Singular Value Decomposition
文章目录
- 1 特征分解(矩阵的基础概念)
- 1.1 相似矩阵
- 1.2 正交矩阵
- 1.3 实对称矩阵
- 1.4 特征值、特征向量
- 1.5 二次型
- 1.6 正定二次型和正定矩阵
- 1.7 特征分解
- 2 SVD 分解
- 2.1 推导
- 2.2 计算一个矩阵的 SVD 形式
- 3 逆矩阵(以最小二乘为例)
- 4 伪逆矩阵(以最小二乘为例)
- 5 最小范数解(以最小二乘为例)
向量矩阵可视化的 demo 可以参考 【python】Linear Algebra
对矩阵进行线性表示,类比泰勒公式!
1 特征分解(矩阵的基础概念)
1.1 相似矩阵
-
定义
设 A , B A,B A,B 都是 n n n 阶矩阵,若存在可逆矩阵 P P P,使得 P − 1 A P = B P^{-1}AP = B P−1AP=B,则称 A A A 相似于 B B B,记 A A A~ B B B. 若 A A A~ Λ \Lambda Λ,其中 Λ \Lambda Λ 是对角矩阵,则称 A A A 可相似对角化, Λ \Lambda Λ 是 A A A 的相似标准型。 -
相似矩阵的性质和矩阵可相似对角化的充要条件,这里不列举了!
1.2 正交矩阵
A T A = A A T = I A^TA = AA^T = I ATA=AAT=I 的矩阵称为正交阵,其中 I I I 为单位矩阵,也即 A T = A − 1 A^T = A^{-1} AT=A−1
1.3 实对称矩阵
实对称矩阵,就是矩阵每个元素 a i j a_{ij} aij 都是实数,且 A = A T A = A^T A=AT
- 定理1:实对称矩阵的特征值全部是实数
- 定理2:实对称矩阵的属于不同特征值对应的特征向量相互正交
- 定理3:实对称矩阵必相似于对角阵(非对角元素都是 0 的矩阵),即存在可逆矩阵 P P P,使得 P − 1 A P = Λ P^{-1}AP = \Lambda P−1AP=Λ,且存在正交阵 Q Q Q,使得 Q − 1 A Q = Q T A Q = Λ Q^{-1}AQ = Q^{T}AQ = \Lambda Q−1AQ=QTAQ=Λ(把 Q 甩过去就是矩阵的特征分解了)
A = ( Q T ) − 1 Λ Q − 1 = ( Q T ) T Λ Q T = Q Λ Q T A=(Q^T)^{_-1} \Lambda Q^{-1} = (Q^T)^T \Lambda Q^T = Q \Lambda Q^T A=(QT)−1ΛQ−1=(QT)TΛQT=QΛQT
1.4 特征值、特征向量
定义
A A A 是 n 阶方阵,如果对于数 λ \lambda λ,存在非零向量 v v v,使得 A v = λ v Av = \lambda v Av=λv,则称 λ \lambda λ 是 A A A 的特征值, v v v 是 A A A 对应于 λ \lambda λ 的特征向量!
我们来升级一下 A v = λ v Av = \lambda v Av=λv,变成如下形式(假设 A 有 n 个线性无关的特征向量):
A V = Λ V AV= \Lambda V AV=ΛV
其中, V = [ v 1 , v 2 , . . . , v n ] V = [v_1,v_2,...,v_n] V=[v1,v2,...,vn] 为特征向量(列向量)构成的矩阵。 Λ = [ λ 1 , λ 2 , . . . , λ n ] \Lambda = [\lambda_1,\lambda_2,...,\lambda_n] Λ=[λ1,λ2,...,λn] 为特征值构成的对角矩阵。
再变形一下:
A = V Λ V − 1 A = V \Lambda V^{-1} A=VΛV−1
如果 A A A 是实对称矩阵,根据 1.3 中的定理2:实对称矩阵的属于不同特征值对应的特征向量相互正交,我们进一步变形下公式:
A = Q Λ Q T A = Q \Lambda Q^{T} A=QΛQT
其中 Q Q Q 是 A A A 的特征向量组成的正交矩阵!
