2020,下一站
时间能治愈一切,但时间不能遗忘一切。
美团:
1面:
为什么梯度的负方向是梯度下降最快的方向?

这里引入泰勒展开式进行说明,泰勒展开式的几何意义是可以利用一个函数在某点的信息描述该点附近点的取值信息。如果一个函数任意阶都可微,那么他的泰勒展开式可以写成(1)式。当x无限趋近于x0时,该式的前两项也就是远大于后面几项,因此h(x)可以写成(2)式。

同理,数据为二维时,泰勒公式如下

现在假设红色圈圈的圆心坐标为(a,b),那么泰勒式可以写成下图的形式,使用一些代换,可最终写成(1)式的形式。接下来的任务就是找到一组![]()
![]() 是的
是的![]() 的值最小。
的值最小。
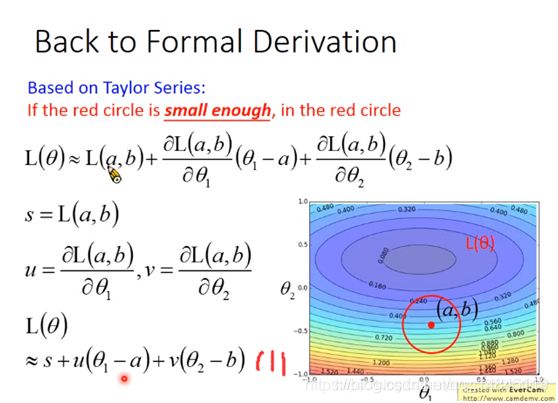
当然,我们要找的![]() 要在红色的圆内,所以要满足(1)式。
要在红色的圆内,所以要满足(1)式。
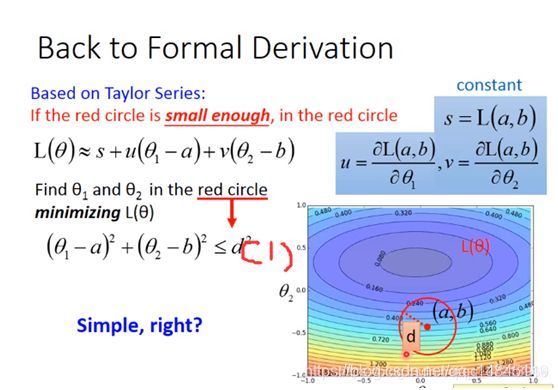
接下来进行一步代换,s是常量可以暂时忽略,那么![]() 就等于
就等于![]() 和
和![]() 的内积。
的内积。

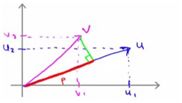
内积的几何意义如下图,表示的是向量v在u上的投影再乘以向量u,所以当v在u的负方向时他们的内积最小。
所以得到下图,当![]() 的长度等于d且处于
的长度等于d且处于![]() 的负方向时时,
的负方向时时,![]() 最小
最小

编程题:
P为给定的二维平面整数点集。定义 P 中某点x,如果x满足 P 中任意点都不在 x 的右上方区域内(横纵坐标都大于x),则称其为“最大的”。求出所有“最大的”点的集合。(所有点的横坐标和纵坐标都不重复, 坐标轴范围在[0, 1e9) 内)
如下图:实心点为满足条件的点的集合。请实现代码找到集合 P 中的所有 ”最大“ 点的集合并输出。

输入描述:
第一行输入点集的个数 N, 接下来 N 行,每行两个数字代表点的 X 轴和 Y 轴。
对于 50%的数据, 1 <= N <= 10000;
对于 100%的数据, 1 <= N <= 500000;
输出描述:
输出“最大的” 点集合, 按照 X 轴从小到大的方式输出,每行两个数字分别代表点的 X 轴和 Y轴。
输入例子1:
5
1 2
5 3
4 6
7 5
9 0
输出例子1:
4 6
7 5
9 0
思路,先基于x坐标从大到小排序,第一个肯定是最大点,然后循环遍历剩余点,并且更新maxy。
#include
using namespace std;
int comp(pair a,pair b);
int main(){
int N;
cin>>N;
int i,j;
int a,b;
vector > vec;
int result[500001][2];
pair p;
for(i=0;i max_y){ //x比他大的但统统 y都小于他,说明此点的右上方没有点
result[n][0]=vec[i].first;
result[n][1]=vec[i].second;
n++;
max_y=vec[i].second;
}
}
for(i=n-1;i>=0;i--){
cout< a,pair b){
return a.first > b.first;
}
Attention 机制:
论文:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Soft attention:
传统的Attention Mechanism就是Soft Attention,即通过确定性的得分计算来得到attended之后的编码隐状态。Soft Attention是参数化的(Parameterization),因此可导,可以被嵌入到模型中去,直接训练。梯度可以经过Attention Mechanism模块,反向传播到模型其他部分。
也有称作TOP-down Attention。
soft attention 每次会照顾到全部的位置,只是不同位置的权重不同罢了。这时 Zt 即为 ai 的加权求和。
hard attention:
