本文来自于腾讯bugly开发者社区,非经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/57bec...
作者:陈昱全
引言
随着项目中动态链接库越来越多,我们也遇到了很多奇怪的问题,比如只在某一种 OS 上会出现的 java.lang.UnsatisfiedLinkError,但是明明我们动态库名称没错,ABI 也没错,方法也能对应的上,而且还只出现在某一些机型上,搞的我们百思不得其解。为了找到出现千奇百怪问题的原因,和能够提供一个方式来解决一些比较奇怪的动态库加载的问题,我发现了解一下 so 的加载流程是非常有必要的了,便于我们发现问题和解决问题,这就是本文的由来。
要想了解动态链接库是如何加载的,首先是查看动态链接库是怎么加载的,从我们日常调用的 System.loadLibrary 开始。
为了书写方便,后文中会用“so”来简单替代“动态链接库”概念。
1、动态链接库的加载流程
首先从宏观流程上来看,对于 load 过程我们分为 find&load,首先是要找到 so 所在的位置,然后才是 load 加载进内存,同时对于 dalvik 和 art 虚拟机来说,他们加载 so 的流程和方式也不尽相同,考虑到历史的进程我们分析 art 虚拟机的加载方式,先贴一张图看看 so 加载的大概流程。
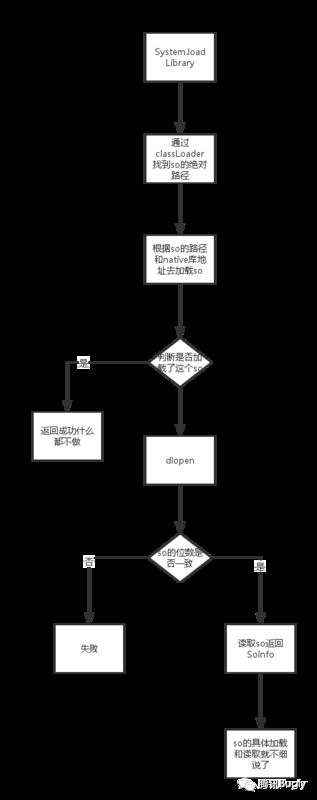
我的疑问
ClassLoader 是如何去找到so的呢?
如何判断这个 so 是否加载过?
native 库的地址是如何来的
so 是怎么弄到 native 库里面去的?
如何决定 app 进程是32位还是64位的?
找到以上的几个问题的答案,可以帮我们了解到哪个步骤没有找到动态链接库,是因为名字不对,还是 app 安装后没有拷贝过来动态链接库还是其他原因等,我们先从第一个问题来了解。
2、ClassLoader 如何找 so 呢?
首先我们从调用源码看起,了解 System.loadLibrary 是如何去找到 so 的。
System.java
public void loadLibrary(String nickname) {
loadLibrary(nickname, VMStack.getCallingClassLoader());
}通过 ClassLoader 的 findLibaray 来找到 so 的地址
void loadLibrary(String libraryName, ClassLoader loader) {
if (loader != null) {
String filename = loader.findLibrary(libraryName);
if (filename == null) {
// It's not necessarily true that the ClassLoader used
// System.mapLibraryName, but the default setup does, and it's
// misleading to say we didn't find "libMyLibrary.so" when we
// actually searched for "liblibMyLibrary.so.so".
throw new UnsatisfiedLinkError(loader + " couldn't find \"" +
System.mapLibraryName(libraryName) + "\"");
}
String error = doLoad(filename, loader);
if (error != null) {
throw new UnsatisfiedLinkError(error);
}
return;
}如果这里没有找到就要抛出来 so 没有找到的错误了,这个也是我们非常常见的错误。所以这里我们很需要知道这个 ClassLoader 是哪里来的。
2.1 ClassLoader 怎么来的?
这里的一切都要比较熟悉 app 的启动流程,关于 app 启动的流程网上已经说过很多了,我就不再详细说了,一个 app 的启动入口是在 ActivityThread 的 main 函数里,这里启动了我们的 UI 线程,最终启动流程会走到我们在 ActivityThread 的 handleBindApplication 函数中。
private void handleBindApplication(AppBindData data) {
......
......
ContextImpl instrContext = ContextImpl.createAppContext(this, pi);
try {
java.lang.ClassLoader cl = instrContext.getClassLoader();
mInstrumentation = (Instrumentation)
cl.loadClass(data.instrumentationName.getClassName()).newInstance();
} catch (Exception e) {
throw new RuntimeException(
"Unable to instantiate instrumentation "
+ data.instrumentationName + ": " + e.toString(), e);
}
mInstrumentation.init(this, instrContext, appContext,
new ComponentName(ii.packageName, ii.name), data.instrumentationWatcher,
data.instrumentationUiAutomationConnection);
......
