在 Objective-C 2.0 中,我们无需手动进行内存管理,因为ARC会自动帮我们在编译的时候,在合适的地方对对象进行retain和release操作。
本文将结合runtime 750版本源码 探究 ARC 环境下引用计数的实现原理。
如何存储引用计数
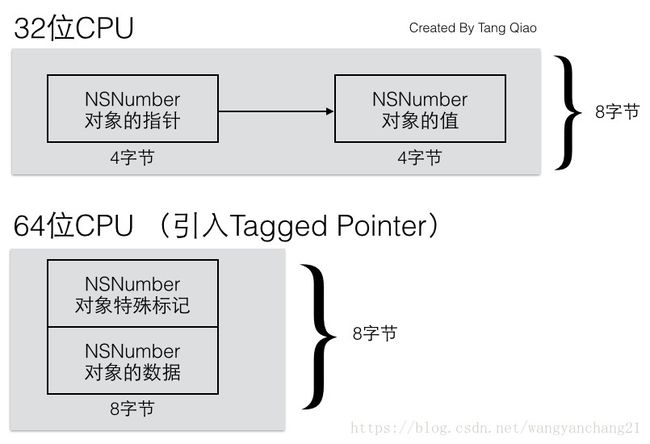
从 5S 开始,iPhone 都采用了64位架构的处理器,为了节省内存和提高执行效率,苹果提出了Tagged Pointer的概念,专门用来存储小的对象,例如 NSNumber 和 NSDate。这一类变量本身的值需要占用的内存大小常常不需要8字节,拿整数来说,4个字节所能表示的有符号整数可以达到20多亿(2^31=2147483648,另外 1 位作为符号位),基本可以处理大多数情况。所以我们将一个对象的指针(64位下8字节)拆成两部分,一部分用来存储数据,另一部分作为特殊标记,表示这是一个 Tagged Pointer, 不指向任何一个地址。也就是当某些类使用 Tagged Pointer 来存储数据后,它就不是一个对象了,因为它并没有指向任何地址,变成了一个披着对象皮的普通变量而已,而对于这一类的‘对象’,它的内存是分配在栈中,由系统分配以及释放,所以它的引用计数也没有意义了,当然你仍然可以使用CFGetRetainCount方法去获取它的引用计数,返回的是它的指针地址。
而在某些平台中(比如arm64),isa 实例的一部分空间也会被用来存储引用计数,当引用计数超过一定值之后,runtime 会使用一张散列表(哈希表)来管理其引用计数;如果不使用 isa 存储引用计数则会直接存储到散列表中。
isa 指针
用64位(8字节)来存储一个内存地址显然是种浪费,于是可以将一部分的空间用来存储引用计数。当 isa 指针第一位为1时即表示使用优化的 isa 指针,这里列出64位环境下的 isa 结构:
union isa_t
{
isa_t() { }
isa_t(uintptr_t value) : bits(value) { }
Class cls;
uintptr_t bits;
#if SUPPORT_NONPOINTER_ISA
# if __arm64__
# define ISA_MASK 0x00000001fffffff8ULL
# define ISA_MAGIC_MASK 0x000003fe00000001ULL
# define ISA_MAGIC_VALUE 0x000001a400000001ULL
struct {
uintptr_t indexed : 1;
uintptr_t has_assoc : 1;
uintptr_t has_cxx_dtor : 1;
uintptr_t shiftcls : 30; // MACH_VM_MAX_ADDRESS 0x1a0000000
uintptr_t magic : 9;
uintptr_t weakly_referenced : 1;
uintptr_t deallocating : 1;
uintptr_t has_sidetable_rc : 1;
uintptr_t extra_rc : 19;
# define RC_ONE (1ULL<<45)
# define RC_HALF (1ULL<<18)
};
// SUPPORT_NONPOINTER_ISA
#endif
};
SUPPORT_NONPOINTER_ISA表示是否支持在 isa 指针内添加额外的信息,例如引用计数,析构状态,被__weak变量引用的情况等。目前仅支持 arm64架构的设备支持。
| 变量名 | 含义 |
|---|---|
| indexed | 0 表示普通的 isa 指针,1 表示可以存储引用计数 |
| has_assoc | 表示该对象是否包含 associated object(关联对象) |
| has_cxx_dtor | 表示该对象是否有 C++ 的析构函数 |
| shiftcls | 类的指针 |
| magic | 固定值为 0xd2,用于在调试时分辨对象是否未完成初始化 |
| weakly_referenced | 表示该对象是否有过 weak 对象,如果没有,则析构时更快 |
| deallocating | 表示该对象是否正在析构 |
| has_sidetable_rc | 表示该对象的引用计数值是否过大无法存储在 isa 指针 |
| extra_rc | 存储引用计数值减一后的结果 |
在64位环境下,isa 会存储引用计数,当 has_sidetable_rc 的值为1时,那么溢出的引用计数将会存储在一张全局散列表中,也就是引用计数 = isa保存的引用计数 + 哈希表保存的引用计数 + 1。后面会详细讲到。
哈希表 DenseMap
typedef objc::DenseMap,size_t,true> RefcountMap;
template >
class DenseMap
: public DenseMapBase,
KeyT, ValueT, KeyInfoT, ZeroValuesArePurgeable>
{
// ...省略
}
runtime 使用 DenseMap 哈希表(也叫散列表,类似NSDictionary)的别名RefcountMap来存储引用计数。DenseMap 继承于 DenseMapBase 这个 C++ 类,通过观察 DenseMapBase 的内部实现我们可以发现以下几点:
- 键 KeyT 的类型为
DisguisedPtr,这个类是对objc_object *指针及其一些操作进行的封装,目的是不受内存泄漏工具leaks的检测 - 值 ValueT 的类型为 size_t, size_t在64位环境下等同于 unsigned long。保存的值等于
引用计数减一 - 模板的 KeyInfoT 类型为 DenseMapInfo
,在这里等同于DenseMapInfo 重要的方法,用于在哈希表中查找 key 映射的内容
template
struct DenseMapInfo {
static inline T* getEmptyKey() {
uintptr_t Val = static_cast(-1);
return reinterpret_cast(Val);
}
static inline T* getTombstoneKey() {
uintptr_t Val = static_cast(-2);
return reinterpret_cast(Val);
}