1.5 二次型
n 个变量的一个二次齐次多项式
f ( x 1 , x 2 , . . . , x n ) = ∑ i = 1 n ∑ j = 1 n a i j x i x j f(x_1,x_2,...,x_n) = \sum_{i=1}^n\sum_{j=1}^na_{ij}x_ix_j f(x1,x2,...,xn)=i=1∑nj=1∑naijxixj
称为 n 个变量的二次型,系数均为实数时,称为 n 元实二次型。矩阵表示为 x T A x x^TAx xTAx, A A A 是对称的矩阵, x = [ x 1 , x 2 , . . . , x n ] T x = [x_1,x_2,...,x_n]^T x=[x1,x2,...,xn]T。
[ x 1 , x 2 , . . . , x n ] [ a 11 a 12 . . . a 1 n a 21 a 22 . . . a 2 n . . . . . . . . . . . . a n 1 a n 2 . . . a n n ] [ x 1 x 2 . . . x n ] [x_1,x_2,...,x_n] \begin{bmatrix} a_{11} & a_{12} & ... & a_{1n}\\ a_{21} & a_{22} & ... & a_{2n}\\ ... & ... & ... & ...\\ a_{n1} & a_{n2} & ... & a_{nn} \end{bmatrix} \begin{bmatrix} x_1\\ x_2\\ ...\\ x_n\\ \end{bmatrix} [x1,x2,...,xn]⎣⎢⎢⎡a11a21...an1a12a22...an2............a1na2n...ann⎦⎥⎥⎤⎣⎢⎢⎡x1x2...xn⎦⎥⎥⎤
1.6 正定二次型和正定矩阵
若对于任意的非零向量 x = [ x 1 , x 2 , . . . , x n ] T x = [x_1,x_2,...,x_n]^T x=[x1,x2,...,xn]T,恒有 f ( x 1 , x 2 , . . . , x n ) = x T A x > 0 f(x_1,x_2,...,x_n) = x^TAx > 0 f(x1,x2,...,xn)=xTAx>0,则称二次型 f f f 为正定二次型,对应矩阵为正定矩阵。
f ( x 1 , x 2 , . . . , x n ) = x T A x f(x_1,x_2,...,x_n) = x^TAx f(x1,x2,...,xn)=xTAx 正定,有许多等价的表示,其中一条就是 A 的全部特征值 λ i > 0 \lambda_i > 0 λi>0
1.7 特征分解
本质:原矩阵(方阵)分解成了许多方阵的线性组合(类比泰勒公式)!
对称矩阵一定能特征分解(特别是对称正定矩阵,能保证 λ i \lambda_i λi 都是正数)
A = Q Λ Q T A = Q \Lambda Q^{T} A=QΛQT
设 Q Q Q 为 [ v 1 , v 2 , . . . , v n ] [v_1,v_2,...,v_n] [v1,v2,...,vn],其中 v i ∈ R n v_i \in \mathbb{R}^n vi∈Rn,表示 A A A 的特征向量!
Λ = ( λ 1 λ 2 . . . λ n ) \Lambda =\begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & ... & \\ & & & \lambda_n \end{pmatrix} Λ=⎝⎜⎜⎛λ1λ2...λn⎠⎟⎟⎞,其中 λ i \lambda_i λi 为特征向量 v i v_i vi 对应的特征值。
则
A = [ v 1 , v 2 , . . . , v n ] ( λ 1 λ 2 . . . λ n ) ( v 1 T v 2 T . . . v n T ) = λ 1 v 1 v 1 T + λ 2 v 2 v 2 T + . . . + λ n v n v n T \begin{aligned} A &=[v_1,v_2,...,v_n] \begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & ... & \\ & & & \lambda_n \end{pmatrix}\begin{pmatrix} v_1^T\\ v_2^T\\ ...\\ v_n^T \end{pmatrix} \\ &= \lambda_1v_1v_1^T + \lambda_2v_2v_2^T + ... + \lambda_nv_nv_n^T \end{aligned} A=[v1,v2,...,vn]⎝⎜⎜⎛λ1λ2...λn⎠⎟⎟⎞⎝⎜⎜⎛v1Tv2T...vnT⎠⎟⎟⎞=λ1v1v1T+λ2v2v2T+...+λnvnvnT
分解得到的这些方阵有什么特点呢?是由一个列向量( n × 1 n \times 1 n×1)和一个行向量( 1 × n 1 \times n 1×n)相乘得到的,原来的 n × n n \times n n×n 矩阵 A 参数量 n 2 n^2 n2,特征分解后,参数量最多可以达到 ( n × 1 + 1 ) × n = n 2 + n (n \times 1 + 1 )\times n = n^2 + n (n×1+1)×n=n2+n(1 表示的是 λ i \lambda_i λi,哈哈,参数量变多了)
但是我们可以选取特征值 λ i \lambda_i λi 较大的方阵,表示对最后的结果贡献越高!这样一来,参数量大大的减少了(最少 n × 1 + 1 n \times 1 + 1 n×1+1,仅仅保留一项) ,达到了压缩的目的!
2 SVD 分解
2.1 推导
SVD,singular value decomposition,奇异值分解
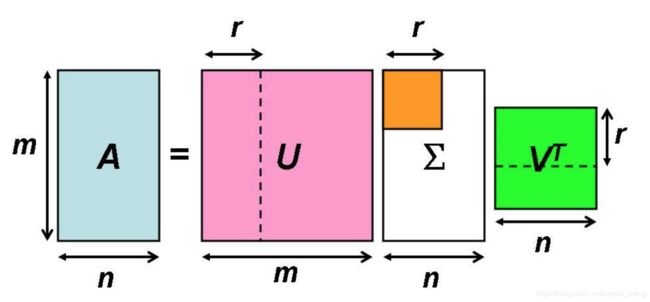
r 是矩阵 A 的秩
图片来源:http://www.imooc.com/article/267351
本质:原矩阵(不限于方阵)分解成了许多矩阵的线性组合(类比泰勒公式)!
