1. github下载地址
https://github.com/super-csv/super-csv
裁剪下来的例子 https://gitee.com/outllok/super-csv
2. 文档翻译 http://super-csv.github.io/super-csv/
2.1 welcome
Motivation (动力)
The main motivation for Super CSV is to be the foremost(最重要的), fastest, and most programmer(程序员)-friendly, free CSV package for Java.
Features (特征)
Super CSV offers the following features not found together in other CSV packages:
POJO support
Read or write using any old Javabean. Perform deep mapping and index-based mapping using the new Dozer(新的目标对象的实例将会有源对象属性的值) extension(扩展)! For the old-fashioned, you can read or write with Lists and Maps as well.
Automatic CSV encoding
Forget about handling special characters such as commas and double-quotes - Super CSV will take care of that for you! All content is properly escaped/un-escaped according to the CSV specification.(忘记处理特殊字符,如逗号和双引号-超级csv将为您处理!根据csv规范,所有内容都正确转义/未转义。)
Highly configurable (高度可配置)
Choose your own delimiter, quote character and line separator - or just use one of the predefined configurations. Comma-separated, tab-separated, semicolon-separated (Germany/Denmark) - it's all possible.(选择您自己的分隔符、引号字符和行分隔符-或者只使用一个预定义的配置。逗号分隔、制表符分隔、分号分隔 一切都是能够做到的)
Data conversion (数据转换)
Powerful cell processors make it simple to parse input (to Booleans, Integers, Dates, etc), transform values (trimming Strings, doing regular expression replacement, etc) and format output like Dates and Numbers.(强大的单元格处理器对输入值的解析、转换值 和格式化输出(如日期和数字)变得简单)
Constraint validation (约束验证)
Verify that your data conforms to one or more constraints, such as number ranges, string lengths or uniqueness.(验证数据是否符合一个或多个约束,例如数字范围、字符串长度或唯一性。)
Stream-based I/O
Operates on streams rather than filenames, and gives you the control to flush or close the streams when you want. Write to a file, over the network, to a zip file, whatever!
Message from the author(来自作者的消息)
My years in industry dealing with CSV files (among other things ;-), has enabled me to identify a number of limitations with existing CSV packages. These limitations led me to write Super CSV. My main criticism of existing CSV packages is that reading and writing operates on lists of strings. What you really need is the ability to operate on a range of different types of objects. Moreover, you often need to restrict input/output data with constraints such as minimum and maximum sizes, or numeric ranges. Or maybe you are reading image names, and want to ensure you do not read names contain the characters ":", " ", "/", "^", "%".
Super CSV deals with all these and many other issues. And should you have a constraint not readily expressible in the package, new cell processors can easily be constructed. Furthermore, you don't want to "CSV encode" strings you write. If they happen to contain characters that needs escaping, then the CSV package should take care of this automatically!
The underlying implementation of Super CSV has been written in an extensible fashion, hence new readers/writers and cell processors can easily be supported. The inversion of controlimplementation pattern has been enforced, eradicating long-lived mistakes such as using filenames as arguments rather than Reader and Writer objects. Design patterns such as chain of responsibility and the null object pattern can also be found in the code. Feel free to have a look!
Kasper
2.2 what is csv?
The comma-separated values (CSV) format is a widely used text file format often used to exchange data between applications. It contains multiple records (one per line), and each field is delimited by a comma. Wikipedia has a good explanation of the CSV format and its history.(逗号分隔值格式是一种广泛使用的文本文件格式,通常用于在应用程序之间交换数据。它包含多个记录(每行一个),每个字段由逗号分隔。维基百科对csv格式及其历史有很好的解释。)
There is no definitive standard for CSV, however the most commonly accepted definition is RFC 4180 - the MIME type definition for CSV. Super CSV is 100% compliant with RFC 4180, while still allowing some flexibility where CSV files deviate from the definition.(csv没有明确的标准,但是最常见的定义是rfc 4180——csv的mime类型定义。super csv与rfc 4180 100%兼容,但在csv文件偏离定义的情况下仍然允许一定的灵活性。)
The following shows each rule defined in RFC 4180, and how it is treated by Super CSV.(下面显示了在RFC4180中定义的每个规则,以及如何用super csv处理它。)
Rule 1
1. Each record is located on a separate line, delimited by a line break (CRLF). For example: aaa,bbb,ccc CRLF zzz,yyy,xxx CRLF
Super CSV accepts all line breaks (Windows, Mac or Unix) when reading CSV files, and uses the end of line symbols specified by the user (via the CsvPreference object) when writing CSV files.(super csv在读取csv文件时接受所有换行符(windows、mac或unix),并在写入csv文件时使用用户指定的行尾符号。)
Rule 2
2. The last record in the file may or may not have an ending line break. For example: aaa,bbb,ccc CRLF zzz,yyy,xxx
Super CSV will add a line break when writing the last line of a CSV file, but a line break on the last line is optional when reading.(super csv将在写入csv文件的最后一行时添加换行符,但在读取时,最后一行的换行符是可选的。)
Rule 3
3. There maybe an optional header line appearing as the first line of the file with the same format as normal record lines. This header will contain names corresponding to the fields in the file and should contain the same number of fields as the records in the rest of the file (the presence or absence of the header line should be indicated via the optional "header" parameter of this MIME type). For example: field_name,field_name,field_name CRLF aaa,bbb,ccc CRLF zzz,yyy,xxx CRLF
Super CSV provides methods for reading and writing headers, if required. It also makes use of the header for mapping between CSV and POJOs (see CsvBeanReader/CsvBeanWriter).(如果需要,super csv提供读取和写入头的方法。它还使用头来映射csv和pojos)
Rule 4
4. Within the header and each record, there may be one or more fields, separated by commas. Each line should contain the same number of fields throughout the file. Spaces(空格) are considered part of a field and should not be ignored. The last field in the record must not be followed by a comma(逗号). For example: aaa,bbb,ccc
The delimiter in Super CSV is configurable via the CsvPreference object, though it is typically a comma.
Super CSV expects each line to contain the same number of fields (including the header). In cases where the number of fields varies, CsvListReader/CsvListWriter should be used, as they contain methods for reading/writing lines of arbitrary length.
