Scala的空值删除和空值填充
重点:删除空值值所在行不考虑选择列的数据类型,而填充时一定要看好对应填充列的数据类型。
删除
import spark.implicits._
var datafff = Seq(
("0", "ming", "tj","2019-09-06 17:15:15", "2002", "192.196", "win7", "bai"),
("0", null, "ln","2019-09-08 05:15:15", "7007", "192.195", "ios", "wang"),
("0", "tian", "ln","2019-09-08 05:15:15", "7007", "192.195", "ios", "wang"),
("1", null, "hlj","2019-09-08 19:15:15", "9009", "192.196", "mac", "bai"),
("1", "tian", null,"2019-09-08 19:15:15", "9009", "192.196", "mac", "bai"),
(null, "tian","nmg","2019-09-08 19:15:15", "9009", "192.196", "mac", "bai"),
("0", "sunl", "tj","2019-09-08 15:15:15", "10010", "192.192", "ios", "wei")
).toDF("label", "name", "live","START_TIME", "AMOUNT", "CLIENT_IP", "CLIENT_MAC", "PAYER_CODE")
datafff.show()
datafff: org.apache.spark.sql.DataFrame = [label: string, name: string ... 6 more fields]
+-----+----+----+-------------------+------+---------+----------+----------+
|label|name|live| START_TIME|AMOUNT|CLIENT_IP|CLIENT_MAC|PAYER_CODE|
+-----+----+----+-------------------+------+---------+----------+----------+
| 0|ming| tj|2019-09-06 17:15:15| 2002| 192.196| win7| bai|
| 0|null| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| 0|tian| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| 1|null| hlj|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 1|tian|null|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| null|tian| nmg|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 0|sunl| tj|2019-09-08 15:15:15| 10010| 192.192| ios| wei|
+-----+----+----+-------------------+------+---------+----------+----------+
删除表格指定列的值为空值(null)所在的行
datafff.na.drop(cs_list)
var cs = "name,live"
var cs_list = cs.split(",")
datafff.na.drop(cs_list).show()
+-----+----+----+-------------------+------+---------+----------+----------+
|label|name|live| START_TIME|AMOUNT|CLIENT_IP|CLIENT_MAC|PAYER_CODE|
+-----+----+----+-------------------+------+---------+----------+----------+
| 0|ming| tj|2019-09-06 17:15:15| 2002| 192.196| win7| bai|
| 0|tian| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| null|tian| nmg|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 0|sunl| tj|2019-09-08 15:15:15| 10010| 192.192| ios| wei|
+-----+----+----+-------------------+------+---------+----------+----------+
删除表格指所有列的值为空值(null)所在的行
datafff.na.drop()
var cs = "name,live"
var cs_list = cs.split(",")
datafff.na.drop().show()
+-----+----+----+-------------------+------+---------+----------+----------+
|label|name|live| START_TIME|AMOUNT|CLIENT_IP|CLIENT_MAC|PAYER_CODE|
+-----+----+----+-------------------+------+---------+----------+----------+
| 0|ming| tj|2019-09-06 17:15:15| 2002| 192.196| win7| bai|
| 0|tian| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| 0|sunl| tj|2019-09-08 15:15:15| 10010| 192.192| ios| wei|
+-----+----+----+-------------------+------+---------+----------+----------+
填充
部分填充