这里比矩阵的特征分解更进一步,不再要求是方阵了,更有普适性了。具体转化过程如下:
虽然 A m × n A_{m \times n} Am×n 不是方阵 ,但是 A A m × m T AA^T_{m \times m} AAm×mT 和 A T A n × n A^TA_{n \times n} ATAn×n 组成 CP 后,就是方阵了。我们假设:
( A A T ) m × m = U Λ 2 U T (AA^T)_{m \times m} = U \Lambda^2 U^T (AAT)m×m=UΛ2UT
( A T A ) n × n = V Λ 2 V T (A^TA)_{n \times n} = V \Lambda^2 V^T (ATA)n×n=VΛ2VT
Λ m × n 2 \Lambda_{m \times n}^2 Λm×n2 是 A A T AA^T AAT 和 A T A A^TA ATA 的特征值( A B AB AB 和 B A BA BA 的特征值是一样的,非零)
U m × m = ( u 1 , u 2 , . . . , u m ) U_{m \times m} = (u_1,u_2,...,u_m) Um×m=(u1,u2,...,um), U U U 为正交矩阵
V n × n = ( v 1 , v 2 , . . . , v n ) V_{n \times n} = (v_1,v_2,...,v_n) Vn×n=(v1,v2,...,vn), V V V 为正交矩阵
可以得到 A A A 的形式如下
A m × n = U Λ V T = λ 1 1 2 u 1 v 1 T + λ 2 1 2 u 2 v 2 T + . . . A_{m \times n} = U \Lambda V^T = \lambda_1^{\frac{1}{2}}u_1v_1^T + \lambda_2^{\frac{1}{2}}u_2v_2^T+... Am×n=UΛVT=λ121u1v1T+λ221u2v2T+...
加法的最后一项根据 m , n m,n m,n 中较小的一项决定
u 1 u_1 u1 是 m × 1 m \times 1 m×1, v 1 v_1 v1 是 n × 1 n \times 1 n×1,图像压缩存储时最少需要 m + n + 1 m+n+1 m+n+1

图片来自于 deepshare.net
1) A m × n A_{m \times n} Am×n 为什么是 U Λ V T U \Lambda V^T UΛVT 这种形式呢?
反推一下,假设已知
A = U Λ V T A = U \Lambda V^T A=UΛVT
转置一下
A T = V Λ T U T A^T = V \Lambda^T U^T AT=VΛTUT
组合一下
A A T = U Λ V T V Λ T U T = U Λ Λ T U T = U Λ 2 U T AA^T = U \Lambda V^TV \Lambda^T U^T = U \Lambda \Lambda^T U^T = U \Lambda^2 U^T AAT=UΛVTVΛTUT=UΛΛTUT=UΛ2UT
A T A = V Λ T U T U Λ V T = V Λ T Λ V T = V Λ 2 V T A^TA = V \Lambda^T U^TU \Lambda V^T = V \Lambda^T \Lambda V^T = V \Lambda^2 V^T ATA=VΛTUTUΛVT=VΛTΛVT=VΛ2VT
OK,形式没错
2)U 和 V 的关系是什么
A = U Λ V T A = U \Lambda V^T A=UΛVT
左右同时乘以 V V V
A V = U Λ V T V = U Λ A V= U \Lambda V^TV = U \Lambda AV=UΛVTV=UΛ
所以
U = A V Λ U = \frac{AV}{\Lambda} U=ΛAV
其中, Λ m × n 2 \Lambda^2_{m \times n} Λm×n2 是由 λ 1 \lambda_1 λ1, λ 2 \lambda_2 λ2 …构成的对角矩阵,细节一点可以写成如下形式:
u i = A v i λ i u_i = \frac{Av_i}{\sqrt{\lambda_i}} ui=λiAvi
3) A m × n A_{m \times n} Am×n 的具体推导过程
对于矩阵 A T A n × n A^TA_{n \times n} ATAn×n,有 A T A v i = λ i v i A^TAv_i = \lambda_i v_i ATAvi=λivi,设 λ i \lambda_i λi 为 A T A A^TA ATA 的特征值, v i v_i vi 为对应的特征向量。前面我们令 U U U 和 V V V 为正交矩阵,所以 v i T v j = 0 v_i^Tv_j=0 viTvj=0。
进一步分析:
( A v i ) T A v j = v i T A T A v j = v i T λ j v j = λ j v i T v j = 0 \begin{aligned} (Av_i)^TAv_j &=v_i^TA^TAv_j \\ & = v_i^T\lambda_jv_j \\ & = \lambda_jv_i^Tv_j = 0 \end{aligned} (Avi)TAvj=viTATAvj=viTλjvj=λjviTvj=0
所以 A v i Av_i Avi 与 A v j Av_j Avj 也是正交的,同理 ( A v i ) T A v i (Av_i)^TAv_i (Avi)TAvi 可以进行如下化简:
( A v i ) T A v i = v i T A T A v i = v i T λ i v i = λ i v i T v i = λ i \begin{aligned} (Av_i)^TAv_i &=v_i^TA^TAv_i \\ & = v_i^T\lambda_iv_i \\ & = \lambda_iv_i^Tv_i = \lambda_i \end{aligned} (Avi)TAvi=viTATAvi=viTλivi=λiviTvi=λi