By default, Super CSV considers spaces part of a field. However, if you require that surrounding spaces should not be part of the field (unless within double quotes), then you can enable surroundingSpacesNeedQuotes in your CsvPreference object. This will ensure that surrounding spaces are trimmed when reading (if not within double quotes), and that quotes are applied to a field with surrounding spaces when writing.
Rule 5
5. Each field may or may not be enclosed in double quotes(双引号) (however some programs, such as Microsoft Excel, do not use double quotes at all). If fields are not enclosed with double quotes, then double quotes may not appear inside the fields. For example: "aaa","bbb","ccc" CRLF zzz,yyy,xxx
By default Super CSV only encloses fields in double quotes when they require escaping (see Rule 6), (默认情况下,super csv只在需要转义时将字段用双引号括起来)but it is possible to enable quotes always, for particular columns, or for some other reason by supplying a QuoteMode in the CsvPreference object.
The quote character is configurable via the CsvPreference object, though is typically a double quote (").
Rule 6
6. Fields containing line breaks (CRLF), double quotes, and commas should be enclosed in double-quotes. For example: "aaa","b CRLF bb","ccc" CRLF zzz,yyy,xxx
Super CSV handles multi-line fields (as long as they're enclosed in quotes) when reading, and encloses a field in quotes when writing if it contains a newline, quote character or delimiter (defined in the CsvPreference object).(super csv在读取时处理多行字段(只要它们用引号括起来),如果字段包含换行符、引号字符或分隔符(在csvpreference对象中定义),则在写入时用引号括起来。)
Rule 7
7. If double-quotes are used to enclose fields(封闭字段), then a double-quote appearing inside a field must be escaped(转义) by preceding (前面)it with another double quote. For example: "aaa","b""bb","ccc"
Super CSV escapes double-quotes with a preceding double-quote. Please note that the sometimes-used convention of escaping double-quotes as \" (instead of "") is not supported.
2.3 Where to begin?
- Download Super CSV
- Choose a reader or writer - there are 4 of each to choose from!(每个有4个可供选择)
- Choose your preferences for reading/writing (including choice of delimiter, quote character, and end of line symbols)
- Choose from a wide variety of cell processors to apply conversions or constraints to your data
- Check out the reading and writing examples to see how it's all put together!
2.4 CSV Readers
There are four CSV reading implementations in Super CSV.(在super csv中有四个csv读取实现)
| CsvBeanReader | CsvDozerBeanReader | CsvListReader | CsvMapReader | |
|---|---|---|---|---|
| Reads each row of CSV as a | POJO (must be a valid Javabean, or interface with setters) | POJO (must be a valid (有效的)Javabean) | List |
Map |
| Supports reading into an existing bean? | Yes | Yes | No | No |
| Supports deep mapping and index-based mapping?(支持深度映射和基于索引的映射?) | No | Yes | No | No |
| Supports partial reading (ignoring columns)?(支持部分读取(忽略列)) | Yes | Yes | No | Yes |
| Supports variable number of columns ?(支持可变列数?) | No | No | Yes | No |
Which one you choose will depend on your requirements, but we recommend using CsvBeanReader or CsvDozerBeanReader where possible, as it's far easier to work with POJOs than Lists or Maps. Check out the reading examples to see them in action.
(您选择哪一个取决于您的需求,但我们建议尽可能使用CSvBeanReader或CSvDozerBeanReader,因为使用POJO比使用列表或map集合容易得多。查看阅读示例以了解它们的实际情况。)
2.5 CSV Writers
There are five CSV writing implementations in Super CSV.
| CsvBeanWriter | CsvDozerBeanWriter | CsvResultSetWriter | CsvListWriter | CsvMapWriter | |
|---|---|---|---|---|---|
| Writes each row of CSV from a | POJO (must be a valid Javabean) | POJO (must be a valid Javabean) | JDBC ResultSet | List |
Map |
| Supports deep mapping and index-based mapping? | No | Yes | No | No | No |
| Supports partial writing (default values)?(支持部分写入(默认值)?) | Yes | Yes | No | Yes | Yes |
Which one you choose will depend on your requirements, but we recommend using CsvBeanWriter, CsvDozerBeanWriter or CsvResultSetWriter where possible, as it's far easier than working with Lists or Maps. Check out the writing examples to see them in action.(您选择哪一个取决于您的要求,但我们建议尽可能使用csvbeanwriter、csvdozerbeanwriter或csvresultsetwriter,因为它比使用列表或map集合容易得多。查看书写示例以查看它们的实际效果。)
2.6 CSV Preferences(设置)
Readers and Writers in Super CSV are configured using the CsvPreference class. This class is immutable(不变的) and is assembled(组装) using the Builder pattern.
The preferences available are:
quoteChar The quote character (used when a cell contains special characters, such as the delimiter char, a quote char, or spans multiple lines).
(引号字符(当单元格包含特殊字符,如分隔符字符、引号字符或跨多行时使用))
delimiterChar The delimiter character (separates each cell in a row).(分隔符(将每个单元格分隔成一行))
endOfLineSymbols
The end of line symbols to use when writing (Windows, Mac and Linux style line breaks are all supported when reading, so this preference won't be used at all for reading).(在写入时使用的行尾符号)
surroundingSpacesNeedQuotes
Whether spaces surrounding a cell need quotes in order to be preserved (see below). The default value is false (quotes aren't required).
ignoreEmptyLines
Whether empty lines (i.e. containing only end of line symbols) are ignored. The default value is true (empty lines are ignored).
maxLinesPerRow
The maximum number of lines a row of CSV can span (useful for debugging large files with mismatched quotes, as it ensures fast failure and prevents OutOfMemoryErrors when trying to find the matching quote).
skipComments(跳过注释)
Skips comments (what makes up a comment is determined by the CommentMatcher you supply). See the section on skipping comments below for more information.
encoder
Use your own encoder when writing CSV. See the section on custom encoders below.
quoteMode
Allows you to enable surrounding quotes for writing (if a column wouldn't normally be quoted because it doesn't contain special characters). See the section on quote modes below.(编写csv时使用自己的编码器。请参阅下面有关自定义编码器的部分。)
Predefined preferences
There are four 'ready to use' configurations for typical scenarios.