......
} finally {
StrictMode.setThreadPolicy(savedPolicy);
}
}我们找到了这个 classLoader 是从 ContextImpl 中拿过来的,有兴趣的同学可以一步步看看代码,最后的初始化其实是在 ApplicationLoaders 的 getClassLoader 中
ApplicationLoaders.java
public ClassLoader getClassLoader(String zip, String libPath, ClassLoader parent)
{
......
......
if (parent == baseParent) {
ClassLoader loader = mLoaders.get(zip);
if (loader != null) {
return loader;
}
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, zip);
PathClassLoader pathClassloader =
new PathClassLoader(zip, libPath, parent);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
mLoaders.put(zip, pathClassloader);
return pathClassloader;
}
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, zip);
PathClassLoader pathClassloader = new PathClassLoader(zip, parent);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
return pathClassloader;
}
}其实是一个 PathClassLoader,他的基类是 BaseDexClassLoader,在他其中的实现了我们上文看到的 findLibrary 这个函数,通过 DexPathList 去 findLibrary。
BaseDexClassLoader.java
public String findLibrary(String libraryName) {
String fileName = System.mapLibraryName(libraryName);
for (File directory : nativeLibraryDirectories) {
File file = new File(directory, fileName);
if (file.exists() && file.isFile() && file.canRead()) {
return file.getPath();
}
}
return null;
}代码的意思很简单,其实就是首先给 so 拼成完整的名字比如a拼接成 liba.so 这样,然后再从存放 so 的文件夹中找这个 so,在哪个文件夹里面找到了,我们就返回他的绝对路径。所以这里最关键的就是如何知道这个 nativeLibraryDirectories 的值是多少,于是也引出我们下一个疑问, native 地址库是怎么来的,是多少呢?
3 nativeLibraryDirectories 是怎么来的?
通过查看 DexPathList 可以知道,这个 nativeLibraryDirectories 的值来自于2个方面,一个是来自外部传过来的 libraryPath,一个是来自 java.library.path 这个环境变量的值。
DexPathList.java
private static File[] splitLibraryPath(String path) {
/*
* Native libraries may exist in both the system and
* application library paths, and we use this search order:
*
* 1. this class loader's library path for application
* libraries
* 2. the VM's library path from the system
* property for system libraries
*
* This order was reversed prior to Gingerbread; see http://b/2933456.
*/
ArrayList result = splitPaths(
path, System.getProperty("java.library.path", "."), true);
return result.toArray(new File[result.size()]);
} 环境变量的值大家 getProp 一下就知道是什么值了,一般来说大家在 so 找不到的情况下能看到这个环境变量的值,比如大部分只支持32位的系统情况是这个:“/vendor/lib,/system/lib”,搞清楚了这个环境变量,重点还是要知道这个 libraryPath 是如何来的,还记得我们前面讲了 ClassLoader 是如何来的吗,其实在初始化 ClassLoader 的时候从外面告诉了 Loader 这个文件夹的地址是哪里来的,在 LoadedApk 的 getClassLoader 代码中我们发现了主要是 libPath 这个 list 的 path 组成的,而这个 list 的组成主要来自下面2个地方:
LoadedApk.java
libPaths.add(mLibDir);
还有一个
// Add path to libraries in apk for current abi
if (mApplicationInfo.primaryCpuAbi != null) {
for (String apk : apkPaths) {
libPaths.add(apk + "!/lib/" + mApplicationInfo.primaryCpuAbi);
}
}这个 apkPath 大部分情况都会是 apk 的安装路径,对于用户的 app 大部分路径都是在 /data/app 下,所以我们要确认以下2个关键的值是怎么来的,一个是 mLibDir,另外一个就是这个 primaryCpuAbi 的值。
3.1 mLibDir 是哪里来的?
首先我们来看看这个 mLibDir 是怎么来的,通过观察代码我们了解到这个 mLibDir 其实就是 ApplicationInfo 里面 nativeLibraryDir 来的,那么这个 nativeLibraryDir 又是如何来的呢,这个我们还得从 App 安装说起了,由于本文的重点是讲述 so 的加载,所以这里不细说 App 安装的细节了,我这里重点列一下这个 nativeLibraryDir 是怎么来的。
不论是替换还是新安装,都会调用 PackageManagerService 的 scanPackageLI 函数,然后跑去 scanPackageDirtyLI,在 scanPackageDirtyLI 这个函数上,我们可以找到这个设置 nativeLibraryDir 的逻辑。
PackageManagerService.java
// Give ourselves some initial paths; we'll come back for another
// pass once we've determined ABI below.
setNativeLibraryPaths(pkg);info.nativeLibraryDir = null;
info.secondaryNativeLibraryDir = null;
if (isApkFile(codeFile)) {
// Monolithic install
......