Hard Attention是一个随机的过程。Hard Attention不会选择整个encoder的隐层输出做为其输入,Hard Attention会依概率Si来采样输入端的隐状态一部分来进行计算,而不是整个encoder的隐状态。为了实现梯度的反向传播,需要采用蒙特卡洛采样的方法来估计模块的梯度。
Hard attention每个时刻 t 模型的序列 [ St1,…,StL ] 只有一个取 1,其余全部为 0。
2面:
整数翻转
输入:123
输出:321
输入:-456
输出:-654
int invert(int num){
int value=1;
while(num/value>10){
value*=10;
}
int res=0;
while(numvalue>0){
res=res*10+int(num/value);+
num=num%value;
value=value/10;
}
return res
}
3面:
聊项目经验
思图场景:
1,2面:
聊项目经验
安讯达盛:
1,2面:
聊项目经验
好未来:
1面:
聊项目经验,决策树,随机森林,xgboost,faster rcnn,mtcnn,centerloss等。
笔试:
用两个栈实现一个队列&用两个队列实现一个栈
1.区别与联系
相同点:(1)栈和队列都是控制访问点的线性表;
(2)栈和队列都是允许在端点处进行数据的插入和删除的数据结构;
不同点:(1)栈遵循“后进先出(LIFO)”的原则,即只能在该线性表的一头进行数据的插入和删除,该位置称为“栈顶”, 而另外一头称为“栈底”;根据该特性,实现栈时用顺序表比较好;
(2)队列遵循“先进先出(FIFO)”的原则,即只能在队列的尾部插入元素,头部删除元素。根据该特性,在实现队 列时用链表比较好
2.应用场景
栈:括号匹配;用于计算后缀表达式,等数据结构中
队列:应用于类似现实生活中一些排队问题,例如Linux中我们学习进程间通信的时候,有一种通信方式就是“消息队列”等。
下面我们来看问题:
一、用两个栈实现队列
看到这个题,我们就要想到栈和队列的不同,所谓用两个栈实现一个队列是指,我们要实现队列的“尾插”和“头删”操作。
首先,假如我们要插入一些数据“abcd”,我们知道按照这个顺序队列出现的结果也是“abcd”,而栈会出现“dcba”,刚好相反,因此将该栈的到的数据在插入另外一个栈中就会出现我们想要的结果。因此,我们定义两个栈为“stack1”和“stack2”,栈1只用来插入数据,栈2用来删除数据栈1插入进来的数据。
通过下面的图,我们来分析一下这个模拟的场景
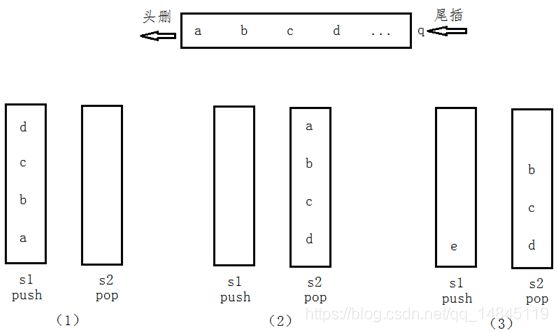
图(1):将队列中的元素“abcd”压入stack1中,此时stack2为空;
图(2):将stack1中的元素pop进stack2中,此时pop一下stack2中的元素,就可以达到和队列删除数据一样的顺序了;
图(3):可能有些人很疑惑,就像图3,当stack2只pop了一个元素a时,satck1中可能还会插入元素e,这时如果将stack1中的元素e插入stack2中,在a之后出栈的元素就是e了,显然,这样想是不对的,我们必须规定当stack2中的元素pop完之后,也就是satck2为空时,再插入stack1中的元素。
代码实现如下:
template class CQueue
{
public:
CQueue(void);
~CQueue(void);
void appendTail(const T& node);
T deleteHead();
private:
stack stack1;
stack stack2;
};
template
void CQueue::appendTail(const& T& element)//尾插
{
stack1.push(element);
}
template
T CQueue::deleteHead()
{
if (stack2.size() <= 0)
{
while (stack1.size > 0)
{
T& data = stack1.top();
stack1.pop();
