压力测试最大QPS瓶颈定位——CPU利用率与Load Average的区别
通过下面的几个部分的了解,可以一步一步的找出Load Average在压力测试中真正的作用。
CPU时间片
为了提高程序执行效率,大家在很多应用中都采用了多线程模式,这样可以将原来的序列化执行变为并行执行,任务的分解以及并行执行能够极大地提高程序的运行效率。但这都是代码级别的表现,而硬件是如何支持的呢?那就要靠CPU的时间片模式来说明这一切。程序的任何指令的执行往往都会要竞争CPU这个最宝贵的资源,不论你的程序分成了多少个线程去执行不同的任务,他们都必须排队等待获取这个资源来计算和处理命令。先看看单CPU的情况。下面两图描述了时间片模式和非时间片模式下的线程执行的情况:

图 1 非时间片线程执行情况
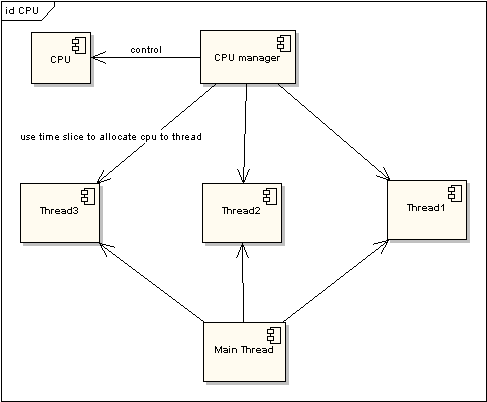
图 2 非时间片线程执行情况
在图一中可以看到,任何线程如果都排队等待CPU资源的获取,那么所谓的多线程就没有任何实际意义。图二中的CPU Manager只是我虚拟的一个角色,由它来分配和管理CPU的使用状况,此时多线程将会在运行过程中都有机会得到CPU资源,也真正实现了在单CPU的情况下实现多线程并行处理。
多CPU的情况只是单CPU的扩展,当所有的CPU都满负荷运作的时候,就会对每一个CPU采用时间片的方式来提高效率。
在Linux的内核处理过程中,每一个进程默认会有一个固定的时间片来执行命令(默认为1/100秒),这段时间内进程被分配到CPU,然后独占使用。如果使用完,同时未到时间片的规定时间,那么就主动放弃CPU的占用,如果到时间片尚未完成工作,那么CPU的使用权也会被收回,进程将会被中断挂起等待下一个时间片。
CPU利用率和Load Average的区别
0、压力测试:压力测试不仅需要对业务场景的并发用户等压力参数作模拟,同时也需要在压力测试过程中随时关注机器的性能情况,来确保压力测试的有效性。当服务器长期处于一种超负荷的情况下运行,所能接收的压力并不是我们所认为的可接受的压力。(此处见解极为深刻:也就是说单纯的施压而不去关注服务器的具体响应状况就是耍流氓而已)。就好比项目经理在给一个人估工作量的时候,每天都让这个人工作12个小时,那么所制定的项目计划就不是一个合理的计划,那个人迟早会垮掉,而影响整体的项目进度。
1、CPU利用率:CPU利用率在过去常常被我们这些外行认为是判断机器是否已经到了满负荷的一个标准。看到70%-80%的使用率就认为机器就已经压到了临界了。CPU利用率,顾名思义就是对于CPU的使用状况,这是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况,如果被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。
2、Load Average:表示的是CPU的平均负载。我们知道进程有三种基本态:挂起、就绪、进行(此外还有创建和结束)。操作系统会给“一个CPU分配一个对应的task队列”。显然:“数值为1表示刚刚好可以处理,如果大于1则表示task队列里面已经有进程在堆积了。也就是负载过重,机器处理不过来了”。
它所包含的信息不是CPU的使用率状况,而是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。为什么要统计这个信息,这个信息的对于压力测试的影响究竟是怎么样的,那就通过一个类比来解释CPU利用率和Load Average的区别以及对于压力测试的指导意义。
我们将CPU就类比为电话亭,每一个进程都是一个需要打电话的人。现在一共有4个电话亭(就好比我们的机器有4核),有10个人需要打电话。现在使用电话的规则是管理员会按照顺序给每一个人轮流分配1分钟的使用电话时间,如果使用者在1分钟内使用完毕,那么可以立刻将电话使用权返还给管理员,如果到了1分钟电话使用者还没有使用完毕,那么需要重新排队,等待再次分配使用。