......
final String apkName = deriveCodePathName(codePath);
info.nativeLibraryRootDir = new File(mAppLib32InstallDir, apkName)
.getAbsolutePath();
}
info.nativeLibraryRootRequiresIsa = false;
info.nativeLibraryDir = info.nativeLibraryRootDir; static String deriveCodePathName(String codePath) {
if (codePath == null) {
return null;
}
final File codeFile = new File(codePath);
final String name = codeFile.getName();
if (codeFile.isDirectory()) {
return name;
} else if (name.endsWith(".apk") || name.endsWith(".tmp")) {
final int lastDot = name.lastIndexOf('.');
return name.substring(0, lastDot);
} else {
Slog.w(TAG, "Odd, " + codePath + " doesn't look like an APK");
return null;
}
}apkName 主要是来自于这个 codePath,codePath 一般都是app的安装地址,类似于:/data/app/com.test-1.apk 这样的文件格式,如果是以.apk 结尾的情况,这个 apkName 其实就是 com.test-1 这个名称。
pkg.codePath = packageDir.getAbsolutePath();
而 nativeLibraryRootDir 的值就是 app native 库的路径这个的初始化主要是在 PackageManagerService 的构造函数中
mAppLib32InstallDir = new File(dataDir, "app-lib");
综合上面的逻辑,连在一起就可以得到这个 libPath 的地址,比如对于 com.test 这个包的 app,最后的 nativeLibraryRootDir 其实就是 /data/app-lib/com.test-1 这个路径下,你其实可以从这个路径下找到你的 so 库。
3.2 primaryCpuAbi 哪里来的
首先解释下 Abi 的概念:
应用程序二进制接口(application binary interface,ABI) 描述了应用程序和操作系统之间,一个应用和它的库之间,或者应用的组成部分之间的低接口 。ABI 不同于 API ,API 定义了源代码和库之间的接口,因此同样的代码可以在支持这个 API 的任何系统中编译 ,然而 ABI 允许编译好的目标代码在使用兼容 ABI 的系统中无需改动就能运行。
而为什么有 primaryCpuAbi 的概念呢,因为一个系统支持的 abi 有很多,不止一个,比如一个64位的机器上他的 supportAbiList 可能如下所示
public static final String[] SUPPORTED_ABIS = getStringList("ro.product.cpu.abilist", ","); root@:/ # getprop ro.product.cpu.abilist
arm64-v8a,armeabi-v7a,armeabi所以他能支持的 abi 有如上的三个,这个 primaryCpuAbi 就是要知道当前程序的 abi 在他支持的 abi 中最靠前的那一个, 这个逻辑我们要放在 so copy 的逻辑一起讲,因为在 so copy 的时候会决定 primaryCpuAbi,同时依靠这个 primaryCpuAbi 的值来决定我们的程序是运行在32位还是64位下的。
3.3 总结,我们是在哪些路径下找的
这里总结一下,这个 libraryPath 主要来自两个方向:一个是 data 目录下 app-lib 中安装包目录,比如:/data/app-lib/com.test-1,另一个方向就是来自于 apkpath+"!/lib/"+primaryCpuAbi 的地址了,比如:/data/app/com.test-1.apk!/lib/arm64-v8a。
这下我们基本了解清楚了系统会从哪些目录下去找这个 so 的值了:一个是系统配置设置的值,这个主要针对的是系统 so 的路径,另外一个就是 /data/app-lib 下和 /data/app apk 的安装目录下对应的 abi 目录下去找。
另外不同的系统这些默认的 apkPath 和 codePath 可能会不一样,要想知道最精确的值,可以在你的 so 找不到的时候输出的日志中找到这个 so 的路径,比如6.0的机器上的路径又是这样的:
nativeLibraryDirectories=[/data/app/com.qq.qcloud-1/lib/arm, /data/app/com.qq.qcloud-1/base.apk!/lib/armeabi-v7a, /vendor/lib, /system/lib]]]
了解了我们去哪找,如果找不到的话那就只有2个情况了,一个是比如 abi 对应错了,另外就是是不是系统在安装的时候没有正常的将 so 拷贝这些路径下,导致了找不到的情况呢?所以我们还是需要了解在安装的时候这些 so 是如何拷贝到正常的路径下的,中间是不是会出一些问题呢?