| Constant | Quote char(引号) | Delimiter char(分隔符) | End of line symbols(行尾符号) |
|---|---|---|---|
| STANDARD_PREFERENCE | " | , | \r\n |
| EXCEL_PREFERENCE | " | , | \n |
| EXCEL_NORTH_EUROPE_PREFERENCE | " | ; | \n |
| TAB_PREFERENCE | " | \t | \n |
All of these configurations use the default values of:
| Preference | Default value |
|---|---|
| surroundingSpacesNeedQuotes | false |
| ignoreEmptyLines | true |
| maxLinesPerRow | 0 (disabled) |
| encoder | DefaultCsvEncoder |
| quoteMode | NormalQuoteMode |
| skipComments | false (no CommentMatcher used) |
Create your own preference
If none of the predefined preferences suit your purposes, you can easily create your own (you're not just limited to CSV files!). For example, the following code snippet creates preferences suitable for reading/writing pipe-delimited files.(管道分隔文件)
private static final CsvPreference PIPE_DELIMITED = new CsvPreference.Builder('"', '|', "\n").build();
Ignoring surrounding spaces if they're not within quotes
In accordance with RFC 4180, the default behaviour of Super CSV is to treat all spaces as important, including spaces surrounding the text in a cell.
This means for reading, a cell with contents surrounded by spaces is read with surrounding spaces preserved. And for writing, the same String is written with surrounding spaces and no surrounding quotes (they're not required, as spaces are considered important).
There are some scenarios where this restriction must be relaxed, in particular when the CSV file you're working with assumes that surrounding spaces must be surrounded by quotes, otherwise will be ignored. For this reason, Super CSV allows you to enable the surroundingSpacesNeedQuotes preference.
With surroundingSpacesNeedQuotes enabled, it means that for reading, a cell with contents surrounded by spaces would be read as surrounded by spaces (surrounding spaces are trimmed), unless the String has surrounding quotes, e.g. " surrounded by spaces ", in which case the spaces are preserved. And for writing, any String containing surrounding spaces will automatically be given surrounding quotes when written in order to preserve the spaces.
You can enable this behaviour by calling surroundingSpacesNeedQuotes(true) on the Builder. You can do this with your own custom preference, or customize an existing preference as shown below.
private static final CsvPreference STANDARD_SURROUNDING_SPACES_NEED_QUOTES =
new CsvPreference.Builder(CsvPreference.STANDARD_PREFERENCE).surroundingSpacesNeedQuotes(true).build();
Prior to Super CSV 2.0.0, this behaviour wasn't configurable and surrounding spaces were always trimmed.
Ignoring empty lines
By default, all empty lines (which aren't quoted) are ignored when reading CSV. This is useful if your CSV file has leading or trailing empty lines. If you with to disable this behaviour and allow empty lines to be read you can use the ignoreEmptyLines preference:
private static final CsvPreference ALLOW_EMPTY_LINES =
new CsvPreference.Builder(CsvPreference.STANDARD_PREFERENCE).ignoreEmptyLines(false).build();
Limiting the maximum number of lines per row when reading CSV
If your CSV file isn't quoted property (is missing a trailing quote, for example), then it's possible that Super CSV will keep reading lines in an attempt to locate the end of the row - for large files this can cause an OutOfMemoryException. By setting the maxLinesPerRow preference Super CSV will fail fast, giving you a chance to locate the row in error and fix it:
private static final CsvPreference DISABLE_MULTILINE_ROWS =
new CsvPreference.Builder(CsvPreference.STANDARD_PREFERENCE).maxLinesPerRow(10).build();
Custom quote mode
By default Super CSV only adds surrounding quotes when writing CSV when it contains a delimiter, quote or newline (or if you've enabled surroundingSpacesNeedQuotes and the value has surrounding spaces).
Super CSV provides two alternative quoting modes:
- AlwaysQuoteMode - quotes are always applied
- ColumnQuoteMode - quotes are always applied for particular columns
You can also write your own QuoteMode, but please note that this is a means to enable quotes when they're not normally required (you won't be able to disable quotes because then your CSV will not be readable if it contains embedded special characters). Just pass your desired mode to the useQuoteMode() method when building your preferences:
private static final CsvPreference ALWAYS_QUOTE =
new CsvPreference.Builder(CsvPreference.STANDARD_PREFERENCE).useQuoteMode(new AlwaysQuoteMode().build();
Custom CSV encoder
Super CSV provides a powerful CsvEncoder, but if you'd like complete control over how your CSV is encoded, then you can supply your own to the useEncoder() method when building your preferences:
private static final CsvPreference CUSTOM_ENCODER =
new CsvPreference.Builder(CsvPreference.STANDARD_PREFERENCE).useEncoder(new MyAwesomeEncoder().build();
If you'd like to encode particular columns, but leave other columns unchanged then you can use Super CSV's SelectiveCsvEncoder. This might be useful if you're really concerned with performance and you know that certain columns will never contain special characters. Just be aware that if a column does contain special characters and you don't encode it, you could end up with invalid CSV.
Skipping comments
Although comments aren't part of RFC4180, some CSV files use them so it's useful to be able to skip these lines (or even skip lines because they contain invalid data). You can use one of the predefined comment matchers:
- CommentStartsWith - matches lines that start with a specified String
- CommentMatches - matches lines that match a specified regular expression
Or if you like you can write your own by implementing the CommentMatcher interface.
Just pass your desired comment matcher to the skipComments() method when building your preferences:
private static final CsvPreference STANDARD_SKIP_COMMENTS =
new CsvPreference.Builder(CsvPreference.STANDARD_PREFERENCE).skipComments(new CommentStartsWith("#").build();
2.7 Cell processors (处理器)
Cell processors are an integral part of reading and writing with Super CSV - they automate the data type conversions, and enforce constraints. They implement the chain of responsibility design pattern - each processor has a single, well-defined purpose and can be chained together with other processors to fully automate all of the required conversions and constraint validation for a single CSV column.
A typical CellProcessor configuration for reading the following CSV file
name,birthDate,weight John,25/12/1946,83.5 Alice,06/08/1958, Bob,01/03/1984,65.0,
might look like the following:
public static final CellProcessor[] PROCESSORS = new CellProcessor[] {
null,
new ParseDate("dd/MM/yyyy"),
new Optional(new ParseDouble()) };
The number of elements in the CellProcessor array must match up with the number of columns to be processed - the file has 3 columns, so the CellProcessor array has 3 elements.
