perplexity):
P P ( s ) = 1 P ( s ) T PP(s)=\sqrt[T]{\frac{1}{P(s)}} PP(s)=TP(s)1
P P ( s ) = e − 1 T ∑ i = 1 T l o g P ( w i ) PP(s)=e^{-\frac{1}{T}\sum_{i=1}^TlogP(w_i)} PP(s)=e−T1∑i=1TlogP(wi)
算法:
1.对于每个词随机初始化一个词向量。
2.取得一个句话连续的n-1个词,将这n-1个词对应的词向量连接(concatenate)在一起形成向量e。
3.将e作为输入,送入一个单隐层神经网络,隐层的激活函数为tanh,输出层的神经元个数为词表大小。
优点:就像原文中提到的,即训练出一组词向量,又得到了一个语言模型。其次是不需要标注数据,可以使用很大的数据集。
论文:A Neural Probabilistic Language Model
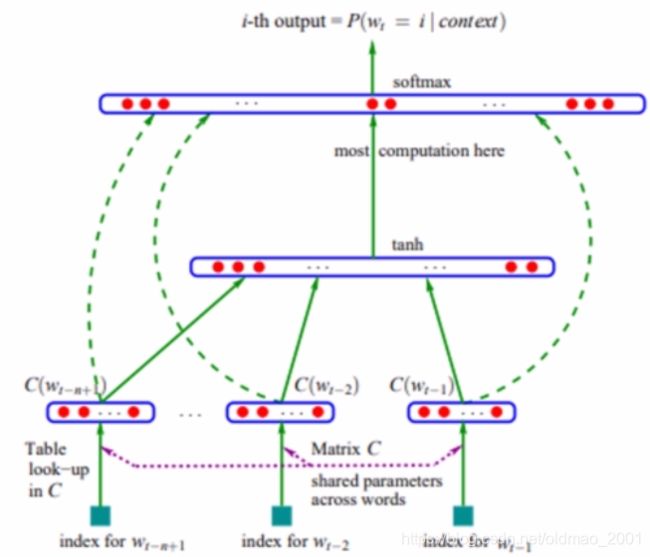
论文提出改进后的模型
分布式句向量训练模型
Distributed Sentence Embedding Training Model
算法:
1.类似于前面提到的基于语言模型的词向量训练模型,这里的句向量训练模型也是利用前几个词预测后一个词。
2.不同的是,这里将每句话映射成一个句向量,联合预测后一个词出现的概率。
这样就学习到了每个词的词向量和每句话的句向量。
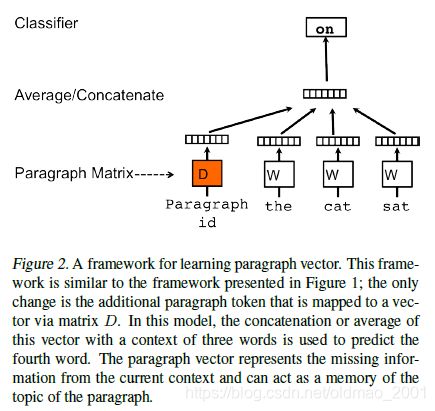
训练阶段:
通过训练集构建词表,并随机初始化词向量矩阵W和训练集的句向量矩阵D。设置n-gram,文中为窗口大小(文中用的10),然后利用句向量训练模型训练矩阵模型的所有参数,包括词向量矩阵和句向量矩阵。最后将学习到的句向量用于分类器预测句子的类别概率。
测试阶段:
固定词向量矩阵W和模型的其他参数,重新构建句向量矩阵D并随机初始化,然后利用梯度下降训练矩阵D,从而得到测试集每个句子的句向量。
然后利用句向量矩阵,以及刚才的模型来得到测试集的结果(正确分类或错误分类的结果)。
无序句向量训练模型Paragraph Vector without Word ordering
文本还提出了一种Bag-of-words,即忽略词序信息的模型。
算法:每个句子通过随机初始化句向量矩阵映射成一个句向量,然后通过句向量每次随机预测句子中的一个词。
然后将学习到的句向量送到已经训练好的分类器,预测句子的概率。
本文分别使用提出的两种模型训练得到两个句向量,然后将两个句向量合并(concatenate),得到最终的句向量表示。
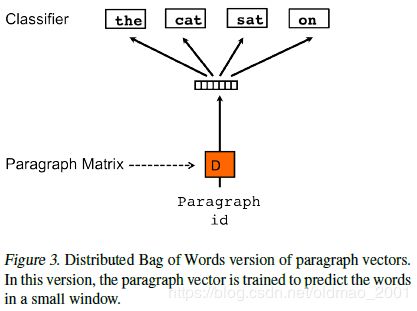
上图中虽然显示了四个词,但是实际上每次只预测一个词。
实验和结果
数据集
SST:斯坦福提供的情感分析数据集(0-1之间的情感值,这里可以是二分类:0-0.5,0.5-1,也可以是多分类:0-0.2,0.2-0.4,…0.8-1),其中训练数据8544条,测试数据2210条,验证数据1101条,其中还包括将所有数据转化为短句共239232条。