4、apk 安装之---so 拷贝
关于 so 的拷贝我们还是照旧不细说 App 的安装流程了,主要还是和之前一样不论是替换还是新安装,都会调用 PackageManagerService 的 scanPackageLI() 函数,然后跑去 scanPackageDirtyLI 函数,而在这个函数中对于非系统的 APP 他调用了 derivePackageABI 这个函数,通过这个函数他将会觉得系统的abi是多少,并且也会进行我们最关心的 so 拷贝操作。
PackageManagerService.java
public void derivePackageAbi(PackageParser.Package pkg, File scanFile,
String cpuAbiOverride, boolean extractLibs)
throws PackageManagerException {
......
......
if (isMultiArch(pkg.applicationInfo)) {
// Warn if we've set an abiOverride for multi-lib packages..
// By definition, we need to copy both 32 and 64 bit libraries for
// such packages.
if (pkg.cpuAbiOverride != null
&& !NativeLibraryHelper.CLEAR_ABI_OVERRIDE.equals(pkg.cpuAbiOverride)) {
Slog.w(TAG, "Ignoring abiOverride for multi arch application.");
}
int abi32 = PackageManager.NO_NATIVE_LIBRARIES;
int abi64 = PackageManager.NO_NATIVE_LIBRARIES;
if (Build.SUPPORTED_32_BIT_ABIS.length > 0) {
if (extractLibs) {
abi32 = NativeLibraryHelper.copyNativeBinariesForSupportedAbi(handle,
nativeLibraryRoot, Build.SUPPORTED_32_BIT_ABIS,
useIsaSpecificSubdirs);
} else {
abi32 = NativeLibraryHelper.findSupportedAbi(handle, Build.SUPPORTED_32_BIT_ABIS);
}
}
maybeThrowExceptionForMultiArchCopy(
"Error unpackaging 32 bit native libs for multiarch app.", abi32);
if (Build.SUPPORTED_64_BIT_ABIS.length > 0) {
if (extractLibs) {
abi64 = NativeLibraryHelper.copyNativeBinariesForSupportedAbi(handle,
nativeLibraryRoot, Build.SUPPORTED_64_BIT_ABIS,
useIsaSpecificSubdirs);
} else {
abi64 = NativeLibraryHelper.findSupportedAbi(handle, Build.SUPPORTED_64_BIT_ABIS);
}
}
maybeThrowExceptionForMultiArchCopy(
"Error unpackaging 64 bit native libs for multiarch app.", abi64);
if (abi64 >= 0) {
pkg.applicationInfo.primaryCpuAbi = Build.SUPPORTED_64_BIT_ABIS[abi64];
}
if (abi32 >= 0) {
final String abi = Build.SUPPORTED_32_BIT_ABIS[abi32];
if (abi64 >= 0) {
pkg.applicationInfo.secondaryCpuAbi = abi;
} else {
pkg.applicationInfo.primaryCpuAbi = abi;
}
}
} else {
String[] abiList = (cpuAbiOverride != null) ?
new String[] { cpuAbiOverride } : Build.SUPPORTED_ABIS;
// Enable gross and lame hacks for apps that are built with old
// SDK tools. We must scan their APKs for renderscript bitcode and
// not launch them if it's present. Don't bother checking on devices
// that don't have 64 bit support.
boolean needsRenderScriptOverride = false;
if (Build.SUPPORTED_64_BIT_ABIS.length > 0 && cpuAbiOverride == null &&
NativeLibraryHelper.hasRenderscriptBitcode(handle)) {
abiList = Build.SUPPORTED_32_BIT_ABIS;
needsRenderScriptOverride = true;
}
final int copyRet;
if (extractLibs) {
copyRet = NativeLibraryHelper.copyNativeBinariesForSupportedAbi(handle,
nativeLibraryRoot, abiList, useIsaSpecificSubdirs);
} else {
copyRet = NativeLibraryHelper.findSupportedAbi(handle, abiList);
}
if (copyRet < 0 && copyRet != PackageManager.NO_NATIVE_LIBRARIES) {
throw new PackageManagerException(INSTALL_FAILED_INTERNAL_ERROR,
"Error unpackaging native libs for app, errorCode=" + copyRet);
}
if (copyRet >= 0) {
pkg.applicationInfo.primaryCpuAbi = abiList[copyRet];
} else if (copyRet == PackageManager.NO_NATIVE_LIBRARIES && cpuAbiOverride != null) {
pkg.applicationInfo.primaryCpuAbi = cpuAbiOverride;
} else if (needsRenderScriptOverride) {
pkg.applicationInfo.primaryCpuAbi = abiList[0];
}
}
} catch (IOException ioe) {
Slog.e(TAG, "Unable to get canonical file " + ioe.toString());
} finally {
IoUtils.closeQuietly(handle);
}
// Now that we've calculated the ABIs and determined if it's an internal app,
// we will go ahead and populate the nativeLibraryPath.