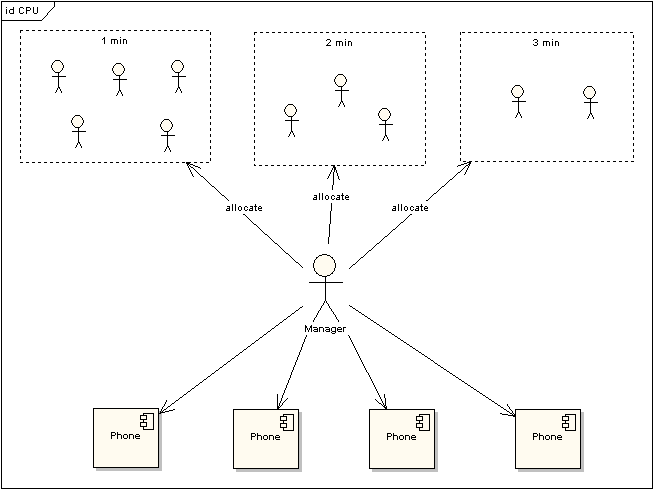
图 3 电话使用场景
上图中对于使用电话的用户又作了一次分类,1min的代表这些使用者占用电话时间小于等于1min,2min表示使用者占用电话时间小于等于2min,以此类推。根据电话使用规则,1min的用户只需要得到一次分配即可完成通话,而其他两类用户需要排队两次到三次。
电话的利用率 = sum (active use cpu time)/period
每一个分配到电话的使用者使用电话时间的总和去除以统计的时间段。这里需要注意的是是使用电话的时间总和(sum(active use cpu time)),这与占用时间的总和(sum(occupy cpu time))是有区别的。(例如一个用户得到了一分钟的使用权,在10秒钟内打了电话,然后去查询号码本花了20秒钟,再用剩下的30秒打了另一个电话,那么占用了电话1分钟,实际只是使用了40秒)
电话的Average Load:体现的是在某一统计时间段内,所有使用电话的人加上等待电话分配的人一个平均统计数。
电话利用率的统计:能够反映的是电话被使用的情况,当电话长期处于被使用而没有的到足够的时间休息间歇,那么对于电话硬件来说是一种超负荷的运作,需要调整使用频度。
显然,电话Average Load从另一个角度来展现对于电话使用状态的描述,Average Load越高说明对于电话资源的竞争越激烈,电话资源比较短缺。对于资源的申请和维护其实也是需要很大的成本,所以在这种高Average Load的情况下电话资源的长期“热竞争”也是对于硬件的一种损害。
低利用率的情况下是否会有高Load Average的情况产生呢?理解占有时间和使用时间就可以知道,当分配时间片以后,是否使用完全取决于使用者,因此完全可能出现低利用率高Load Average的情况。由此来看,仅仅从CPU的使用率来判断CPU是否处于一种超负荷的工作状态还是不够的,必须结合Load Average来全局的看CPU的使用情况和申请情况。
所以回过头来再看测试部对于Load Average的要求,在我们机器为8个CPU的情况下,控制在10 Load左右,也就是每一个CPU正在处理一个请求,同时还有2个在等待处理。看了看网上很多人的介绍一般来说Load简单的计算就是2* CPU个数减去1-2左右(这个只是网上看来的,未必是一个标准)。
补充几点:
1.对于CPU利用率和CPU Load Average的结果来判断性能问题。首先低CPU利用率不表明CPU不是瓶颈,竞争CPU的队列长期保持较长也是CPU超负荷的一种表现。对于应用来说可能会去花时间在I/O,Socket等方面,那么可以考虑是否是这些硬件的速度影响了整体的效率。
这里最好的样板范例就是我在测试中发现的一个现象:SIP当前在处理过程中,为了提高处理效率,将控制策略以及计数信息都放置在Memcached Cache里面,当我将Memcached Cache配置扩容一倍以后,CPU的利用率以及Load都有所下降,其实也就是在处理任务的过程中,等待Socket的返回对于CPU的竞争也产生了影响。
2.未来多CPU编程的重要性。现在服务器的CPU都是多CPU了,我们的服务器处理能力已经不再按照摩尔定律来发展。就我上面提到的电话亭场景来看,对于三种不同时间需求的用户来说,采用不同的分配顺序,我们可看到的Load Average就会有不同。假设我们统计Load的时间段为2分钟,如果将电话分配的顺序按照:1min的用户,2min的用户,3min的用户来分配,那么我们的Load Average将会最低,采用其他顺序将会有不同的结果。所以未来的多CPU编程可以更好的提高CPU的利用率,让程序跑的更快。
以上所提到的内容未必都是很准确或者正确,如果有任何的偏差也请大家指出,可以纠正一些不清楚的概念。
我纠结了两三天的压测瓶颈难道就是这个原因!!具体测试一波!!!!!!