IMDB:IMDB的评论数据,其中训练集25000条,12500条正例,12500条负例。测试集25000条,12500条正例,12500条负例。还有50000条未标注数据。(本次复现选择这个数据集)
评价方法:SST数据集可以根据情感值分为5类,采用的分类器是Logistic回归,也可以分为两类,评价指标就是预测情感类别的错误率,越低越好。IMDB数据集是一个二分类任务,采用的分类器是单隐层神经网络,评价指标为预测情感类别的错误率,同样越低越好。
实验结果
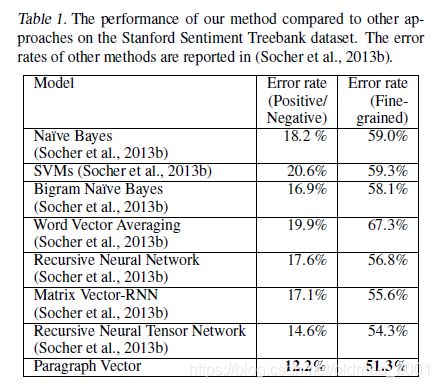
上图中,第二列为二分类结果,第三列为五分类结果,实验结果显示本文提出的句向量方法优于朴素贝叶斯,SVM,词向量平均法已经神经网络方法,在二分类和五分类任务都取得了state-of-the-art的结果。
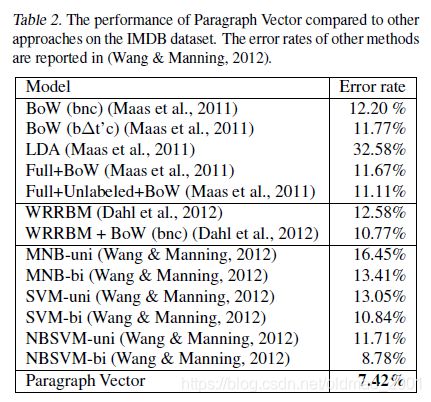
IMDB的实验结果,句向量模型的结果也取得了state-of-the-art的结果。
讨论和总结
讨论
目前主流的句向量表示方法?
基于神经网络的句向量学习方法,使用预训练的词向量已经神经网络可以得到非常好的句向量表示。
测试过程还需要训练,大大降低了效率?
是的,所以使用基于神经网络的句向量学习方法,当前流行的ELMO,BERT。
是否有其他句向量训练方法?
后人提出基于seq2seq模型的句向量训练方法。
总结
A提出了一种新的无监督的句向量训练方法。
B可以直接用于下游任务。
C在论文发表的时候取得了SOTA结果。
第三课时:代码精读
学习方法
任务定义:
搞清楚程序的目的是什么
为了实现什么任务
数据来源:
源码获取渠道
数据集类型
数据集的来源:
论文中包括SST和IMDB两个数据集的实验
复现使用的是IMDB,下载地址:https://www.kaggle.com/iarunava/imdb-movie-reviews-dataset,2w5千个训练记录(一半是正样本,一半是负样本),2w5千个测试记录(一半是正样本,一半是负样本),5w个未标注样本。每个记录都单独放在一个txt中
运行环境:
运行环境:TensorFIow版本:1.8以上;Linux环境运行;推荐使用GPU;Python版本:3.5
实验工具
第三方库
运行结果:
能否运行成功
运行代码后出现什么样的结果
结果的形式是什么
如何实现:
代码整体架构
每部分实现细节
论文代码:
·导师自己使用tensorflow编写
·只有三个文件,分别是数据读取(get_all_data.py),模型(model.py)和主函数(main.py)
准备工作
数据预处理
语料的预处理过程
1切词
使用nltk工具将文档切分成一个一个的词。不能用空格来切词,I’m,(),等用空格切不开,直接用nltk工具来切。
2统计单词
统计语料中出现的单词频率并根据频率构建词表。
3分配ID
为每一个单词分配一个ID
4编号表示
将程序所需数据集文本转化为用单词编号的形式表示
5窗口数据集构建
按照窗口大小构建本次模型训练所需要的数据集。
切词
切词:将一段话切分成一个个的词
I’m a good man!What about you?