setNativeLibraryPaths(pkg);
}流程大致如下,这里的 nativeLibraryRoot 其实就是我们上文提到过的 mLibDir,这样就完成了我们的对应关系,我们要从 apk 中解压出 so,然后拷贝到 mLibDir 下,这样在 load 的时候才能去这里找的到这个文件,这个值我们举个简单的例子方便理解,比如 com.test 的 app,这个 nativeLibraryRoot 的值基本可以理解成:/data/app-lib/com.test-1。
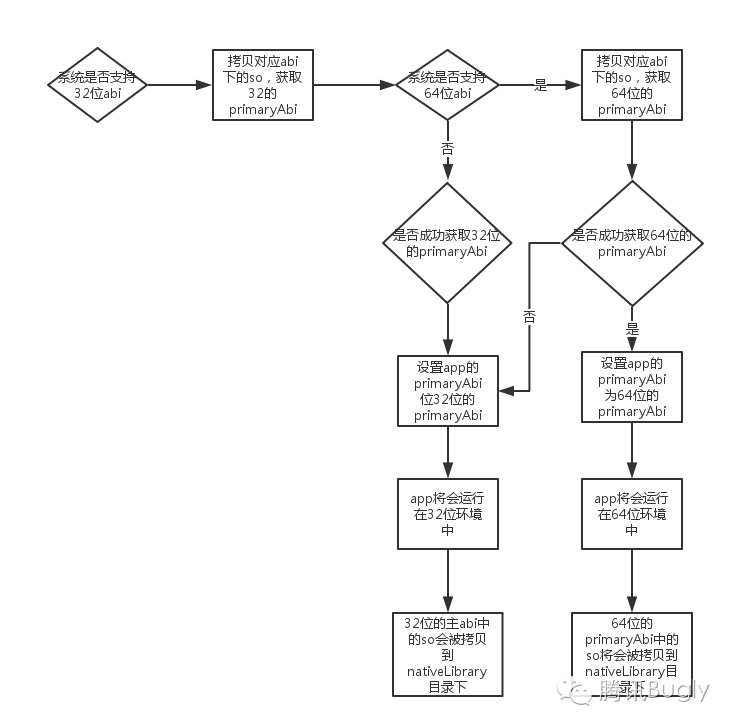
接下来的重点就是查看这个拷贝逻辑是如何实现的,代码在 NativeLibraryHelper 中 copyNativeBinariesForSupportedAbi 的实现
public static int copyNativeBinariesForSupportedAbi(Handle handle, File libraryRoot,
String[] abiList, boolean useIsaSubdir) throws IOException {
createNativeLibrarySubdir(libraryRoot);
/*
* If this is an internal application or our nativeLibraryPath points to
* the app-lib directory, unpack the libraries if necessary.
*/
int abi = findSupportedAbi(handle, abiList);
if (abi >= 0) {
/*
* If we have a matching instruction set, construct a subdir under the native
* library root that corresponds to this instruction set.
*/
final String instructionSet = VMRuntime.getInstructionSet(abiList[abi]);
final File subDir;
if (useIsaSubdir) {
final File isaSubdir = new File(libraryRoot, instructionSet);
createNativeLibrarySubdir(isaSubdir);
subDir = isaSubdir;
} else {
subDir = libraryRoot;
}
int copyRet = copyNativeBinaries(handle, subDir, abiList[abi]);
if (copyRet != PackageManager.INSTALL_SUCCEEDED) {
return copyRet;
}
}
return abi;
}函数 copyNativeBinariesForSupportedAbi,他的核心业务代码都在 native 层,它主要做了如下的工作
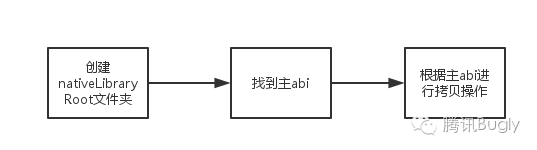
这个 nativeLibraryRootDir 上文在说到去哪找 so 的时候提到过了,其实是在这里创建的,然后我们重点看看 findSupportedAbi 和 copyNativeBinaries 的逻辑。
4.1 findSupportedAbi
findSupportedAbi 函数其实就是遍历 apk(其实就是一个压缩文件)中的所有文件,如果文件全路径中包含 abilist 中的某个 abi 字符串,则记录该 abi 字符串的索引,最终返回所有记录索引中最靠前的,即排在 abilist 中最前面的索引。
4.1.1 32位还是64位
这里的abi用来决定我们是32位还是64位,对于既有32位也有64位的情况,我们会采用64位,而对于仅有32位或者64位的话就认为他是对应的位数下,仅有32位就是32位,仅有64位就认为是64位的。
4.1.2 primaryCpuAbi 是多少
当前文确定好是用32位还是64位后,我们就会取出来对应的上文查找到的这个 abi 值,作为 primaryCpuAbi。
4.1.3 如果primaryCpuAbi 出错
这个 primaryCpuAbi 的值是安装的时候持久化在 pkg.applicationInfo 中的,所以一旦 abi 导致进程位数出错或者 primaryCpuAbi 出错,就可能会导致一直出错,重启也没有办法修复,需要我们用一些 hack 手段来进行修复。
NativeLibraryHelper 中的 findSupportedAbi 核心代码主要如下,基本就是我们前文说的主要逻辑,遍历 apk(其实就是一个压缩文件)中的所有文件,如果文件全路径中包含 abilist 中的某个 abi 字符串,则记录该 abi 字符串的索引,最终返回所有记录索引中最靠前的,即排在 abilist 中最前面的索引