stack2.push(data);
}
}
T head = stack2.top();
stack2.pop();
if (stack2.size() == 0)//当stack2为空时,抛异常
throw new exception("queue is empty");
return head;
}
二、用两个队列实现一个栈
由于栈的性质是“后进先出”的,用两个队列模拟实现栈的时候就需要两个队列的元素“互捣”,从而实现栈的这一特性
具体的做法,我们还是用一张图来看一看

图(1):当栈里面插入元素“abcd”的时候,元素a在栈底(最后出去),d在栈顶(最先出去);
图(2):将元素“abc”从q1中头删,然后再q2中尾插进来之后,头删q1中的元素“d”,就相当于实现了栈顶元素的出栈;
图(3):同理,将元素“ab”从q2中头删,然后尾插到q1中,然后再头删q2中的元素“c”;
图(4):同理,删除元素“b”;
图(5):当栈又插入一个元素“e”时,此时元素“a”不能从队列中删除,而是将元素“a”插入q2中,再删除q1中的元素“e”,最后再删除元素“a”。
说明:其中红色框代表该队列中的元素出队列,该队列为空。
代码实现如下:
template class CStack
{
public:
CStack(void);
~CStack(void);
void appendTail(const T& node);
T deleteHead();
private:
queue q1;
queue q2;
};
template
void CStack::appendTail(const T& node)//实现栈元素的插入
{
//数据的插入原则:保持一个队列为空,一个队列不为空,往不为空的队列中插入元素
if (!q1.empty())
{
q1.push(node);
}
else
{
q2.push(node);
}
}
template
T CStack::deleteHead()//实现栈元素的删除
{
int ret = 0;
if (!q1.empty())
{
int num = q1.size();
while (num > 1)
{
q2.push(q1.front());
q1.pop();
--num;
}
ret = q1.front();
q1.pop();
}
else
{
int num = q2.size();
while (num > 1)
{
q1.push(q2.front());
q2.pop();
--num;
}
ret = q2.front();
q2.pop();
}
return ret;
}
2. 像素翻转
限定语言:Python、C++、C#、Java
有一副由NxN矩阵表示的图像,这里每个像素用一个int表示,请编写一个算法,在不占用额外内存空间的情况下(即不使用缓存矩阵),将图像顺时针旋转90度。
给定一个NxN的矩阵,和矩阵的阶数N,请返回旋转后的NxN矩阵,保证N小于等于500,图像元素小于等于256。
测试样例:
[[1,2,3],[4,5,6],[7,8,9]],3
返回:[[7,4,1],[8,5,2],[9,6,3]]
class Transform {
public:
vector > transformImage(vector > mat, int n) {
for(int i=0;i 3.计算IOU代码
def iou(box0, box1):
#box:x1,y1,x2,y2
max_x = min(box0[2],box1[0])
max_y = min(box0[3],box1[1])
min_x = max(box0[2],box1[0])
min_y = max(box0[3],box1[1])
inter =(min_x-max_x)*(min_y-max_y)
union = (box0[2]-box0[0])*(box0[3]-box0[1])+(box1[2]-box1[0])*(box1[3]-box1[1])-inter
return inter/union
2面:
深度学习中,上采样的方式有哪些?