- The first processor (for the name column) is null, which indicates that no processing is required (the String is used unchanged). Semantically, it might have been better to replace that with new Optional(), which means the same thing. If we wanted to guarantee that name was supplied (i.e. it's mandatory), then we could have used new NotNull() instead (which works because empty String ("") is converted to null when reading).
- The second processor (for the birthDate column) is new ParseDate("dd/MM/yyyy"), which indicates that that column is mandatory(强制性的), and should be parsed as a Date using the supplied format.
- The third processor (for the weight column) is new Optional(new ParseDouble()), which indicates that the column is optional (可选的)(the value will be null if the column is empty), but if it's supplied then parse it as a Double.
Cell processor overview
- processors are similar to servlet filters in JEE - they can be chained together, and they can modify the data that's passed along the chain
- processors are executed from left to right (but yes, the processor's constructors are invoked from right to left!)(处理器是从左到右执行的(但是的,处理器的构造函数是从右到左调用的!))
- the number of elements in the CellProcessor array must match up with the number of columns to be processed (cellprocessor数组中的元素数必须与要处理的列数匹配。)
- a null processor means no processing is required (空处理器意味着不需要处理)
- most processors expect input to be non-null - if it's an optional column then chain an Optional() processor before it, e.g. new Optional(new ParseDouble)). Further processing (processors chained after Optional) will be skipped if the value to be read/written is null.
- all processors throw SuperCsvCellProcessorException if they encounter data they cannot process (this shouldn't normally happen if your processor configuration is correct)
- constraint-validating processors throw SuperCsvConstraintViolationException if the value does not satisfy the constraint
Available cell processors
The examples above just touch the surface of what's possible with cell processors. The following table shows all of the processors available for reading, writing, and constraint validation(约束验证).
| Reading | Writing | Reading / Writing | Constraints |
|---|---|---|---|
| ParseBigDecimal | FmtBool | Collector | DMinMax |
| ParseBool | FmtDate | ConvertNullTo | Equals |
| ParseChar | FmtNumber | HashMapper | ForbidSubStr |
| ParseDate | Optional | IsElementOf | |
| ParseDouble | StrReplace | IsIncludedIn | |
| ParseEnum | Token | LMinMax | |
| ParseInt | Trim | NotNull | |
| ParseLong | Truncate | RequireHashCode | |
| RequireSubStr | |||
| Strlen | |||
| StrMinMax | |||
| StrNotNullOrEmpty | |||
| StrRegEx | |||
| Unique | |||
| UniqueHashCode |
Joda cell processors
In addition to the above, there are a number of useful processors for reading and writing Joda-Time classes. To use these, you must include super-csv-joda (see the Downloadpage).
| Reading | Writing |
|---|---|
| ParseDateTime | FmtDateTime |
| ParseDateTimeZone | FmtDateTimeZone |
| ParseDuration | FmtDuration |
| ParseInterval | FmtInterval |
| ParseLocalDate | FmtLocalDate |
| ParseLocalDateTime | FmtLocalDateTime |
| ParseLocalTime | FmtLocalTime |
| ParsePeriod | FmtPeriod |
Java 8 cell processors
In addition to the above, there are a number of useful processors for reading and writing Java 8 classes. To use these, you must include super-csv-java8 (see the Download page).
| Reading | Writing |
|---|---|
| ParseLocalDate |
2.8 Super CSV Dozer extension
The Super CSV Dozer extension integrates Super CSV with Dozer, a powerful Javabean mapping library. Typically, Dozer requires lots of XML configuration (需要大量的XML配置)but the addition of API mapping allows Super CSV to set up Dozer mappings dynamically.
The use of Dozer allows CsvDozerBeanReader and CsvDozerBeanWriter to map simple fields (the same as CsvBeanReader and CsvBeanWriter), but to also perform deep mapping and index-based mapping as well!(但也可以执行深度映射和基于索引的映射!)
Check out the examples, or read on for more information.
Deep mapping
Deep mapping allows you to make use of the relationships between your classes.
For example, if your class had an address field, you could utilize deep mapping as follows (assuming there are valid getters/setters defined for address, city and name in the 3 involved classes):
address.city.name
Indexed-based mapping
Index-based mapping allows you to access elements of arrays and Collections by their index.
For example, if your class had a collection of Addresses, you could utilize index-based mapping to access the first one as follows:
addresses[0]
You can even combine index-based mapping with deep mapping:
addresses[0].city.name
Logging
Dozer uses SLF4J for logging. By default it will use a no-operation implementation (i.e. no logging), but you can use any of the supported implementations (logback, log4j, slf4j-simple) by placing the appropriate binding jar on the classpath.
See the SLF4J manual for more details.
Reference Mapping XML Configuration
Most of the time you'll want to let Super CSV take care of the dozer configuration by simply calling the configureBeanMapping() method. However, you might want to make use of the advanced features of Dozer (such as custom converters, bean factories, etc). In this case, you can supply Super CSV with a pre-configured DozerBeanMapper.
The following XML is provided as a reference - it's the XML configuration used in the project's unit tests. The CsvDozerBeanData class is used internally as the input/output of any Dozer mapping (each indexed column represents a column of CSV). At a minimum, you should replace the org.supercsv.mock.dozer.SurveyResponse with the class you're mapping, and update the field mappings as appropriate (but try not to change the XML attributes, as they're important!).
org.supercsv.io.dozer.CsvDozerBeanData org.supercsv.mock.dozer.SurveyResponse columns[0] age columns[1] consentGiven columns[2] answers[0].questionNo columns[3] answers[0].answer columns[4] answers[1].questionNo columns[5] answers[1].answer columns[6] answers[2].questionNo columns[7] answers[2].answer org.supercsv.mock.dozer.SurveyResponse org.supercsv.io.dozer.CsvDozerBeanData age columns[0] consentGiven columns[1] answers[0].questionNo columns[2] answers[0].answer columns[3] answers[1].questionNo columns[4] answers[1].answer columns[5] answers[2].questionNo columns[6] answers[2].answer columns[7]
EXAMPLES
2.9 Writing CSV files
This page contains some examples of writing CSV files using Super CSV. You can view the full source of the examples here. For examples of writing CSV files with Dozer (using CsvDozerBeanWriter), click here.