NativeLibraryHelper.cpp
UniquePtr it(NativeLibrariesIterator::create(zipFile));
if (it.get() == NULL) {
return INSTALL_FAILED_INVALID_APK;
}
ZipEntryRO entry = NULL;
int status = NO_NATIVE_LIBRARIES;
while ((entry = it->next()) != NULL) {
// We're currently in the lib/ directory of the APK, so it does have some native
// code. We should return INSTALL_FAILED_NO_MATCHING_ABIS if none of the
// libraries match.
if (status == NO_NATIVE_LIBRARIES) {
status = INSTALL_FAILED_NO_MATCHING_ABIS;
}
const char* fileName = it->currentEntry();
const char* lastSlash = it->lastSlash();
// Check to see if this CPU ABI matches what we are looking for.
const char* abiOffset = fileName + APK_LIB_LEN;
const size_t abiSize = lastSlash - abiOffset;
for (int i = 0; i < numAbis; i++) {
const ScopedUtfChars* abi = supportedAbis[i];
if (abi->size() == abiSize && !strncmp(abiOffset, abi->c_str(), abiSize)) {
// The entry that comes in first (i.e. with a lower index) has the higher priority.
if (((i < status) && (status >= 0)) || (status < 0) ) {
status = i;
}
}
}
} 举个例子,加入我们的 app 中的 so 地址中有包含 arm64-v8a 的字符串,同时 abilist 是 arm64-v8a,armeabi-v7a,armeab,那么这里就会返回 arm64-v8a。这里其实需要特别注意,返回的是第一个,这里很可能会造成一些 so 位数不同,导致运行错误以及 so 找不到的情况。 具体我们还要结合 so 的 copy 来一起阐述。
4.2 copyNativeBinaries
主要的代码逻辑也是在 NativeLibraryHelper.cpp 中的 iterateOverNativeFiles 函数中,核心代码如下:
NativeLibraryHelper.cpp
if (cpuAbi.size() == cpuAbiRegionSize
&& *(cpuAbiOffset + cpuAbi.size()) == '/'
&& !strncmp(cpuAbiOffset, cpuAbi.c_str(), cpuAbiRegionSize)) {
ALOGV("Using primary ABI %s\n", cpuAbi.c_str());
hasPrimaryAbi = true;
} else if (cpuAbi2.size() == cpuAbiRegionSize
&& *(cpuAbiOffset + cpuAbi2.size()) == '/'
&& !strncmp(cpuAbiOffset, cpuAbi2.c_str(), cpuAbiRegionSize)) {
/*
* If this library matches both the primary and secondary ABIs,
* only use the primary ABI.
*/
if (hasPrimaryAbi) {
ALOGV("Already saw primary ABI, skipping secondary ABI %s\n", cpuAbi2.c_str());
continue;
} else {
ALOGV("Using secondary ABI %s\n", cpuAbi2.c_str());
}
} else {
ALOGV("abi didn't match anything: %s (end at %zd)\n", cpuAbiOffset, cpuAbiRegionSize);
continue;
}
// If this is a .so file, check to see if we need to copy it.