Upsample+conv,deconv,segnet中的unpool
Upsample+conv和deconv的区别?
两者大部分时刻可以替换的用,我说,upsample没有参数,deconv有参数需要学习训练。
224*224的输入,上采样到480*480,让我用deconv算,卷积核,步长,补齐等。
反卷积就是卷积反过来么,所以,我用(inputsize+2*padding-kernelsize)/stride+1=outputsize,这个卷积的式子,倒着算出来。
但是面试官说不对,让我下去自己看,还说,224上采样到280只有upsample这种方式可以做到,
我平时大部分用的也只是直接上采样2倍大小,这么不规则的上采样我也没实际整过,也不好反驳,但是还是心存疑虑。
下来自己程序实现,证明我的想法是对的,deconv也可以实现224向480上采样。
import tensorflow as tf
#反卷积
x1 = tf.ones(shape=[1,224,224,1])
y1 = tf.layers.conv2d_transpose(x1, 3, 34, strides=2, padding='valid')
#双线性插值
y2=tf.image.resize_bilinear(x1, size=[480,480])
y2= tf.layers.conv2d(y2,filters=3,kernel_size=[3,3],strides=1,padding='same')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
y1_value=sess.run(y1)
y2_value=sess.run(y2)
print("y1_value.shape:",y1_value.shape)#[1,480,480,3]
print("y2_value.shape:",y2_value.shape) #[1,480,480,3]
为什么mobilev2比mobilev1速度快?
这个问题我也不知道,但是我说可以使用profile之类的工具打印每一个op的计算量,参数里。
面试官给我的答案,说,mobilev1的开始几层的通道数大于mobilev2的开始几层的通道数,所以mobilev2速度快。
我个人觉得这个解释很牵强。
为什么度量学习人脸识别里面,优化用cos距离,而不是L2?
归一化的情况下,二者可以等价。
面试官的解释,就是softmax cross_entrop里面,softmax函数中,wx+b可以更好的解释为||w||*||x||*cos(seita),L2其实也可以,但是这块怎么换算过去。
编程题:
单链表翻转:
struct LinkNode{
int value;
LinkNode *next;
LinkNode(int v){
value=v;
next=nullptr;
}
}
LinkNode *a;
LinkNode *head;
LinkNode *pre, *aft,*tmp;
pre=a;
while(pre->next!=nullptr){
aft=pre->next;
tmp=pre->next->next;
atf->next=pre;
pre =aft;
aft=tmp;
tmp=tmp->next;
}
head=pre;
安德医智:
1面:
1.NMS
X1 | Y1 | X2 | Y2 | SCORES
---|----|----|----|-------
10 | 20 | 15 | 40 | 0.35
---|----|----|----|-------
13 | 38 | 46 | 64 | 0.51
---|----|----|----|-------
50 | 26 | 84 | 33 | 0.62
---|----|----|----|-------
43 | 49 | 34 | 58 | 0.90
---|----|----|----|-------
22 | 98 | 28 | 73 | 0.25
2.求一个二叉树从任意节点到任意节点的最大路径和。
输入: [-5,3,2,null,null,8,5]
-5
/ \
3 2
/ \
8 5
输出: 15
3.反转给定的链表
2面:
(1)爬楼梯问题,每次只能走1,2步,求爬到N阶楼梯的方法,
f=[0]*n
def func(f,n):
for i in range(n):
if i ==0:
f[i]=0
if i ==1:
f[i]=1
if i >1:
f[i]=f[i-2]+f[i-1]
return f[i]
(2)将h*w*1的numpy转化为h*w*num的onehot形式
def func(input_numpy, classnum=5):
h,w=input_numpy.shape[:2]
output_numpy= np.zeros((h,w,classnum),np.int32)
for i in range(classnum):
output_numpy[:,:,i][input_numpy==i]=1
return output_numpy
3面:
A=[a0,a1,a2……an]#n*k大小
B=[b0,b1,b2……bn]#m*k大小
输出C
Cij = |Ai-Bj|2
Examples:
A = [[1,0], [0,2]]
B = [[0,1], [2,0]]
C =[[2,1][1,8]]
A = [[1,0], [0,2],[3,1]]
B = [[0,1], [2,0]]
C =[[2,1][1,8][9,2]]
A = [[0,1], [2,0]]
B = [[1,0], [0,2],[3,1]]
C =[[2,1,9][1,8,2]]
A = [[1,0,1], [0,2,0]]
B = [[0,1,0], [2,0,2]]
C =[[3,2][1,12]]
A = [[1], [0]]
B = [[0], [2]]
C =[[1,1][0,4]]
代码1:
思路:构造2个一样大的A,B矩阵,然后进行减法操作。
import numpy as np
def all_euclidean_dist(A, B):
n,d = np.asarray(A).shape
m,d =np.asarray(B).shape