I,‘m,a,good,man,!,What,about,you,?
def get_data(self, path):
datas=[]
paths=os. listdir(path)
paths=[ path +file_name for file_name in paths]
for i, file in enumerate(paths):
if i%1000==0: #每读1000个输出一下
print(i, len(paths))
data=open(file,"r").read()
data=data.lower()#把单词都转为小写
data=nltk.word_tokenize(data)#把一句话按上面的例子切成词
datas.append(data)
return datas
统计单词并构建词表
使用统计所有的词,然后使用collections的Counter统计每个词的频率,然后构建一个含有30000个词的词表,其中包含pad字符和unk字符。
def get_all_words(self, train_datas, train_unsup):
all_words=[]
for sentence in train_datas:
al_words.extend(sentence)
for sentence in train_unsup:
all_words.extend(sentence)
count=Counter(all_words)
count=dict(count. most_common(29998))
word2id={"":0,"":1}#pad是补0字符,unk是其他频率低的词
for word in count:
word2id[word]=len(word2id)#根据词表长度递增进行编号
return word2id
编号表示
将所有文本中的词利用构建的词表转化为编号
I,'m,a,good,man,!,What,about,you,!
23,67,1789…,7543,3620,7350
def convert_data_word_to_id(self, word2id, datas):
for i, sentence in enumerate(datas): #使用enumerate可以返回两个变量
for j, word in enumerate(sentence):
datas[i][j]=word2id.get(word,1)
return datas
窗口数据集构建
直接偷懒贴老师的代码
def convert_data_to_new_data(self,datas):
'''
根据句子生成窗口大小为10的语言模型训练集,当句子长度不够10时需要在前面补pad。
:param datas: 句子,可以只使用训练句子,也可以使用训练句子+无监督句子,后续需要训练更久。
:return: 返回窗口大小为10的训练集,句子id和词标签。
'''
new_word_datas = []#词的编号
new_papr_datas = []#句子的编号,
new_labels = []#每次预测的值
for i,data in enumerate(datas):
if i%1000==0:
print (i,len(datas))
for j in range(len(data)):
if len(data)<10: # 如果句子长度不够10,开始pad
tmp_words = [0]*(10-len(data))+data[0:-1]
if set(tmp_words)=={1}: #同样,连续9个词都是unk就舍去,连续9个unk意味着这个预测没有啥意义
break
new_word_datas.append(tmp_words)
new_papr_datas.append(i)
new_labels.append(data[-1])
break
tmp_words = data[j:j+9]#句子中有超过10个词,则继续往后处理
if set(tmp_words)=={1}: # 开始发现存在连续出现unk的句子,这种句子没有意义,所以连续9个词都是unk,那么就舍去
continue
new_papr_datas.append(i)
new_word_datas.append(tmp_words)
new_labels.append(data[j+9])
if j+9+1==len(data): # 到最后10个单词break
break
new_word_datas = np.array(new_word_datas)
new_papr_datas = np.array(new_papr_datas)
new_labels = np.array(new_labels)
print (new_word_datas.shape)
print (new_papr_datas.shape)
print (new_labels.shape)
return new_word_datas,new_papr_datas,new_labels
训练模型
def create_placeholder(self):
'''
创建图的输入placeholder
self.word_input: n-gram前n-1个词的输入
self.para_input:篇章id的输入
self.word_label: 语言模型预测下一个词的词标签
self.label:这句话属于正类还是负类的类别标签
:return:
'''
self.word_input = tf.placeholder(dtype=tf.int32,shape=[None,self.window-1])
self.para_input = tf.placeholder(dtype=tf.int32,shape=[None,1])
self.word_label = tf.placeholder(dtype=tf.int32,shape=[None])#连续了9个词预测第10个词是什么
self.label = tf.placeholder(dtype=tf.int32,shape=[None])
构建完占位符,下面看如何使用他们
with tf.variable_scope("train_parameters"):#定义区域
self.train_para_embedding = tf.Variable(initial_value=tf.truncated_normal(shape=[self.para_num,400]), trainable=True,name="train_para_embedding")#训练句向量,这里主要是shape,这里文章用的句向量和词向量都是400维度,self.para_num是句子数量,trainable=True代表是否可以更新参数
self.word_embedding = tf.Variable(initial_value=tf.truncated_normal(shape=[30000,400]),
trainable=True,name="word_embedding")#训练词向量,这里的shape中用了30000个词
with tf.variable_scope("test_parameters"):