也即
∣ A v i ∣ 2 = λ i |Av_i|^2 = \lambda_i ∣Avi∣2=λi, ∣ A v i ∣ = λ i |Av_i| = \sqrt{\lambda_i} ∣Avi∣=λi
因此
A v i ∣ A v i ∣ = 1 λ i A v i \frac{Av_i}{|Av_i|} = \frac{1}{\sqrt{\lambda_i}}Av_i ∣Avi∣Avi=λi1Avi
前面我们已经知道
u i = 1 λ i A v i u_i = \frac{1}{\sqrt{\lambda_i}}Av_i ui=λi1Avi
因此
A v i = ∣ A v i ∣ u i = λ i u i Av_i = |Av_i|u_i = \sqrt{\lambda_i} u_i Avi=∣Avi∣ui=λiui
写成矩阵的形式,如下所示:
A V = A ( v 1 , v 2 , . . . , v n ) = ( A v 1 , A v 2 , . . . , A v n ) = ( λ 1 u 1 , λ 2 u 2 , . . . , λ n u n ) = Λ U = U Λ \begin{aligned} AV &= A(v_1,v_2,...,v_n) \\ &= (Av_1,Av_2,...,Av_n) \\ &=(\sqrt{\lambda_1}u_1,\sqrt{\lambda_2}u_2,...,\sqrt{\lambda_n}u_n) \\ &= \Lambda U = U \Lambda \end{aligned} AV=A(v1,v2,...,vn)=(Av1,Av2,...,Avn)=(λ1u1,λ2u2,...,λnun)=ΛU=UΛ
因此
A = U Λ V − 1 = U Λ V T A = U \Lambda V^{-1} = U \Lambda V^T A=UΛV−1=UΛVT
举个小例子:
比如,打开图片,开始先模糊,后面越来越清晰,本质就是,先传重要的信息(比如 SVD 中特征值比较大的分量),再补细节信息!
2.2 计算一个矩阵的 SVD 形式
A = ( 0 1 1 1 1 0 ) A = \begin{pmatrix} 0 & 1\\ 1 & 1\\ 1 & 0 \end{pmatrix} A=⎝⎛011110⎠⎞
1)计算 A A 3 × 3 T AA^T_{3\times 3} AA3×3T 的特征值和特征向量
A A 3 × 3 T = ( 0 1 1 1 1 0 ) ( 0 1 1 1 1 0 ) = ( 1 1 0 1 2 1 0 1 1 ) AA^T_{3\times 3} = \begin{pmatrix} 0 & 1\\ 1 & 1\\ 1 & 0 \end{pmatrix} \begin{pmatrix} 0 & 1 & 1\\ 1 & 1 & 0 \end{pmatrix} = \begin{pmatrix} 1 & 1 & 0\\ 1 & 2 & 1\\ 0 & 1 & 1 \end{pmatrix} AA3×3T=⎝⎛011110⎠⎞(011110)=⎝⎛110121011⎠⎞
∣ λ E − A A T ∣ = ∣ λ − 1 − 1 0 − 1 λ − 2 − 1 0 − 1 λ − 1 ∣ = λ ( λ − 3 ) ( λ − 1 ) |\lambda E - AA^T| = \begin{vmatrix} \lambda-1 & -1 & 0\\ -1 & \lambda-2 & -1\\ 0 & -1 & \lambda-1 \end{vmatrix} = \lambda(\lambda-3)(\lambda-1) ∣λE−AAT∣=∣∣∣∣∣∣λ−1−10−1λ−2−10−1λ−1∣∣∣∣∣∣=λ(λ−3)(λ−1)
所以 λ 1 = 3 \lambda_1 =3 λ1=3, λ 2 = 1 \lambda_2 =1 λ2=1, λ 3 = 0 \lambda_3 =0 λ3=0
i) 当 λ = 3 \lambda =3 λ=3 时
( λ E − A A T ) X = 0 (\lambda E - AA^T)X = 0 (λE−AAT)X=0
矩阵为
( 2 − 1 0 − 1 1 − 1 0 − 1 2 ) ⇒ ( 1 0 − 1 0 1 − 2 0 0 0 ) \begin{pmatrix} 2 & -1 & 0\\ -1 & 1 & -1\\ 0 & -1 & 2 \end{pmatrix} \Rightarrow \begin{pmatrix} 1 & 0 & -1\\ 0 & 1 & -2\\ 0 & 0 & 0 \end{pmatrix} ⎝⎛2−10−11−10−12⎠⎞⇒⎝⎛100010−1−20⎠⎞
对应的单位化的特征向量 u 1 u_1 u1 为 ( 1 6 , 2 6 , 1 6 ) T (\frac{1}{\sqrt{6}},\frac{2}{\sqrt{6}},\frac{1}{\sqrt{6}})^T (61,62,61)T
ii) 当 λ = 1 \lambda =1 λ=1 时
( λ E − A A T ) X = 0 (\lambda E - AA^T)X = 0 (λE−AAT)X=0
矩阵为
( 0 − 1 0 − 1 − 1 − 1 0 − 1 0 ) ⇒ ( 1 0 1 0 1 0 0 0 0 ) \begin{pmatrix} 0 & -1 & 0\\ -1 & -1 & -1\\ 0 & -1 & 0 \end{pmatrix} \Rightarrow \begin{pmatrix} 1 & 0 & 1\\ 0 & 1 & 0\\ 0 & 0 & 0 \end{pmatrix} ⎝⎛0−10−1−1−10−10⎠⎞⇒⎝⎛100010100⎠⎞
对应的单位化的特征向量 u 2 u_2 u2 为 ( 1 2 , 0 , − 1 2 ) T (\frac{1}{\sqrt{2}},0,-\frac{1}{\sqrt{2}})^T (21,0,−21)T
iii) 当 λ = 0 \lambda =0 λ=0 时