print(n,d,m)
A_nm= np.repeat(A, m,axis=0).reshape(n,d*m)
print("A_nm",A_nm)
B_nm=np.hstack((B*n)).reshape(n,d*m)
print("B_nm",B_nm)
C=(A_nm-B_nm).reshape(-1,d)
C=C*C
return np.sum(C,axis=1).reshape(n,m)
C=all_euclidean_dist(A, B)
print("C",C)
代码2:
思路:主要还是找到index索引,然后基于索引进行减法运算。
import numpy as np
a = np.array(A)
b = np.array(B)
len_a = a.shape[0]
len_b = b.shape[0]
tmp_list = np.array(list(range(len_a)))
a_idx = np.repeat(tmp_list, len_b)
print(a_idx)
tmp_list = np.array(list(range(len_b)))
tmp_list = np.expand_dims(tmp_list, axis=0)
b_idx = np.repeat(tmp_list, len_a, axis=0).flatten()
print(b_idx)
c = a[a_idx] - b[b_idx]
c = np.power(c, 2)
c = np.sum(c, axis=1)
print(c)
其他python进行矩阵堆叠的接口:
np.repeat
np.vstack
np.hstack
np.tile
滴滴:
1面:
聊项目经验
编程:
大字符串中是否包含小字符串(只要连续的排列组合满足就算包含)
a1="asdffffds"
a2="fdf"
def a2_in_a1(a1,a2):
for i in range(len(a1)-len(a2)):
temp_a1=a1[i:i+len(a2)]
temp_dict = {}
for value in temp_a1:
if value in temp_dict.keys():
temp_dict[value]+=1
else:
temp_dict[value]=1
for value in a2:
if value in temp_dict.keys():
temp_dict[value]-=1
else:
temp_dict[value]=1
for key_value in temp_dict.items():
if key_value [1]!=0:
return false
return true
2面:
聊项目经验,
(1)1亿个时间戳排序
思路,分桶+hash
(2)leetcode , Search a 2D Matrix
编程题:MLP,使用TensorFlow完成,
#coding=UTF-8
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import math
from keras.utils import to_categorical
# ------数据准备-------------------
# 生成1000个数据对作为训练集
batch_size =50
train_data = np.load("model/train_data.npy")
#train_data = train_data[138:340]
x=tf.placeholder(tf.float32,[None,1,1,4], name='input')
y=tf.placeholder(tf.float32,[None,3])
# ----------训练------------------
# add hidden layer
x_squeeze = tf.squeeze(x, axis =[1, 2])
fc1 = tf.layers.dense(x_squeeze, 10, activation=tf.nn.relu)
fc2 = tf.layers.dense(fc1, 20, activation=tf.nn.relu)
fc3 = tf.layers.dense(fc2, 20, activation=tf.nn.relu)
y_ = tf.nn.softmax(tf.layers.dense(fc3, 3, activation=None),name='output')
# 定义loss
loss = tf.reduce_mean(-tf.reduce_sum(y * tf.log(y_), axis=1))#tf.reduce_mean(tf.square(y - y_))
# 梯度下降法优化参数(学习率为lr)
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(0.1,global_step, 1000,0.95,staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# 通过session执行上述操作
init = tf.global_variables_initializer()
# 执行训练,根据loss阈值退出迭代
step = 0
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
#saver.restore(sess, "model/co2.ckpt-5")
while True:
x_input=train_data[step:step+batch_size,:-1].reshape(-1,1,1,4).astype(np.float32)
y_input=train_data[:,-1].reshape(-1,1).astype(np.float32)-1.0
y_input = to_categorical(y_input)[step:step+batch_size,:]
#print(x_input.shape,y_input.shape)
_,out_y,out_loss=sess.run([train_step,y_,loss],feed_dict={x:x_input,y:y_input})