Example cell processor configuration
All of the examples on this page use the following cell processor configuration.
It demonstrates:
- mandatory columns (new NotNull()) 强制列
- optional columns (new Optional()), with further processing 可选列
- formatting of Dates (new FmtDate()) and Booleans (new FmtBool()) 日期格式和布尔值格式
- constraint validation of numeric ranges (new LMinMax()) and uniqueness (new UniqueHashCode()) 数值范围和唯一性的约束验证
Don't forget that you can write your own cell processors if you want!
/**
* Sets up the processors used for the examples. There are 10 CSV columns, so 10 processors are defined. All values
* are converted to Strings before writing (there's no need to convert them), and null values will be written as
* empty columns (no need to convert them to "").
*
* @return the cell processors
*/
private static CellProcessor[] getProcessors() {
final CellProcessor[] processors = new CellProcessor[] {
new UniqueHashCode(), // customerNo (must be unique)
new NotNull(), // firstName
new NotNull(), // lastName
new FmtDate("dd/MM/yyyy"), // birthDate
new NotNull(), // mailingAddress
new Optional(new FmtBool("Y", "N")), // married
new Optional(), // numberOfKids
new NotNull(), // favouriteQuote
new NotNull(), // email
new LMinMax(0L, LMinMax.MAX_LONG) // loyaltyPoints
};
return processors;
}
Writing with CsvBeanWriter
CsvBeanWriter is the easiest writer to work with. The example writes a List of CustomerBeans (which extend from PersonBean) to a CSV file.
This relies on the fact that the bean's field names match up exactly with the column names in the header of the CSV file
customerNo,firstName,lastName,birthDate,mailingAddress,married,numberOfKids,favouriteQuote,email,loyaltyPoints
and the bean has the appropriate getters defined for each field.
If your header doesn't match (the column names have spaces, for example), then you can simply define your own name mapping array that does match the field names.
Note that the cell processors are compatible with their associated field types in the bean (e.g. birthDate is a java.util.Date in the bean, and uses the FmtDate cell processor).
/**
* An example of writing using CsvBeanWriter.
*/
private static void writeWithCsvBeanWriter() throws Exception {
// create the customer beans
final CustomerBean john = new CustomerBean("1", "John", "Dunbar",
new GregorianCalendar(1945, Calendar.JUNE, 13).getTime(),
"1600 Amphitheatre Parkway\nMountain View, CA 94043\nUnited States", null, null,
"\"May the Force be with you.\" - Star Wars", "[email protected]", 0L);
final CustomerBean bob = new CustomerBean("2", "Bob", "Down",
new GregorianCalendar(1919, Calendar.FEBRUARY, 25).getTime(),
"1601 Willow Rd.\nMenlo Park, CA 94025\nUnited States", true, 0,
"\"Frankly, my dear, I don't give a damn.\" - Gone With The Wind", "[email protected]", 123456L);
final List customers = Arrays.asList(john, bob);
ICsvBeanWriter beanWriter = null;
try {
beanWriter = new CsvBeanWriter(new FileWriter("target/writeWithCsvBeanWriter.csv"),
CsvPreference.STANDARD_PREFERENCE);
// the header elements are used to map the bean values to each column (names must match)
final String[] header = new String[] { "customerNo", "firstName", "lastName", "birthDate",
"mailingAddress", "married", "numberOfKids", "favouriteQuote", "email", "loyaltyPoints" };
final CellProcessor[] processors = getProcessors();
// write the header
beanWriter.writeHeader(header);
// write the beans
for( final CustomerBean customer : customers ) {
beanWriter.write(customer, header, processors);
}
}
finally {
if( beanWriter != null ) {
beanWriter.close();
}
}
}
Output:
Writing with CsvListWriter
CsvListWriter is the most primitive writer and should only be used if it's not possible to use the other implementations.(是最原始的编写器,仅当无法使用其他实现时才应使用)
On the other hand, it is the only writer that can be used for writing CSV files with an arbitrary(任意的) number of columns (which is not technically valid CSV, but still happens), and it's a quick and dirty way to write CSV from a List or array of Strings.
/**
* An example of reading using CsvListWriter.
*/
private static void writeWithCsvListWriter() throws Exception {
// create the customer Lists (CsvListWriter also accepts arrays!)
final List
Output:
Writing with CsvMapWriter
CsvMapWriter is a good compromise if you can't use CsvBeanWriter.(如果不能使用csvbeanwriter,csvmapwriter是一个很好的折衷方案。)
/**
* An example of reading using CsvMapWriter.
*/
private static void writeWithCsvMapWriter() throws Exception {
final String[] header = new String[] { "customerNo", "firstName", "lastName", "birthDate", "mailingAddress",
"married", "numberOfKids", "favouriteQuote", "email", "loyaltyPoints" };
// create the customer Maps (using the header elements for the column keys)
final Map john = new HashMap();
john.put(header[0], "1");
john.put(header[1], "John");
john.put(header[2], "Dunbar");
john.put(header[3], new GregorianCalendar(1945, Calendar.JUNE, 13).getTime());
john.put(header[4], "1600 Amphitheatre Parkway\nMountain View, CA 94043\nUnited States");
john.put(header[5], null);
john.put(header[6], null);
john.put(header[7], "\"May the Force be with you.\" - Star Wars");
john.put(header[8], "[email protected]");
john.put(header[9], 0L);
final Map bob = new HashMap();
bob.put(header[0], "2");
bob.put(header[1], "Bob");
bob.put(header[2], "Down");
bob.put(header[3], new GregorianCalendar(1919, Calendar.FEBRUARY, 25).getTime());
bob.put(header[4], "1601 Willow Rd.\nMenlo Park, CA 94025\nUnited States");
bob.put(header[5], true);
bob.put(header[6], 0);
bob.put(header[7], "\"Frankly, my dear, I don't give a damn.\" - Gone With The Wind");
bob.put(header[8], "[email protected]");
bob.put(header[9], 123456L);
ICsvMapWriter mapWriter = null;
try {
mapWriter = new CsvMapWriter(new FileWriter("target/writeWithCsvMapWriter.csv"),
CsvPreference.STANDARD_PREFERENCE);
final CellProcessor[] processors = getProcessors();
// write the header
mapWriter.writeHeader(header);
// write the customer maps
mapWriter.write(john, header, processors);
mapWriter.write(bob, header, processors);
}
finally {
if( mapWriter != null ) {
mapWriter.close();
}
}
}
Output:
2.10 Reading CSV files
Reading CSV files
This page contains some examples of reading CSV files using Super CSV. You can view the full source of the examples here. For examples of reading CSV files with Dozer (using CsvDozerBeanReader), click here.