( λ E − A A T ) X = 0 (\lambda E - AA^T)X = 0 (λE−AAT)X=0
矩阵为
( − 1 − 1 0 − 1 − 2 − 1 0 − 1 − 1 ) ⇒ ( 1 0 − 1 0 1 1 0 0 0 ) \begin{pmatrix} -1 & -1 & 0\\ -1 & -2 & -1\\ 0 & -1 & -1 \end{pmatrix} \Rightarrow \begin{pmatrix} 1 & 0 & -1\\ 0 & 1 & 1\\ 0 & 0 & 0 \end{pmatrix} ⎝⎛−1−10−1−2−10−1−1⎠⎞⇒⎝⎛100010−110⎠⎞
对应的单位化的特征向量 u 3 u_3 u3 为 ( 1 3 , − 1 3 , 1 3 ) T (\frac{1}{\sqrt{3}},-\frac{1}{\sqrt{3}},\frac{1}{\sqrt{3}})^T (31,−31,31)T
综上所述:
A A T = U Λ 2 U T = ( 1 6 1 2 1 3 2 6 0 − 1 3 1 6 − 1 2 1 3 ) ( 3 0 0 0 1 0 0 0 0 ) ( 1 6 2 6 1 6 1 2 0 − 1 2 1 3 − 1 3 1 3 ) AA^T = U\Lambda^2 U^T = \begin{pmatrix} \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}}\\ \frac{2}{\sqrt{6}} & 0 & -\frac{1}{\sqrt{3}}\\ \frac{1}{\sqrt{6}} & -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}} \end{pmatrix} \begin{pmatrix} 3 & 0 & 0\\ 0 & 1 & 0\\ 0 & 0 & 0 \end{pmatrix} \begin{pmatrix} \frac{1}{\sqrt{6}} & \frac{2}{\sqrt{6}} & \frac{1}{\sqrt{6}}\\ \frac{1}{\sqrt{2}} & 0 & -\frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{3}} & -\frac{1}{\sqrt{3}} &\frac{1}{\sqrt{3}} \end{pmatrix} AAT=UΛ2UT=⎝⎜⎛616261210−2131−3131⎠⎟⎞⎝⎛300010000⎠⎞⎝⎜⎛612131620−3161−2131⎠⎟⎞
2)计算 A T A 2 × 2 A^TA_{2\times 2} ATA2×2 的特征值和特征向量
A T A 2 × 2 = ( 0 1 1 1 1 0 ) ( 0 1 1 1 1 0 ) = ( 2 1 1 2 ) A^TA_{2\times 2} = \begin{pmatrix} 0 & 1 & 1\\ 1 & 1 & 0 \end{pmatrix} \begin{pmatrix} 0 & 1\\ 1 & 1\\ 1 & 0 \end{pmatrix} = \begin{pmatrix} 2 & 1\\ 1 & 2 \end{pmatrix} ATA2×2=(011110)⎝⎛011110⎠⎞=(2112)
∣ λ E − A T A ∣ = ∣ λ − 2 − 1 − 1 λ − 2 ∣ = ( λ − 3 ) ( λ − 1 ) |\lambda E - A^TA| = \begin{vmatrix} \lambda-2 & -1\\ -1 & \lambda-2 \end{vmatrix} = (\lambda-3)(\lambda-1) ∣λE−ATA∣=∣∣∣∣λ−2−1−1λ−2∣∣∣∣=(λ−3)(λ−1)
所以 λ 1 = 3 \lambda_1 =3 λ1=3, λ 2 = 1 \lambda_2 =1 λ2=1
i) 当 λ = 3 \lambda =3 λ=3 时
( λ E − A T A ) X = 0 (\lambda E - A^TA)X = 0 (λE−ATA)X=0
矩阵为
( 1 − 1 − 1 1 ) ⇒ ( 1 − 1 0 0 ) \begin{pmatrix} 1 & -1 \\ -1 & 1 \end{pmatrix} \Rightarrow \begin{pmatrix} 1 & -1 \\ 0 & 0 \end{pmatrix} (1−1−11)⇒(10−10)
对应的单位化的特征向量 v 1 v_1 v1 为 ( 1 2 , 1 2 ) T (\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})^T (21,21)T
ii) 当 λ = 1 \lambda =1 λ=1 时
( λ E − A T A ) X = 0 (\lambda E - A^TA)X = 0 (λE−ATA)X=0
矩阵为
( − 1 − 1 − 1 − 1 ) ⇒ ( 1 1 0 0 ) \begin{pmatrix} -1 & -1 \\ -1 & -1 \end{pmatrix} \Rightarrow \begin{pmatrix} 1 & 1 \\ 0 & 0 \end{pmatrix} (−1−1−1−1)⇒(1010)
对应的单位化的特征向量 v 2 v_2 v2 为 ( 1 2 , − 1 2 ) T (\frac{1}{\sqrt{2}},-\frac{1}{\sqrt{2}})^T (21,−21)T
PS:这里有点小疑惑,如果 v 2 v_2 v2 按照上面的格式写,最终通过 U U U 和 V V V 计算 A A A 的时候第一列和第二列位置互换了,需要写成 v 2 v_2 v2 为 ( − 1 2 , 1 2 ) T (-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})^T (−21,21)T,这两种结果在计算特征值的时候是等价的!