if ((!strncmp(fileName + fileNameLen - LIB_SUFFIX_LEN, LIB_SUFFIX, LIB_SUFFIX_LEN)
&& !strncmp(lastSlash, LIB_PREFIX, LIB_PREFIX_LEN)
&& isFilenameSafe(lastSlash + 1))
|| !strncmp(lastSlash + 1, GDBSERVER, GDBSERVER_LEN)) {
install_status_t ret = callFunc(env, callArg, &zipFile, entry, lastSlash + 1);
if (ret != INSTALL_SUCCEEDED) {
ALOGV("Failure for entry %s", lastSlash + 1);
return ret;
}
}
}主要的策略就是,遍历 apk 中文件,当遍历到有主 Abi 目录的 so 时,拷贝并设置标记 hasPrimaryAbi 为真,以后遍历则只拷贝主 Abi 目录下的 so。这个主 Abi 就是我们前面 findSupportedAbi 的时候找到的那个 abi 的值,大家可以去回顾下。
当标记为假的时候,如果遍历的 so 的 entry 名包含其他abi字符串,则拷贝该 so,拷贝 so 到我们上文说到 mLibDir 这个目录下。
这里有一个很重要的策略是:ZipFileRO 的遍历顺序,他是根据文件对应 ZipFileR0 中的 hash 值而定,而对于已经 hasPrimaryAbi 的情况下,非 PrimaryAbi 是直接跳过 copy 操作的,所以这里可能会出现很多拷贝 so 失败的情况。
举个例子:假设存在这样的 apk, lib 目录下存在 armeabi/libx.so , armeabi/liby.so , armeabi-v7a/libx.so 这三个 so 文件,且 hash 的顺序为 armeabi-v7a/libx.so 在 armeabi/liby.so 之前,则 apk 安装的时候 liby.so 根本不会被拷贝,因为按照拷贝策略, armeabi-v7a/libx.so 会优先遍历到,由于它是主 abi 目录的 so 文件,所以标记被设置了,当遍历到 armeabi/liby.so 时,由于标记被设置为真, liby.so 的拷贝就被忽略了,从而在加载 liby.so 的时候会报异常。
5、64位的影响
Android 在5.0以后其实已经支持64位了,而对于很多时候大家在运行so的时候也会遇到这样的错误:dlopen failed: "xx.so" is 32-bit instead of 64-bit,这种情况其实是因为进程由 64zygote 进程 fork 出来,在64位的进程上必须要64位的动态链接库。
Art 上支持64位程序的主要策略就是区分了 zygote32 和 zygote64,对于32位的程序通过 zygote32 去 fork 而64位的自然是通过 zygote64去 fork。相关代码主要在 ActivityManagerService 中:
ActivityManagerService.java
Process.ProcessStartResult startResult = Process.start(entryPoint,
app.processName, uid, uid, gids, debugFlags, mountExternal,
app.info.targetSdkVersion, app.info.seinfo, requiredAbi, instructionSet,
app.info.dataDir, entryPointArgs);Process.java
return zygoteSendArgsAndGetResult(openZygoteSocketIfNeeded(abi), argsForZygote);
从代码可以看出,startProcessLocked 方法实现启动应用,再通过 Process 中的 startViaZygote 方法,这个方法最终是向相应的 zygote 进程发出 fork 的请求 zygoteSendArgsAndGetResult(openZygoteSocketIfNeeded(abi), argsForZygote);
其中 openZygoteSocketIfNeeded(abi) 会根据 abi 的类型,选择不同的 zygote 的 socket 监听的端口,在之前的 init 文件中可以看到,而这个 abi 就是我们上文一直在提到的 primaryAbi。
所以当你的 app 中有64位的 abi,那么就必须所有的 so 文件都有64位的,不能出现一部分64位的一部分32位的,当你的 app 发现 primaryAbi 是64位的时候,他就会通过 zygote64 fork 在64位下,那么其他的32位 so 在 dlopen 的时候就会失败报错。
6、如何判断这个 so 是否加载过
我们前面说的都是 so 是怎么找的,哪里找的,以及他又是如何拷贝到这里来的,而我们前面的大图的流程有一个很明显的流程就是找到后判断已经加载过了,就不用再加载了。那么是系统是依据什么来判断这个so已经加载过了呢,我们要接着 System.java的doLoad 函数看起。
Runtime.java
private String doLoad(String name, ClassLoader loader) {
String ldLibraryPath = null;
if (loader != null && loader instanceof BaseDexClassLoader) {
ldLibraryPath = ((BaseDexClassLoader) loader).getLdLibraryPath();
}
// nativeLoad should be synchronized so there's only one LD_LIBRARY_PATH in use regardless
// of how many ClassLoaders are in the system, but dalvik doesn't support synchronized
// internal natives.