#print('step=', step, 'loss=', out_loss)
#test
if step%400==0:
x_input=train_data[:,:-1].reshape(-1,1,1,4).astype(np.float32)
y_input=train_data[:,-1].reshape(-1,1).astype(np.float32)-1.0
y_input_onehot = to_categorical(y_input)
out_y = sess.run([y_],feed_dict={x:x_input,y:y_input_onehot})
out_y = np.asarray(out_y).reshape(-1,3)
acc = np.sum(np.asarray(y_input==np.argmax(out_y,axis=1).reshape(-1,1),np.int32))/y_input.shape[0]
print("all acc:",acc)
#print(out_y.shape,y_input[:10],np.argmax(np.asarray(out_y),axis=1))
#print(y_input==np.argmax(out_y,axis=1).reshape(-1,1))
#break
if acc>0.7:
saver.save(sess,'model/classify.ckpt',global_step=step)
break
step = (step+1)%(train_data.shape[0]-batch_size)
腾讯地图:
1面:
聊项目经验,深度学习基础知识。
编程题:
A:一个数组中存在若干数字(正负都有),返回其中最大的子序列和。如1、-1、2、3、-4、-5、4、5、-2,返回9。
int get_max _sum(const int *array, int cnt){
int result = INT_MIN, f = 0;
for (int i = 0; i < cnt; ++i) {
f = max(f + array [i], array [i]);
result = max(result, f);
}
return result;
}
B:在一个排序二叉树中,找到第_K个大的结点返回
思路:中序遍历,正好是从小到大排序
TreeNode *get kth node(TreeNode *root, int K){
If (root->right!=NULL)
return get kth node(root->right), K);
K--;
If(K==0){
return root;
}
If (root->left!=NULL)
return get kth node(root->left), K);
}
C:一个返回1和0的函数tick(),返回1的概率是p,返回0的概率是1-p,请在实现一个新的函数,借助tick0来实现一个返回1,0,要求,返回1和0的概率分别是50%。
int get new tick()
思路:
由于需要产生1/2,而用1位0,或1位1无法产生等概率,因此,考虑将随机数扩展成2位:
00 p*p
01 p*(1-p)
10 (1-p)*p
11 (1-p)*(1-p)
有上述分析知道,01和10是等概率的,因此我们只需要产生01和10就行了。
于是可以,遇到00和11就丢弃,只记录01和10。可以令,01表示0,10表示1,则等概率1/2产生0和1了。
int get new tick(){
int f1=tick();
int f2=tick();
if (f1==0&&f2==1)
return 0;
else if ( f1==1&&f2==0)
return 1;
}
D:判断两个单链表是否有交点,如果有则返回交点的指针,没有则返回NULL
思路:
两个单链表如果相交,只能是两个链表有共同的尾巴,比如Y字型,而不可能是X字型。
那么共同的尾巴部分的长度是相等的。
所以长的链表先后移长链表长度-短链表长度的步长,然后,两个链表一起后移,如果next指针的地址相等则该节点就是交叉点,说明存在相交,否则不存在相交。
bool judge(LinkNode *root1, LinkNode *root2){
int root1_length=0;
int root2_length=0;
LinkNode *temp= root1;
while(temp ->next!=NULL){
root1_length+=1;
temp=temp->next;
}
temp= root2;
while(temp ->next!=NULL){
root2_length+=1;
}
If (root1_length> root2_length){
Int v= root1_length- root2_length;
while(v>0){
root1= root1->next;
v--;
}
}else
If (root1_length< root2_length){
Int v= root2_length- root1_length;
while(v>0){
root2= root2->next;
v--;
}
}
while(root1->next!=NULL && root2->next!=NULL){
if (root1->next== root2->next)
return true;
else{
root1= root1->next;
root2= root2->next;
}
}
return false;
}
E:1亿的字符串key ,如何实现查找。至少介绍两种以上的方法,并对比它们在时间、空间_上的优劣。
2面:
聊项目经验,根据自己的项目经验提一些问题,让自己回答解决方法。
根据他们自己的实际项目中的问题,回答一些解决的方法和思路。
可以感觉到是一种更高层次的面试,更加关注的是解决问题的思路,平时的积累,现场的反应思维能力。
大道至简,返璞归真。
3面:
自我介绍
一个项目经验
需要了解对方的
新氧科技:
1面:
主要还是项目经验,已经一些深度学习的基本知识。
2面:
深度学习,机器学习,图像处理等等。
为什么BN在减均值和归一化之后,还需要进行一个乘scale,加shift的操作呢?