Example CSV file
Here is an example CSV file. It has a header and 4 rows of data, all with 10 columns. The mailingAddress column contains data that spans multiple lines and the favouriteQuotecolumn contains data with escaped quotes.
All of the examples on this page use the following cell processor configuration.
It demonstrates:
- mandatory columns (new NotNull())
- optional columns (new Optional()), with further processing
- conversion to Date (new ParseDate()), Boolean (new ParseBool()) and Integer (new ParseInt()) types
- constraint validation against regular expressions (new StrRegEx()), numeric ranges (new LMinMax()) and uniqueness (new UniqueHashCode())
Don't forget that you can write your own cell processors if you want!
/**
* Sets up the processors used for the examples. There are 10 CSV columns, so 10 processors are defined. Empty
* columns are read as null (hence the NotNull() for mandatory columns).
*
* @return the cell processors
*/
private static CellProcessor[] getProcessors() {
final String emailRegex = "[a-z0-9\\._]+@[a-z0-9\\.]+"; // just an example, not very robust!
StrRegEx.registerMessage(emailRegex, "must be a valid email address");
final CellProcessor[] processors = new CellProcessor[] {
new UniqueHashCode(), // customerNo (must be unique)
new NotNull(), // firstName
new NotNull(), // lastName
new ParseDate("dd/MM/yyyy"), // birthDate
new NotNull(), // mailingAddress
new Optional(new ParseBool()), // married
new Optional(new ParseInt()), // numberOfKids
new NotNull(), // favouriteQuote
new StrRegEx(emailRegex), // email
new LMinMax(0L, LMinMax.MAX_LONG) // loyaltyPoints
};
return processors;
}
Reading with CsvBeanReader
CsvBeanReader is the easiest reader to work with. The example reads each row from the example CSV file into a CustomerBean (which extends from PersonBean).
This relies on the fact that the column names in the header of the CSV file
customerNo,firstName,lastName,birthDate,mailingAddress,married,numberOfKids,favouriteQuote,email,loyaltyPoints
match up exactly with the bean's field names, and the bean has the appropriate setters defined for each field.
If your header doesn't match (or there is no header), then you can simply define your own name mapping array.
Note that the field types in the bean are compatible with the type returned by the cell processors (e.g. birthDate is a java.util.Date in the bean, and uses the ParseDate cell processor).
/**
* An example of reading using CsvBeanReader.
*/
private static void readWithCsvBeanReader() throws Exception {
ICsvBeanReader beanReader = null;
try {
beanReader = new CsvBeanReader(new FileReader(CSV_FILENAME), CsvPreference.STANDARD_PREFERENCE);
// the header elements are used to map the values to the bean (names must match)
final String[] header = beanReader.getHeader(true);
final CellProcessor[] processors = getProcessors();
CustomerBean customer;
while( (customer = beanReader.read(CustomerBean.class, header, processors)) != null ) {
System.out.println(String.format("lineNo=%s, rowNo=%s, customer=%s", beanReader.getLineNumber(),
beanReader.getRowNumber(), customer));
}
}
finally {
if( beanReader != null ) {
beanReader.close();
}
}
}
Output:
lineNo=4, rowNo=2, customer=CustomerBean [customerNo=1, firstName=John, lastName=Dunbar, birthDate=Wed Jun 13 00:00:00 EST 1945, mailingAddress=1600 Amphitheatre Parkway Mountain View, CA 94043 United States, married=null, numberOfKids=null, favouriteQuote="May the Force be with you." - Star Wars, [email protected], loyaltyPoints=0] lineNo=7, rowNo=3, customer=CustomerBean [customerNo=2, firstName=Bob, lastName=Down, birthDate=Tue Feb 25 00:00:00 EST 1919, mailingAddress=1601 Willow Rd. Menlo Park, CA 94025 United States, married=true, numberOfKids=0, favouriteQuote="Frankly, my dear, I don't give a damn." - Gone With The Wind, [email protected], loyaltyPoints=123456] lineNo=10, rowNo=4, customer=CustomerBean [customerNo=3, firstName=Alice, lastName=Wunderland, birthDate=Thu Aug 08 00:00:00 EST 1985, mailingAddress=One Microsoft Way Redmond, WA 98052-6399 United States, married=true, numberOfKids=0, favouriteQuote="Play it, Sam. Play "As Time Goes By."" - Casablanca, [email protected], loyaltyPoints=2255887799] lineNo=13, rowNo=5, customer=CustomerBean [customerNo=4, firstName=Bill, lastName=Jobs, birthDate=Tue Jul 10 00:00:00 EST 1973, mailingAddress=2701 San Tomas Expressway Santa Clara, CA 95050 United States, married=true, numberOfKids=3, favouriteQuote="You've got to ask yourself one question: "Do I feel lucky?" Well, do ya, punk?" - Dirty Harry, [email protected], loyaltyPoints=36]
Reading with CsvListReader
CsvListReader is the most primitive reader and should only be used if it's not possible to use the other implementations.
On the other hand, it is the only reader that can be used for reading CSV files with an arbitrary number of columns (which is not technically valid CSV, but still happens), and it's a quick and dirty way to read CSV as a List of Strings.
/**
* An example of reading using CsvListReader.