synchronized (this) {
return nativeLoad(name, loader, ldLibraryPath);
}
}主要代码在 nativeLoad 这里做的,这里再往下走是 native 方法了,于是我们要走到 java_lang_runtime.cc 中去看这个 nativeLoad 的实现
java_lang_runtime.cc
static jstring Runtime_nativeLoad(JNIEnv* env, jclass, jstring javaFilename, jobject javaLoader,
jstring javaLdLibraryPathJstr) {
ScopedUtfChars filename(env, javaFilename);
if (filename.c_str() == nullptr) {
return nullptr;
}
SetLdLibraryPath(env, javaLdLibraryPathJstr);
std::string error_msg;
{
JavaVMExt* vm = Runtime::Current()->GetJavaVM();
bool success = vm->LoadNativeLibrary(env, filename.c_str(), javaLoader, &error_msg);
if (success) {
return nullptr;
}
}
// Don't let a pending exception from JNI_OnLoad cause a CheckJNI issue with NewStringUTF.
env->ExceptionClear();
return env->NewStringUTF(error_msg.c_str());
}然后我们发现核心在 JavaVMExt 中的 LoadNativeLibrary 函数实现的,于是我们又去了解这个函数。
java_vm_ext.cc
bool JavaVMExt::LoadNativeLibrary(JNIEnv* env,
const std::string& path,
jobject class_loader,
jstring library_path,
std::string* error_msg) {
error_msg->clear();
// See if we've already loaded this library. If we have, and the class loader
// matches, return successfully without doing anything.
// TODO: for better results we should canonicalize the pathname (or even compare
// inodes). This implementation is fine if everybody is using System.loadLibrary.
SharedLibrary* library;
Thread* self = Thread::Current();
{
// TODO: move the locking (and more of this logic) into Libraries.
MutexLock mu(self, *Locks::jni_libraries_lock_);
library = libraries_->Get(path);
}
void* class_loader_allocator = nullptr;
{
ScopedObjectAccess soa(env);
// As the incoming class loader is reachable/alive during the call of this function,
// it's okay to decode it without worrying about unexpectedly marking it alive.
mirror::ClassLoader* loader = soa.Decode(class_loader);
ClassLinker* class_linker = Runtime::Current()->GetClassLinker();
if (class_linker->IsBootClassLoader(soa, loader)) {
loader = nullptr;
class_loader = nullptr;
}
class_loader_allocator = class_linker->GetAllocatorForClassLoader(loader);
CHECK(class_loader_allocator != nullptr);
} 其实查找规则和他的注释说的基本一样,发现 so 的 path 一样,并且关联的 ClassLoader 也是一致的那么就认为这个 so 是已经加载过的什么都不做,而这个 path 就是之前我们 findLibrary 中找到 so 的绝对路径。
所以如果要动态替换 so 的话,在已经加载过 so 的情况下,有2个方式可以再不重启的情况下就能做到 hotfix,要么换 so 的 path,要么就是改变 ClassLoader 对象,这个结论对我们后文的解决方案很有帮助。
7、解决方案
那么你说了这么多,应该怎么解决呢?
其实看了这么多代码,熟悉 hotpatch 的同学应该要说了,哎呀这个和 java 层的 patch 逻辑好像啊,只不过 java 层的 patch 是插入 dex 数组,咱们这个是插入到 nativeLibraryDirectory 数组中,通过这样类似的方式就能动态 patch 修复这个问题了。
其实本质的原理和 java 层的 patch 是类似的,但是还有几个点是需要注意的:
如果是 abi 导致拷贝不全的问题不一定需要 patch,可以自己解析一遍安装的 apk 做一次完整拷贝,来插入到 nativeLibraryDirectory 的末尾,以此来保证 so 都能找到。
在拷贝 so 的时候要保证优先拷贝 primaryCpuAbi 的 so
解决拷贝时机问题,在某些机型上如果程序一起来就挂,你连拷贝的时机都没有了
可以通过 patch 包来动态决定 primaryCpuAbi 的问题,解决一些 app 和 so 位数不一致的问题。patch 包解压后的地址需要插入到 nativeLibraryDirectory 的数组首位,从而使得程序的位数和 so 的位数兼容。
组件刚刚开发完成,还在验证阶段,回头再放出来,帮助大家解决动态库加载遇到的各种问题,以后妈妈再也不用担心了 UnsatisfiedLinkError 的错误了。
大家可以关注知乎账号“陈昱全”,与我进行交流。
更多精彩内容欢迎关注bugly的微信公众账号:

腾讯 Bugly是一款专为移动开发者打造的质量监控工具,帮助开发者快速,便捷的定位线上应用崩溃的情况以及解决方案。智能合并功能帮助开发同学把每天上报的数千条 Crash 根据根因合并分类,每日日报会列出影响用户数最多的崩溃,精准定位功能帮助开发同学定位到出问题的代码行,实时上报可以在发布后快速的了解应用的质量情况,适配最新的 iOS, Android 官方操作系统,鹅厂的工程师都在使用,快来加入我们吧!