我自己的感觉,(1)保证数据分类,BN前后是一样的,像norm face不乘scale,就不能收敛。(2)乘scale,加shift的操作类似于一个w*x+b的操作,也就是类似于一个卷积操作。也就是说,BN可以类似于一个归一化的卷积操作。
3面:
项目经验,个人规划,意向,离职原因等。
安迅达盛:
1面:
面试基本图像知识。
2面:
Python 中new和init的区别?
其实我从没用过new这个方法,这里顺便学习一下。
【同】
二者均是Python面向对象语言中的函数,__new__比较少用,__init__则用的比较多。
【异】
__new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例对象,是个静态方法。
__init__是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值,通常用在初始化一个类实例的时候。是一个实例方法。
也就是: __new__先被调用,__init__后被调用,__new__的返回值(实例)将传递给__init__方法的第一个参数,然后__init__给这个实例设置一些参数。
新华智云:
聊项目经验
编程题:
(1)任意长度的字符串,输出其全部的排列组合,比如123,132,213,231,312,321。
思路,字典序,康拓编码
(2)给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例:
s = "3[a]2[bc]", 返回 "aaabcbc".
s = "3[a2[c]]", 返回 "accaccacc".
s = "2[abc]3[cd]ef", 返回 "abcabccdcdcdef"
代码:
class Solution:
def decodeString(self, s: str) -> str:
stack = []
res = ''
for i, _s in enumerate(s):
if _s != ']': # 不是右括号就一直进栈
stack.append(_s)
else:
string = ‘’ # 先收集要加倍的字符串
while not stack[-1].isnumeric():
string = stack.pop()+string
times = '' # 再收集加倍倍数
while stack and stack[-1].isnumeric():
times = stack.pop()+times
if times: # 如果有倍数则加倍
string = string[1:]*int(times)
if stack: # 还有没处理完的上级,把处理好的字符串入栈等待处理
stack.append(string)
else: # 前面的字符串处理完毕了,直接把字符串加入答案
res += string
贝壳找房:
1面:
项目经验
面试官提到的一个对个类别分类,加入分类错误的惩罚的思想非常不错,
比如正常的focal loss=1/4*(1-y)2*y_hat*log(y)
而假设有0,1,2这样的3个分类类别,那么加入的惩罚就是分类错误的惩罚,比如label=0,分类预测为1的惩罚为abs(1-0),分类预测为2的惩罚就会变大为abs(2-0),这样softmax_cross_entrop就变化为下面的形式,
Punish_loss = abs(y-y_hat)*y_hat*log(y)
非常不错的想法,也好实现,这里分享一下。
C++中继承和多态的区别?
继承是指,子类可以自动获得父类提供的函数,如父类提供了foo函数,则子类也会有foo函数。
多态是指,子类可以重写父类的某个函数,从而为这个函数提供不同于父类的行为。一个父类的多个子类可以为同一个函数提供不同的实现,从而在父类这个公共的接口下,表现出多种行为。
2面:
项目经验
3面:
最新的项目经验,
自己的优势,代码和算法水平
建议:
- 尽量不要辞职,寒冬+疫情,找工作会很很难。能最终拿到一个offer,一定是技术+运气,一定是占据了天时+地利+人和的结果。

- 健康最重要,坚持锻炼身体
- 多学习新知识,不进则退
- 学会减压,乐观积极,泰山压顶,清风拂面
- 学会自律+节省,因为钱真的不好赚