感觉应该需要用 u i u_i ui 和 v i v_i vi 的关系约束下:
前面我们已知
u i = 1 λ i A v i u_i = \frac{1}{\sqrt{\lambda_i}}Av_i ui=λi1Avi
这里带进去看看
u 2 = 1 λ 2 A v 2 u_2 = \frac{1}{\sqrt{\lambda_2}}Av_2 u2=λ21Av2
( 1 2 0 − 1 2 ) = 1 1 ( 0 1 1 1 1 0 ) ( − 1 2 1 2 ) \begin{pmatrix} \frac{1}{\sqrt{2}}\\ 0\\ -\frac{1}{\sqrt{2}} \end{pmatrix} = \frac{1}{\sqrt{1}} \begin{pmatrix} 0 & 1\\ 1 & 1\\ 1 & 0 \end{pmatrix} \begin{pmatrix} -\frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{pmatrix} ⎝⎛210−21⎠⎞=11⎝⎛011110⎠⎞(−2121)
确实 v 2 v_2 v2 为 ( − 1 2 , 1 2 ) T (-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})^T (−21,21)T 而不是 ( 1 2 , − 1 2 ) T (\frac{1}{\sqrt{2}},-\frac{1}{\sqrt{2}})^T (21,−21)T
回归正题,综上所述:
A T A = V Λ 2 V T = ( 1 2 − 1 2 1 2 1 2 ) ( 3 0 0 1 ) ( 1 2 1 2 − 1 2 1 2 ) A^TA = V\Lambda^2 V^T = \begin{pmatrix} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{pmatrix} \begin{pmatrix} 3 & 0\\ 0 & 1 \end{pmatrix} \begin{pmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{pmatrix} ATA=VΛ2VT=(2121−2121)(3001)(21−212121)
所以
A = U Λ V T = ( 1 6 1 2 1 3 2 6 0 − 1 3 1 6 − 1 2 1 3 ) ( 3 0 0 1 0 0 ) ( 1 2 1 2 − 1 2 1 2 ) = ( 0 1 1 1 1 0 ) A = U \Lambda V^T = \begin{pmatrix} \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}}\\ \frac{2}{\sqrt{6}} & 0 & -\frac{1}{\sqrt{3}}\\ \frac{1}{\sqrt{6}} & -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}} \end{pmatrix} \begin{pmatrix} \sqrt{3} & 0 \\ 0 & 1 \\ 0 & 0 \end{pmatrix} \begin{pmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{pmatrix}= \begin{pmatrix} 0 & 1\\ 1 & 1\\ 1 & 0 \end{pmatrix} A=UΛVT=⎝⎜⎛616261210−2131−3131⎠⎟⎞⎝⎛300010⎠⎞(21−212121)=⎝⎛011110⎠⎞
3 逆矩阵(以最小二乘为例)
定义:
设 A A A 是 n n n 阶矩阵,如果存在 n n n 阶矩阵 B B B 使得
A B = E ( 单 位 矩 阵 ) AB = E(单位矩阵) AB=E(单位矩阵)
成立,则称 A A A 是可逆矩阵, B B B 是 A A A 的逆矩阵,记成 A − 1 = B A^{-1} = B A−1=B.
可逆矩阵有两个非常重要的性质:
- ∣ A ∣ ≠ 0 |A| \neq 0 ∣A∤=0,或者秩 r ( A ) = n r(A)=n r(A)=n,或 A A A 的列(行)向量无关;
- 矩阵 A A A 的特征值全不为 0
下面以最小二乘为例,分析下逆矩阵和伪逆矩阵,假设有 N N N 个样本,每个样本 n n n 维
x 1 , x 2 , . . . , x N , x i ∈ R n x_1,x_2,...,x_N, x_i \in \mathbb{R}^n x1,x2,...,xN,xi∈Rn
N N N 个标签,每个标签 1 1 1 维
y 1 , y 2 , . . . , y N , y i ∈ R 1 y_1,y_2,...,y_N, y_i \in \mathbb{R}^1 y1,y2,...,yN,yi∈R1
我们需要求解的就是 x → y x \to y x→y 的关系,形象化一点
{ y 1 = x 1 1 a 1 + x 1 2 a 2 + . . . + x 1 n a n y 2 = x 2 1 a 1 + x 2 2 a 2 + . . . + x 2 n a n . . . y N = x N 1 a 1 + x N 2 a 2 + . . . + x N n a n \left\{\begin{matrix} y_1 = x_1^1a_1 + x_1^2a_2 +...+x_1^na_n\\ y_2 = x_2^1a_1 + x_2^2a_2 +...+x_2^na_n\\ ...\\ y_N = x_N^1a_1 + x_N^2a_2 +...+x_N^na_n \end{matrix}\right. ⎩⎪⎪⎨⎪⎪⎧y1=x11a1+x12a2+...+x1nany2=x21a1+x22a2+...+x2nan...yN=xN1a1+xN2a2+...+xNnan
其中 x i j x_i^j xij 表示第 i i i 个样本的第 j j j 维!