*/
private static void readWithCsvListReader() throws Exception {
ICsvListReader listReader = null;
try {
listReader = new CsvListReader(new FileReader(CSV_FILENAME), CsvPreference.STANDARD_PREFERENCE);
listReader.getHeader(true); // skip the header (can't be used with CsvListReader)
final CellProcessor[] processors = getProcessors();
List
Output:
lineNo=4, rowNo=2, customerList=[1, John, Dunbar, Wed Jun 13 00:00:00 EST 1945, 1600 Amphitheatre Parkway Mountain View, CA 94043 United States, null, null, "May the Force be with you." - Star Wars, [email protected], 0] lineNo=7, rowNo=3, customerList=[2, Bob, Down, Tue Feb 25 00:00:00 EST 1919, 1601 Willow Rd. Menlo Park, CA 94025 United States, true, 0, "Frankly, my dear, I don't give a damn." - Gone With The Wind, [email protected], 123456] lineNo=10, rowNo=4, customerList=[3, Alice, Wunderland, Thu Aug 08 00:00:00 EST 1985, One Microsoft Way Redmond, WA 98052-6399 United States, true, 0, "Play it, Sam. Play "As Time Goes By."" - Casablanca, [email protected], 2255887799] lineNo=13, rowNo=5, customerList=[4, Bill, Jobs, Tue Jul 10 00:00:00 EST 1973, 2701 San Tomas Expressway Santa Clara, CA 95050 United States, true, 3, "You've got to ask yourself one question: "Do I feel lucky?" Well, do ya, punk?" - Dirty Harry, [email protected], 36]
Reading with CsvMapReader
CsvMapReader is a good compromise if you can't use CsvBeanReader. It allows you to retrieve each column by name from the resulting Map, though you'll have to cast each column to it's appropriate type.
/**
* An example of reading using CsvMapReader.
*/
private static void readWithCsvMapReader() throws Exception {
ICsvMapReader mapReader = null;
try {
mapReader = new CsvMapReader(new FileReader(CSV_FILENAME), CsvPreference.STANDARD_PREFERENCE);
// the header columns are used as the keys to the Map
final String[] header = mapReader.getHeader(true);
final CellProcessor[] processors = getProcessors();
Map customerMap;
while( (customerMap = mapReader.read(header, processors)) != null ) {
System.out.println(String.format("lineNo=%s, rowNo=%s, customerMap=%s", mapReader.getLineNumber(),
mapReader.getRowNumber(), customerMap));
}
}
finally {
if( mapReader != null ) {
mapReader.close();
}
}
}
Output:
lineNo=4, rowNo=2, customerMap={loyaltyPoints=0, lastName=Dunbar, numberOfKids=null, married=null, [email protected], customerNo=1, birthDate=Wed Jun 13 00:00:00 EST 1945, firstName=John, mailingAddress=1600 Amphitheatre Parkway
Mountain View, CA 94043
United States, favouriteQuote="May the Force be with you." - Star Wars}
lineNo=7, rowNo=3, customerMap={loyaltyPoints=123456, lastName=Down, numberOfKids=0, married=true, [email protected], customerNo=2, birthDate=Tue Feb 25 00:00:00 EST 1919, firstName=Bob, mailingAddress=1601 Willow Rd.
Menlo Park, CA 94025
United States, favouriteQuote="Frankly, my dear, I don't give a damn." - Gone With The Wind}
lineNo=10, rowNo=4, customerMap={loyaltyPoints=2255887799, lastName=Wunderland, numberOfKids=0, married=true, [email protected], customerNo=3, birthDate=Thu Aug 08 00:00:00 EST 1985, firstName=Alice, mailingAddress=One Microsoft Way
Redmond, WA 98052-6399
United States, favouriteQuote="Play it, Sam. Play "As Time Goes By."" - Casablanca}
lineNo=13, rowNo=5, customerMap={loyaltyPoints=36, lastName=Jobs, numberOfKids=3, married=true, [email protected], customerNo=4, birthDate=Tue Jul 10 00:00:00 EST 1973, firstName=Bill, mailingAddress=2701 San Tomas Expressway
Santa Clara, CA 95050
United States, favouriteQuote="You've got to ask yourself one question: "Do I feel lucky?" Well, do ya, punk?" - Dirty Harry}
2.11 Reading CSV files with variable columns --存在null bug
2.12 Partial writing (部分写入)
Partial writing allows you to handle optional values in your data. (部分写入允许您处理数据中的可选值)
Partial writing with CsvBeanWriter
As you can see in this example, we're only writing 5 of the available fields from the bean and 2 of those are optional.(正如您在本例中看到的,我们只编写了bean中的5个可用字段,其中2个是可选的。)
This example demonstrates(演示) the two options you have when writing optional fields:
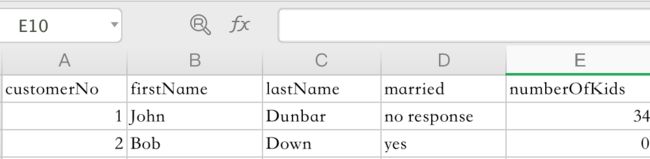
- specifying a default value if the value is null by using new ConvertNullTo() - in this case "no response" is written when married is null.(例子 当值为空使用 "no response" 代替)
- writing an empty column if the value is null - as is done by specifying new Optional() for numberOfKids (null would have the same effect as new Optional(), but it's not as meaningful)
/**
* An example of partial reading using CsvBeanWriter.
*/
private static void partialWriteWithCsvBeanWriter() throws Exception {
// create the customer beans
final CustomerBean john = new CustomerBean("1", "John", "Dunbar",
new GregorianCalendar(1945, Calendar.JUNE, 13).getTime(),
"1600 Amphitheatre Parkway\nMountain View, CA 94043\nUnited States", null, null,
"\"May the Force be with you.\" - Star Wars", "[email protected]", 0L);
final CustomerBean bob = new CustomerBean("2", "Bob", "Down",
new GregorianCalendar(1919, Calendar.FEBRUARY, 25).getTime(),
"1601 Willow Rd.\nMenlo Park, CA 94025\nUnited States", true, 0,
"\"Frankly, my dear, I don't give a damn.\" - Gone With The Wind", "[email protected]", 123456L);
final List customers = Arrays.asList(john, bob);
ICsvBeanWriter beanWriter = null;
try {
beanWriter = new CsvBeanWriter(new FileWriter("target/partialWriteWithCsvBeanWriter.csv"),
CsvPreference.STANDARD_PREFERENCE);
// only map 5 of the 10 fields
final String[] header = new String[] { "customerNo", "firstName", "lastName", "married", "numberOfKids" };
// assign a default value for married (if null), and write numberOfKids as an empty column if null
final CellProcessor[] processors = new CellProcessor[] { new UniqueHashCode(), new NotNull(),
new NotNull(), new ConvertNullTo("no response", new FmtBool("yes", "no")), new Optional() };
// write the header
beanWriter.writeHeader(header);
// write the customer beans
for( final CustomerBean customer : customers ) {
beanWriter.write(customer, header, processors);
}
}
finally {
if( beanWriter != null ) {
beanWriter.close();
}
}
}
Output:
Partial writing with CsvListWriter
This example is identical(相同) to the one above, but uses CsvListWriter.