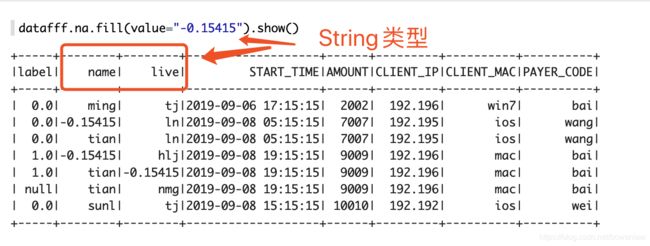
方法一:直接填充
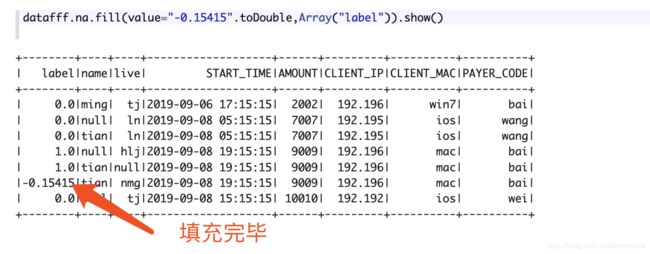
var new_data = datafff.na.fill(value="-0.15415".toDouble,Array("label"))
new_data.show()
方法二:利用map进行填充
var new_data = datafff.na.fill(map)
import java.util
var map = new util.HashMap[String, Any]()
map.put("label",5)
map.put("name","xiaoqiangqiangqiang")
println(map)
结果:
{name=xiaoqiangqiangqiang, label=5}
var new_data = datafff.na.fill(map)
new_data.show()
+-----+-------------------+----+-------------------+------+---------+----------+----------+
|label| name|live| START_TIME|AMOUNT|CLIENT_IP|CLIENT_MAC|PAYER_CODE|
+-----+-------------------+----+-------------------+------+---------+----------+----------+
| 0| ming| tj|2019-09-06 17:15:15| 2002| 192.196| win7| bai|
| 0|xiaoqiangqiangqiang| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| 0| tian| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| 1|xiaoqiangqiangqiang| hlj|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 1| tian|null|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 5| tian| nmg|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 0| sunl| tj|2019-09-08 15:15:15| 10010| 192.192| ios| wei|
+-----+-------------------+----+-------------------+------+---------+----------+----------+
填充时一定注意填充列的类型,填充对应类型的数据,如果不知道列的数据类型可以利用:
- 查看df的列类型:
dtypes.toMap
val dtypes = datafff.dtypes.toMap
println(dtypes)
Map(name -> StringType, CLIENT_MAC -> StringType, label -> StringType, START_TIME -> StringType, AMOUNT -> StringType, CLIENT_IP -> StringType, live -> StringType, PAYER_CODE -> StringType)
- 更改列类型:更详细请点击
转换类型一定要引入:
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
datafff = datafff.withColumn("label", datafff.col("label").cast(DoubleType))
datafff.show()
+-----+----+----+-------------------+------+---------+----------+----------+
|label|name|live| START_TIME|AMOUNT|CLIENT_IP|CLIENT_MAC|PAYER_CODE|
+-----+----+----+-------------------+------+---------+----------+----------+
| 0.0|ming| tj|2019-09-06 17:15:15| 2002| 192.196| win7| bai|
| 0.0|null| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| 0.0|tian| ln|2019-09-08 05:15:15| 7007| 192.195| ios| wang|
| 1.0|null| hlj|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 1.0|tian|null|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| null|tian| nmg|2019-09-08 19:15:15| 9009| 192.196| mac| bai|
| 0.0|sunl| tj|2019-09-08 15:15:15| 10010| 192.192| ios| wei|
+-----+----+----+-------------------+------+---------+----------+----------+
再次打印数据类型:
val dtypes = datafff.dtypes.toMap
println(dtypes)
Map(name -> StringType, CLIENT_MAC -> StringType, label -> DoubleType, START_TIME -> StringType, AMOUNT -> StringType, CLIENT_IP -> StringType, live -> StringType, PAYER_CODE -> StringType)
发现label已经变成了DoubleType 类型
此时填充label列不能使用string类型而是使用double类型:
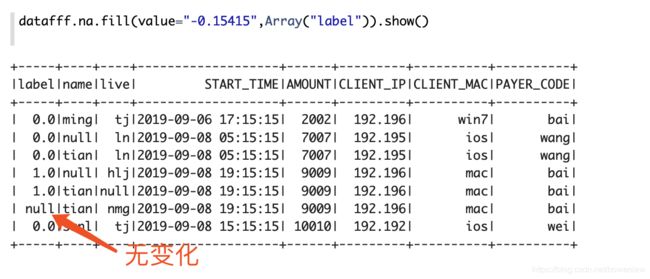
全部填充
只能填充和填充值类型相同的列!!!*