写成矩阵的形式:
( x 1 1 x 1 2 . . . x 1 n x 2 1 x 2 2 . . . x 2 n . . . . . . . . . . . . x N 1 x N 2 . . . x N n ) N × n ( a 1 a 2 . . . a n ) n × 1 = ( y 1 y 2 . . . y N ) N × 1 \begin{pmatrix} x_1^1 & x_1^2 & ... & x_1^n\\ x_2^1 & x_2^2 & ... & x_2^n\\ ...& ...& ...& ... \\ x_N^1 & x_N^2 & ... & x_N^n \end{pmatrix}_{N \times n}\begin{pmatrix} a_1\\ a_2\\ ...\\ a_n \end{pmatrix}_{n \times 1} = \begin{pmatrix} y_1\\ y_2\\ ...\\ y_N \end{pmatrix}_{N \times 1} ⎝⎜⎜⎛x11x21...xN1x12x22...xN2............x1nx2n...xNn⎠⎟⎟⎞N×n⎝⎜⎜⎛a1a2...an⎠⎟⎟⎞n×1=⎝⎜⎜⎛y1y2...yN⎠⎟⎟⎞N×1
也即
X N × n a n × 1 = Y N × 1 X_{N \times n}a_{n \times 1} = Y_{N \times 1} XN×nan×1=YN×1
问题的关键就是求出来 a n × 1 a_{n \times 1} an×1 了!我们已知 X X X 和 Y Y Y,所以,当 N = n N = n N=n 且 X N × n X_{N \times n} XN×n 可逆时:
a = X − 1 Y a = X^{-1}Y a=X−1Y
4 伪逆矩阵(以最小二乘为例)
一般情况下,样本总个数 N N N 和每个样本的维数 n n n 是不相等的,这个时候 X X X 显然不可逆(连方阵都不是), a = X − 1 Y a = X^{-1}Y a=X−1Y 的求法行不通!
怎么破?
我们可以用 X a Xa Xa 来逼近 Y Y Y,也即最小化 J J J
J = ∣ ∣ X a − Y ∣ ∣ 2 J = ||Xa - Y||^2 J=∣∣Xa−Y∣∣2
未知数是 a a a,对 a a a 求偏导,令导数为零求极值
∂ J ∂ a = 2 X T ( X a − Y ) = 0 \frac{\partial J}{\partial a} = 2 X^T(Xa-Y)=0 ∂a∂J=2XT(Xa−Y)=0
化简一下:
X T X a = X T Y X^TXa= X^TY XTXa=XTY
问题就转换为了 X T X X^TX XTX 是否可逆!
1)如果 N > n N > n N>n
( X T X ) n × n (X^TX)_{n \times n} (XTX)n×n 一般是可逆的,此时:
a = ( X T X ) − 1 X T Y a= (X^TX)^{-1}X^TY a=(XTX)−1XTY
如果 X X X 可逆的话,把可逆符号作用在括号里
a = X − 1 ( X T ) − 1 X T Y = X − 1 Y a = X^{-1}(X^T)^{-1}X^TY = X^{-1}Y a=X−1(XT)−1XTY=X−1Y
和上一节的结论一致,所以 a = ( X T X ) − 1 X T Y a= (X^TX)^{-1}X^TY a=(XTX)−1XTY 叫做伪逆矩阵的形式!是一种更普适性的解法。
通过 a = X − 1 ( X T ) − 1 X T Y = X − 1 Y a = X^{-1}(X^T)^{-1}X^TY = X^{-1}Y a=X−1(XT)−1XTY=X−1Y 给出解的系统方程被称为正规方程(normal equation).
2)如果 N < n N < n N<n
样本的个数小于样本的维度,也就是样本的表示太复杂了,过拟合的节奏!
( X T X ) N × N (X^TX)_{N \times N} (XTX)N×N
我们已知秩的如下性质:
r ( A B ) ≤ m i n ( r ( A ) , r ( B ) ) r(AB)\leq min(r(A),r(B)) r(AB)≤min(r(A),r(B))
所以
r ( X T X ) ≤ r ( X ) ≤ n r(X^TX) \leq r(X) \leq n r(XTX)≤r(X)≤n
所以
r ( X T X ) ≠ N r(X^TX) \neq N r(XTX)̸=N
根据逆矩阵的性质可知, X T X X^TX XTX 不可逆,也即伪逆 a = X − 1 ( X T ) − 1 X T Y a = X^{-1}(X^T)^{-1}X^TY a=X−1(XT)−1XTY 的路也行不通了,怎么破!
