序
本文主要聊一聊主流开源产品的replication方式。
replication
replication和partition/sharding是分布式系统必备的两种能力。具体详见复制、分片和路由.
对于海量数据来说,replication一方面可以增加冗余,保证系统可用性,一方面还可以提升读取的效率。
本文主要聚焦于replication,即假设每个node都足以存下整个副本。
replication type
按照有无leader以及leader数目可以分为:
- single leader replication
即一主多从的复制方式,由leader同步/通知follower,只有leader能接受写操作,follower只能读不能写。 - multi leader replication
即多主多从,有多个leader分布在不同node,同时接受写入操作,而每个leader之间相互为follower。比较适合多数据中心的场景,不过对于并发写多数据中心冲突解决的复杂度也增加。 - leaderless replication
无中心的复制,不区分主从副本,任意节点都可以接收请求,然后又它去通知其他副本进行更新。
leader-based replication way
具体详见副本更新策略,主要有如下几种
- sync replication
同步复制,这个可以保证强一致,不过follower多的情况下,延迟太大,一般很少使用 - async replication
异步复制,这个可能造成读不一致,但是写入效率高 - semi sync replication
半同步,一般采用quorum的机制,即当写入的节点个数满足指定条件,即算写入成功,然后通过并发请求多个node来满足读取的一致性
leaderless replication way
无中心的复制,可以分为三种拓扑结构,环形、星/树型、网状拓扑
replication implementation
主要分为以下几种
- statement/trigger-based replication
这种是基于数据库的语句或触发器来实现的复制,但是存在一定的问题,比如一些now()/rand()/seq()等函数可能造成主从同步的不确定性,比如从节点的now()/rand()等执行结果跟master不一样。mysql5.1版本之前用的是这种,5.1+版本,当有不确定语句时,就切换为row-based log replication - write-ahead-log replication(
WAL)
WAL是数据库中一种高效的日志算法,对于非内存数据库而言,磁盘I/O操作是数据库效率的一大瓶颈。在相同的数据量下,采用WAL日志的数据库系统在事务提交时,磁盘写操作只有传统的回滚日志的一半左右,大大提高了数据库磁盘I/O操作的效率,从而提高了数据库的性能。
PG使用的就是这种。
- row-based-log replication(
logical log)
WAL跟数据库存储引擎是耦合的,而row-based-log也称作logical log,是跟存储引擎无关的,采用的是change data capture的方式,这个就很方便异构数据源的数据同步。
replication带来的问题
replication lag
- 同步差异大
比如mongo的oplog太小,跟不上写入速度,造成旧的操作日志就会被丢弃,主从延迟一直增加导致副本同步失败。 - 新加入node的同步
比如在线扩容增加replication,这个时候就涉及新节点的node的replication问题,一般这类同步的方式跟正常在线节点的同步方式是分开的,新的node同步到一定的时候才转为正常的增量同步方式。
master slave failover
一般replication增加冗余常用来做master的的热备(支持查询)/温备(不支持查询)
- 当主节点挂的时候,这个时候就涉及选哪个replication为主的问题
- 当旧的master恢复的时候,这个时候就涉及旧master与新master之间的数据差异的处理
read consistency
一旦replication支持读取的话,那么就涉及读的一致性问题,一般理论上除了强一致外,有这几种最终一致性:
- (1)因果一致性(Causal consistency)
即进程A在更新完数据后通知进程B,那么之后进程B对该项数据的范围都是进程A更新后的最新值。 - (2)读己之所写(Read your writes)
进程A更新一项数据后,它自己总是能访问到自己更新过的最新值。 - (3)会话一致性(Session consistency)
将数据一致性框定在会话当中,在一个会话当中实现读己之所写的一致性。即执行更新后,客户端在同一个会话中始终能读到该项数据的最新值 - (4)单调读一致性(Monotonic read consistency)
如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。 - (5)单调写一致性(Monotoic write consistency)
一个系统需要保证来自同一个进程的写操作被顺序执行。
读取的话,涉及读己所写,因果读(
针对操作有序)、单调读(不读到旧数据)
quorum/RWN方案解决读冲突
write quorum
假设某份数据需要复制到3个节点,为了保证强一致性,不需要所有节点都确认写入操作,只需要其中两个节点(也就是超半数节点)确认就可以了。在这种情况下,如果发生两个相互冲突的写入操作,那么只有其中一个操作能为超过半数的节点所认可,这就是写入仲裁(write quorum),如果用稍微正规一点的方式说,那就是W>N/2,这个不等式的意思是参与写入操作的节点数W,必须超过副本节点数N的一半,副本节点数又称为复制因子(replication factor)。