/**
* An example of partial reading using CsvListWriter.
*/
private static void partialWriteWithCsvListWriter() throws Exception {
final String[] header = new String[] { "customerNo", "firstName", "lastName", "married", "numberOfKids" };
// create the customer Lists (CsvListWriter also accepts arrays!)
final List
Output:
Partial writing with CsvMapWriter
This example is identical to the others above, but uses CsvMapWriter. It also demonstrates(演示) that a null cell processor has the same effect as using new Optional().
/**
* An example of partial reading using CsvMapWriter.
*/
private static void partialWriteWithCsvMapWriter() throws Exception {
final String[] header = new String[] { "customerNo", "firstName", "lastName", "married", "numberOfKids" };
// create the customer Maps (using the header elements for the column keys)
final Map john = new HashMap();
john.put(header[0], "1");
john.put(header[1], "John");
john.put(header[2], "Dunbar");
john.put(header[3], null);
john.put(header[4], null);
final Map bob = new HashMap();
bob.put(header[0], "2");
bob.put(header[1], "Bob");
bob.put(header[2], "Down");
bob.put(header[3], true);
bob.put(header[4], 0);
ICsvMapWriter mapWriter = null;
try {
mapWriter = new CsvMapWriter(new FileWriter("target/partialWriteWithCsvMapWriter.csv"),
CsvPreference.STANDARD_PREFERENCE);
// assign a default value for married (if null), and write numberOfKids as an empty column if null
final CellProcessor[] processors = new CellProcessor[] { new UniqueHashCode(), new NotNull(),
new NotNull(), new ConvertNullTo("no response", new FmtBool("yes", "no")), null };
// write the header
mapWriter.writeHeader(header);
// write the customer Maps
mapWriter.write(john, header, processors);
mapWriter.write(bob, header, processors);
}
finally {
if( mapWriter != null ) {
mapWriter.close();
}
}
}
Output:
2.13 Partial reading
Partial reading allows you to ignore columns when reading CSV files by simply setting the appropriate header columns to null.
The examples on this page use the same example CSV file as the reading examples, and the full source can be found here.
Partial reading with CsvBeanReader
As you can see from the output of this example, the fields associated with the ignored columns kept their default values - only the customerNo, firstName, and lastName are populated.
Also note that the cell processors associated with the ignored columns were also set to null to avoid any unnecessary processing (cell processors are always executed).

/**
* An example of partial reading using CsvBeanReader.
*/
private static void partialReadWithCsvBeanReader() throws Exception {
ICsvBeanReader beanReader = null;
try {
beanReader = new CsvBeanReader(new FileReader(CSV_FILENAME), CsvPreference.STANDARD_PREFERENCE);
beanReader.getHeader(true); // skip past the header (we're defining our own)
// only map the first 3 columns - setting header elements to null means those columns are ignored
final String[] header = new String[] { "customerNo", "firstName", "lastName", null, null };
// no processing required for ignored columns (忽略的列不需要处理)
final CellProcessor[] processors = new CellProcessor[] { new UniqueHashCode(), new NotNull(),
new NotNull(), null, null};
CustomerBean customer;
while( (customer = beanReader.read(CustomerBean.class, header, processors)) != null ) {
System.out.println(String.format("lineNo=%s, rowNo=%s, customer=%s", beanReader.getLineNumber(),
beanReader.getRowNumber(), customer));
}
}
finally {
if( beanReader != null ) {
beanReader.close();
}
}
}
Output:
lineNo=2, rowNo=2, customer=CustomerBean{customerNo='1', firstName='John', lastName='Dunbar', birthDate=null, mailingAddress='null', married=null, numberOfKids=null, favouriteQuote='null', email='null', loyaltyPoints=null}
lineNo=3, rowNo=3, customer=CustomerBean{customerNo='2', firstName='Bob', lastName='Down', birthDate=null, mailingAddress='null', married=null, numberOfKids=null, favouriteQuote='null', email='null', loyaltyPoints=null}
Partial reading with CsvMapReader
As you can see from the output of this example, the output Map only has entries for customerNo, firstName, and lastName - the other fields were ignored.
Unlike the CsvBeanReader example above, this example defines processors for all columns. This means that constraint validation is still applied to the ignored columns, but they don't appear in the output Map.
/**
* An example of partial reading using CsvMapReader.
*/
private static void partialReadWithCsvMapReader() throws Exception {
ICsvMapReader mapReader = null;
try {
mapReader = new CsvMapReader(new FileReader(CSV_FILENAME), CsvPreference.STANDARD_PREFERENCE);
mapReader.getHeader(true); // skip past the header (we're defining our own)
// only map the first 3 columns - setting header elements to null means those columns are ignored
final String[] header = new String[] { "customerNo", "firstName", "lastName", null, "numberOfKids"};
// apply some constraints to ignored columns (just because we can)
final CellProcessor[] processors = new CellProcessor[] {
new UniqueHashCode(),
new NotNull(),
new NotNull(),
new Optional(),
new LMinMax(0L, LMinMax.MAX_LONG)
};
Map customerMap;
while( (customerMap = mapReader.read(header, processors)) != null ) {
System.out.println(String.format("lineNo=%s, rowNo=%s, customerMap=%s", mapReader.getLineNumber(),
mapReader.getRowNumber(), customerMap));
}
}
finally {
if( mapReader != null ) {
mapReader.close();
}
}
}
Output:
lineNo=2, rowNo=2, customerMap={firstName=John, lastName=Dunbar, numberOfKids=34, customerNo=1}
lineNo=3, rowNo=3, customerMap={firstName=Bob, lastName=Down, numberOfKids=0, customerNo=2}
2.14 Reading and writing CSV files with Dozer(推土机)