此时我们要用到最小范数解,也就是我们熟悉的加正则项(regularization)
5 最小范数解(以最小二乘为例)
此时 J J J 引入了正则项
J = ∣ ∣ X a − Y ∣ ∣ 2 + λ ∣ ∣ a ∣ ∣ 2 J = ||Xa - Y||^2 + \lambda||a||^2 J=∣∣Xa−Y∣∣2+λ∣∣a∣∣2
对 a a a 计算偏导,令其为 0,来求极值:
∂ J ∂ a = 2 X T ( X a − Y ) + 2 λ a = 0 \frac{\partial J}{\partial a} = 2X^{T}(Xa-Y) + 2\lambda a = 0 ∂a∂J=2XT(Xa−Y)+2λa=0
化简一下(因为 X T X X^TX XTX 是方阵,所以引入了单位矩阵 I I I):
( X T X + λ I ) a = X T Y (X^TX+\lambda I)a = X^TY (XTX+λI)a=XTY
问题聚焦到 X T X + λ I X^TX+\lambda I XTX+λI 是否可逆!
我们已知 X T X X^TX XTX 是实对称矩阵,所以 X T X X^TX XTX 一定可以相似对角化(特征值,可以参考实对称矩阵小节中的定理3),转换一下形式,可以写成:
X T X = Q ( λ 1 . . . λ n ) Q T X^TX = Q\begin{pmatrix} \lambda_1 & & \\ & ... & \\ & & \lambda_n \end{pmatrix}Q^T XTX=Q⎝⎛λ1...λn⎠⎞QT
行列式为特征值的乘积
∣ X T X ∣ = λ 1 λ 2 . . . λ n |X^TX| = \lambda_1\lambda_2...\lambda_n ∣XTX∣=λ1λ2...λn
给定一个非零向量 m m m,把矩阵 X T X X^TX XTX 写成二次型的形式:
m T X T X m = ( X m ) T ( X m ) ≥ 0 → λ i ≥ 0 m^TX^TXm = (Xm)^T(Xm) \geq 0 \to \lambda_i \geq 0 mTXTXm=(Xm)T(Xm)≥0→λi≥0
只能保证是半正定, ∣ X T X ∣ |X^TX| ∣XTX∣ 还是有可能为0,也即无法保证 X T X X^TX XTX 可逆(前面已经证明了 X T X X^TX XTX 不可逆,这里仅从表达式入手),引入正则项以后情况就不一样了。
X T X + λ I X^TX+\lambda I XTX+λI 同样也是实对称矩阵,因为只是在对角线上有改动,同样的可以写成
X T X + λ I = Q ( λ 1 . . . λ n ) Q T X^TX +\lambda I = Q\begin{pmatrix} \lambda_1 & & \\ & ... & \\ & & \lambda_n \end{pmatrix}Q^T XTX+λI=Q⎝⎛λ1...λn⎠⎞QT
给定一个非零向量 m m m,把矩阵 X T X + λ I X^TX +\lambda I XTX+λI 写成二次型的形式:
m T ( X T X + λ I ) m = ( X m ) T ( X m ) + λ m T m > 0 → λ i > 0 m^T(X^TX+\lambda I)m = (Xm)^T(Xm) + \lambda m^Tm > 0 \to \lambda_i > 0 mT(XTX+λI)m=(Xm)T(Xm)+λmTm>0→λi>0
这么一来, X T X + λ I X^TX +\lambda I XTX+λI 就是正定矩阵了,就能保证对应的特征值全部大于0,也即 ∣ X T X + λ I ∣ = λ 1 λ 2 . . . λ n > 0 |X^TX +\lambda I|=\lambda_1\lambda_2...\lambda_n>0 ∣XTX+λI∣=λ1λ2...λn>0,结合矩阵可逆的条件,可以得出,矩阵 X T X + λ I X^TX +\lambda I XTX+λI 是可逆矩阵!
所以 a a a 可以表示为:
a = ( X T X + λ I ) − 1 X T Y a = (X^TX+\lambda I)^{-1}X^TY a=(XTX+λI)−1XTY
补充(参考 https://blog.csdn.net/asd136912/article/details/79146151)

综合 3,4,5 小节,已知
X N × n a n × 1 = Y N × 1 X_{N \times n}a_{n \times 1} = Y_{N \times 1} XN×nan×1=YN×1
可以得出:
a = { X − 1 Y , 如 果 N = n , 且 X 可 逆 ( X T X ) − 1 X T Y , 如 果 N > n ( 伪 逆 ) ( X T X + λ I ) − 1 X T Y , 如 果 N < n ( 最 小 范 数 解 ) a = \left\{\begin{matrix} \begin{aligned} & X^{-1}Y,&如果 N=n,且 X 可逆\\ & (X^TX)^{-1}X^TY,& 如果 N>n(伪逆)\\ & (X^TX+\lambda I)^{-1}X^TY,& 如果 N<n(最小范数解) \end{aligned} \end{matrix}\right. a=⎩⎪⎨⎪⎧X−1Y,(XTX)−1XTY,(XTX+λI)−1XTY,如果N=n,且X可逆如果N>n(伪逆)如果N<n(最小范数解)