read quorum
读取仲裁(read quorum),也就是说想保证能够读到最新的数据,必须与多少个节点联系才行。假设写入操作需要两个节点来确认(W=2),那么我们至少得联系两个节点,才能保证获取到最新数据。然而,假如某些写入操作只被一个节点所确认(W=1),那么我们就必须3个节点都通信一遍,才能确保获取到的数据是最新的。一个情况下,由于写入操作没有获得足够的节点支持率,所以可能会产生更新冲突。但是,只要从足够数量的节点中读出数据,就一定能侦测出此类冲突。因此,即使在写入操作不具备强一致性的情况下,也可以实现除具有强一致性的读取操作来。
RWN
- R
执行读取操作时所需联系的节点数R - W
确认写入操作时所需征询的节点数W - N
复制因子N
这三者之间的关系,可以用一个不等式来表述,即只有当R+W>N的时候,才能保证读取操作的强一致性。
主流开源产品的replication概览
| 产品 | 复制方式 | 实现方式 | 其他 |
|---|---|---|---|
| mysql | 主从半同步 | MySQL 5.0及之前的版本仅支持statement-based的复制,5.1+版本,当有不确定语句时,就切换为row-based log replication | 主从延迟处理 |
| kafka | 主从ISR半同步 | leader写入消息并复制到所有follower,ISR中的副本写入成功返回ack给leader才算commit成功 | 生产者可以选择是否等待ISR的ack |
| elasticsearch | 主从半同步,默认replication=sync | consistency可选的值有quorum、one和all。默认的设置为quorum | tradelog及fsync以及refresh |
| pg | 主从异步复制 | 基于Write-ahead log | archive及stream方式 |
| redis | 主从异步复制 | 增量Redis Protocol(全量增量长连接) | Sentinel failover |
| mongo | 主从异步,Replica set模式 | 持久化的ring-buffer local.oplog.rs(initial_sync,steady-sync) | Arbiter选主 |
可以看见一些对一致性要求高的,可以采用半同步的机制,一般是基于quorum机制,像es就是基于这种机制,而kafka是采用ISR机制,二者都可以配置
其他的基本是异步复制,对于新加入的node以及recovery node的同步来说,采用不同的同步方式,新加入的一般采用全量同步,而处于正常状态的node,一般是增量同步
kafka的ISR(In-Sync Replicas的缩写,表示副本同步队列)
所有的副本(replicas)统称为Assigned Replicas,即AR。ISR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟,任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
当producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower“落后”太多或者失效,leader将会把它从ISR中删除。

由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
es的副本一致性
es的一致性主要有两个方面:
- 使用lucene索引机制带来的refresh问题
在Elasticsearch和磁盘之间是文件系统缓存。 在内存索引缓冲区中的文档会被写入到一个新的段中,但是这里新段会被先写入到文件系统缓存--这一步代价会比较低,稍后再被刷新到磁盘--这一步代价比较高。不过只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch是近实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新.
refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来.
- 使用分片和复制带来的副本一致性问题(consistency:one、all、quorum)
在有副本配置的情况下,数据从发向Elasticsearch节点,到接到Elasticsearch节点响应返回,流向如下
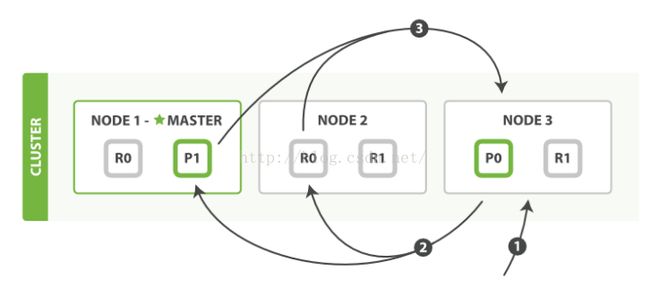
- 1)客户端请求发送给Node1节点,这里也可以发送给其他节点
- 2)Node1节点用数据的_id计算出数据应该存储在shard0上,通过cluster state信息发现shard0的主分片在Node3节点上,Node1转发请求数据给Node3,Node3完成数据的索引,索引过程在上篇博客中详细介绍了。
- 3)Node3并行转发数据给分配有shard0的副本分片Node1和Node2上。当收到任一节点汇报副本分片数据写入成功以后,Node3即返回给初始的接受节点Node1,宣布数据写入成功。Node1成功返回给客户端。
小结
不同产品的replication细节不尽相同,但是大的理论是一致的,对于replication除了关注上述的replication相关方式外,还需要额外关注replication相关异常场景,才能做到成熟应用。
doc
- kafka 数据可靠性深度解读
- RWN及Quorum与强一致性
- es一致性问题
- es的写入过程
- Elasticsearch学习笔记(三)Elasticsearch集群分片的读写操作流程
- ElasticSearch权威指南-分片内部原理