1. 数据获取
首先用高德地图卫星图模式,定位到首都机场、上海虹桥机场、浦东机场和广州白云机场等机场,手动截图了500张飞机图片和300张非飞机(机场、草地、建筑、海岸等)图片:


2. 数据预处理
2.1 数据增加
然后写一段代码对这800张做数据增加,采用基本的数据增加手段:镜像、旋转、随机裁剪、随机明暗和HSV空间随机扰动等。数据增加后得到5000张飞机照片和3000张非飞机照片。选择其中的4000张飞机照片和2400张非飞机照片放在一个名为train的文件夹里,剩下的照片放在一个名为test的文件夹里,如图:

2.2 生成LMDB数据
虽说caffe支持jpg等原始图片格式的图片数据输入,但是在caffe的图片训练中,LMDB才是最常用的数据格式。LMDB数据格式有两个显著的优点:
1、速度更快;
2、支持多个程序同时读取同一数据;
caffe内置用于将图片转化为LMDB格式数据的工具:convert_imageset.exe。以本人的电脑为例,该工具位于:
C:\Users\liuhuaqing\caffe-windows\build\tools\Release\convert_imageset.exe
CMD调用该工具生成LMDB数据的命令(示例)是:
"C:\Users\liuhuaqing\caffe-windows\build\tools\Release\convert_imageset.exe" ./ train.txt train_lmdb -resize_width 224 -resize_height 224 -shuffle
其中:
-shuffle表示随机打乱train.txt中文件的顺序;
train_lmdb表示生成的LMDB文件的名称;
-resize_width 224 -resize_height 224 表示重新调整图片大小为宽度224*高度224,这是可选项,可以不要,但是考虑到ResNet的输入图片大小是224*224,因此有必要增加这一操作。
可以看到命令行中有一个输入参数train.txt,这个是源图片文件路径的列表,如下图所示,每一行表示一个图片,前面为图片路径,后面是标签:
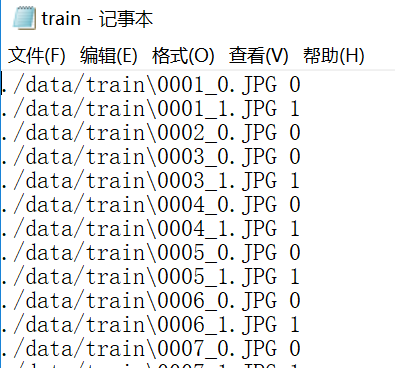
所以调用convert_imageset.exe工具之前,必须先生成这么一个txt文件。
同理,调用convert_imageset.exe工具生成test_lmdb文件。最终我们得到了在工作路径上两个lmdb文件夹:

3. 迁移学习
3.1 预训练模型文件下载
在https://github.com/cvjena/cnn-models/tree/master/ResNet_preact/ResNet10_cvgj下载在ImageNet数据集上训练好的ResNet模型相关文件:
train.prototxt
resnet10_cvgj_iter、20000.caffemodel
train.solver文件
3.2 模型文件改写
复制train.prototxt文件重命名为plane_resnet_10_cvgj_finetune_val.prototxt,打开做如下改写:
1、首行增加一段:name: "Plane-ResNet-10-CVGJ"
2、TRAIN阶段的数据输入层更改如下图所示:

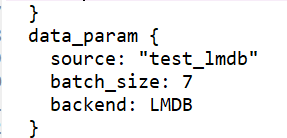
3、TEST阶段数据输入层更改如下图所示:
4、将最后一个全连接层(即score层)的num_output: 1000改为num_output: 2。
5、由于我们只对预训练模型中的以下几层做微调:
a、最后一个残差模块,包括layer_512_1_conv1、layer_512_1_conv2、 layer_512_1_conv_expand;
b、全部Scale层;
c、最后一个全连接层(即score层)。
因此将除了上述之外的其它所有层的学习率lr_mult改为0。
3.3 solver文件改写
将solver文件改为如下:

4. 训练
以上一切准备就绪后,打开CMD窗口,cd到当前工作目录,执行以下命令:
"C:\Users\liuhuaqing\caffe-windows\build\install\bin\caffe.exe" train -solver solver.prototxt -log_dir ./
搞定