self.test_para_embedding = tf.Variable(initial_value=tf.truncated_normal(shape=[25000,400]),trainable=True,name="test_para_embedding")#定义测试的句向量,它的shape是25000*400,(测试集有25000个数据)
if train_first or train_second:#train_first 是训练句向量和词向量,train_second的时候,句向量和词向量是固定不变的。训练分类器
para_input = tf.nn.embedding_lookup(self.train_para_embedding, self.para_input) # batch_size*1*400,,train_para_embedding是根据编号从一行的向量把句向量矩阵或者词向量矩阵找出来,然后concat到一块
else:#上面是用训练集得到para_input ,这里是用测试集。
para_input = tf.nn.embedding_lookup(self.test_para_embedding,self.para_input)
word_input = tf.nn.embedding_lookup(self.word_embedding,self.word_input) #batch_size*9*400
接下来把9个词向量和一个句向量concat到一块
input = tf.concat([word_inut,para_input],axis=1) #batch_size*10*400,axis=1代表第二个维度的concat,相当于9+1,变成10个词
input = tf.layers.flatten(input) #batch_size*4000#把上面的结果flatten变成10*400=4000
with tf.variable_scope("train_parameters"):
output = tf.layers.dense(input,units=30000,name="word_output")#预测,用的是30000维的分类,这里不做softmax是因为下面有一个地方已经做了softmax,原文由于当时的算力不足,用了分层的softmax,现在可以不用分层了,直接弄
labels = tf.one_hot(self.word_label,30000)#独热编码生成label
train_var = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,"train_parameters")
test_var = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,"test_parameters")
reg = tf.contrib.layers.apply_regularization(tf.contrib.layers.l2_regularizer(1e-10), tf.trainable_variables())
self.loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels,logits=output))+reg
self.train_op = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(self.loss_op,var_list=train_var)
self.test_op = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(self.loss_op,var_list=test_var)
下面是分类器的训练
mlp_input = tf.reshape(para_input,[-1,400])
with tf.variable_scope("classification_parameters"):#定义分类器的参数
h1 = tf.layers.dense(mlp_input,units=50,activation="relu",trainable=True,name="h1")
mlp_output = tf.layers.dense(h1,2,trainable=True,name="mlp_output")#2代表2分类
mlp_labels = tf.one_hot(self.label,2)
self.mlp_loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=mlp_labels,logits=mlp_output))#这里已经带上了softmax,上面就不用加softmax层
classification_var = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "classification_parameters")
self.mlp_train_op = tf.train.AdamOptimizer(learning_rate=0.02).minimize(self.mlp_loss_op,var_list=classification_var)
self.predict_op = tf.argmax(mlp_output,axis=1)
运行过程
训练训练集句向量和词向量,这里可以使用标注的训练集(25000条),也可以用标注的训练集+未标注的训练集(共75000条),论文中用的后面那种。
测试集句向量
训练分类器训练:复现时为了验证效果,从25000条训练集中分出5000来进行测试查看训练效果。
测试集评估
训练结果
中间的训练结果有保存,所以可以重复训练,每次是10轮,训练过程中loss不一定是减小的。
测试模型
def test_mlp(self,sess,para_datas,labels,batch_size):
'''
:param sess: tensorflow的Session
:param para_datas: 所有的测试句子id,大小为25000维的向量
:param labels: 所有的测试句子标签,大小为25000维的向量,用来测试模型结果
:param batch_size: 标量。
:return: 无
'''
index=0
result = []
while index < len(para_datas):
para_data_batch = para_datas[index:index + batch_size]#数据量大的时候要分batch
pred = sess.run(self.predict_op,feed_dict={self.para_input:para_data_batch})
result+=list(pred)
index+=batch_size
acc = accuracy_score(y_true=labels,y_pred=result)
print ("Test acc is:",acc)
训练50轮左右可以得到85%的准确率
讨论与总结
略