1、检测load average参数。下面几个命令都可以看到 load average
top
uptime
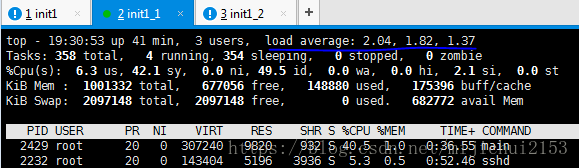
w2、压测开始前服务端和客户端的Load Average数据。
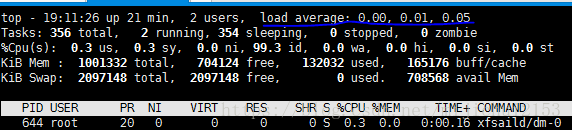
注:这里的 load average 的三个值分别指系统在最后 1/5/15分钟 的平均负载值。
根据经验:我们应该把重点放在5/15分钟的平均负载,因为1分钟的平均负载太频繁,一瞬间的高并发就会导致该值的大幅度改变。(也就是说你还是要等一会儿的。)
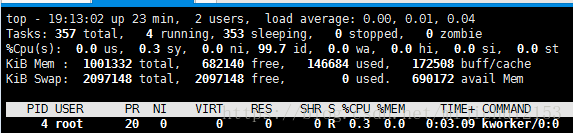
3、压测一段时间后的服务端和客户端的状态。
明显看到突破1了。说明这个时候CPU已经是瓶颈了。(呜呜,终于找到原因了!)
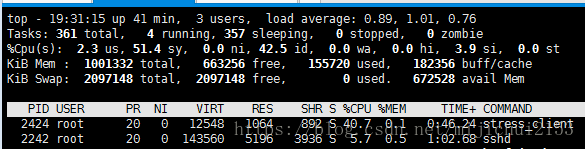
接着往下看:
服务端最高达到将近3.7,此时客户端数值会变小。——负相关是没问题的。
原因很好理解:这两者大致是成负相关的,服务端排队的更多了,有两种情况。1.说明服务端处理能力降低,显然此时给客户端的响应数就会变少,显然客户端的排队数就会变少。2.客户端之前发过来的变多了,同样会造成这样的效果。
而且两者几乎不会出现同时大于1的情况。
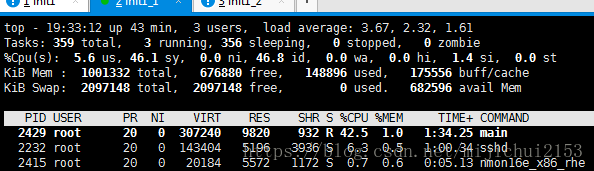

看一下运行一段时间后的情况:
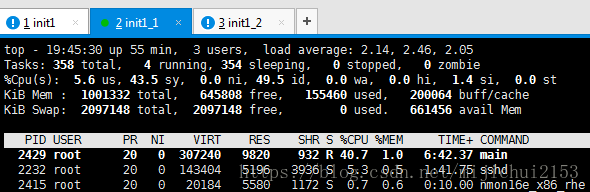

有最终较为稳定的状态可以看出来,服务端的Load Average差不多稳定在2以上,而施压端仅仅0.8左右,显然此时的瓶颈确实是在服务端。之所以这样的原因可能有如下几点:
(1)多线程优势没有发挥。服务端虽然采用线程池,但是由于只有一个CPU所以并没有充分发挥多线程的优势。其本质还是一个CPU在轮询。
(2)服务端的处理逻辑相对复杂。在这个测试中客户端需要对每一次的请求进行解析,耗费一定时间 。
结论:瓶颈来自服务端的CPU。(┭┮﹏┭┮,,,,)。、
终于这个问题理清楚了。(呜呜,,,)
注:对于单核cpu来说平均负载为1表示正好处理完全,对于2核来说为2表示正好处理完全,以此类推。
原文地址:
http://www.blogjava.net/cenwenchu/archive/2008/06/30/211712.html
另一篇非常好的链接:https://blog.csdn.net/u011183653/article/details/19489603
其他可参考:搜“CPU利用率和Load Average”即可。
https://blog.csdn.net/wutongyu344/article/details/38089603