static unsigned getHashValue(const T *PtrVal) {
return ptr_hash((uintptr_t)PtrVal);
}
static bool isEqual(const T *LHS, const T *RHS) { return LHS == RHS; }
};
指针哈希算法实现:
#if __LP64__
static inline uint32_t ptr_hash(uint64_t key)
{
key ^= key >> 4;
key *= 0x8a970be7488fda55;
key ^= __builtin_bswap64(key);
return (uint32_t)key;
}
#endif
虽然不完美,但是速度很快(注释说的。。。)
简单来讲,DenseMap 通过对象的指针地址来映射其引用计数
SideTable
struct SideTable {
spinlock_t slock;
RefcountMap refcnts;
weak_table_t weak_table;
// ...省略
}
介绍完存储引用计数的哈希表,那么这个哈希表是存储在哪里的呢?
答案是保存在一个叫做SideTable的结构体中,通过观察它的结构组成,我们可以可以看到有三个成员变量slock, refcnts和weak_table。
-
slock是一个自旋锁,保证线程安全 -
refcnts的类型是 RefcountMap,也就是上一节提到过的 DenseMap 类型的别名。用来保存引用计数 -
weak_table用来保存__weak修饰的指针。当一个对象 delloc 时,通过这个表将这些指向要释放对象的用__weak修饰的指针置为nil,避免野指针的情况出现。
StripedMap
知道引用计数的哈希表是保存在SideTable中,那么SideTable实例保存在哪里呢?
答案是在一个全局的StripedMap类型的静态变量SideTableBuf中
alignas(StripedMap) static uint8_t
SideTableBuf[sizeof(StripedMap)];
static void SideTableInit() {
new (SideTableBuf) StripedMap();
}
static StripedMap& SideTables() {
return *reinterpret_cast*>(SideTableBuf);
}
之所以在初始化时将 SideTableBuf 定义成 uint8_t 是因为方便计算内存大小,在SideTables()方法中我们可以看到SideTableBuf会被强制转换成StripedMap类型。实际上 SideTableBuf 也是哈希表,根据指针地址映射到相应的SideTable类型的变量。下面是StripedMap这个类的定义:
template
class StripedMap {
#if TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR
enum { StripeCount = 8 };
#else
enum { StripeCount = 64 };
#endif
struct PaddedT {
T value alignas(CacheLineSize);
};
PaddedT array[StripeCount];
static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}
public:
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
// ...省略
}
StripedMap中有一个PaddedT类型的数组array,在模拟器中容量为64,在真机中为8。PaddedT结构体大小为64个字节,其成员变量 value 的类型实际是我们之前传入 SideTable。当系统调用SideTable& table = SideTables()[]时首先会执行SideTables()得到SideTableBuf, 然后在StripedMap中执行T& operator[] (const void *p)方法获取相应的SideTable。
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}
在indexForPointer()函数中返回相应 SideTable 的index。(addr >> 4) ^ (addr >> 9)这一步我也不是很懂,应该是类似于产生一个随机数,后面的% StripeCount返回一个 [0, StripeCount)的数,也就是相应 SideTable 的index。所以一个 SideTable 应该是对应许多的对象的。
保存引用计数的哈希表保存在
SideTable结构体中,而SideTable保存在一个全局的静态变量StripedMap中。在真机下,SideTableBuf能够储存8个SideTableBuf SideTable实例。StripedMap的方法indexForPointer()通过对象的指针计算出相应 SideTable 的 index。一个 SideTable 对应多个对象
获取引用计数
在 ARC 环境下我们可以使用方法CFGetRetainCount得到对象的引用计数。在 runtime 中,通过调用objc_object的rootRetainCount()获取引用计数:
inline uintptr_t
objc_object::rootRetainCount()
{
if (isTaggedPointer()) return (uintptr_t)this;
sidetable_lock();
isa_t bits = LoadExclusive(&isa.bits);
ClearExclusive(&isa.bits);
if (bits.nonpointer) {
uintptr_t rc = 1 + bits.extra_rc;
if (bits.has_sidetable_rc) {
rc += sidetable_getExtraRC_nolock();
}
sidetable_unlock();
return rc;
}
sidetable_unlock();
return sidetable_retainCount();
}
-
isTaggedPointer在前面我们已经分析过了如果是Tagged Pointer类型的对象时是怎么样的。此时对象在栈中分配,由系统自动销毁内存(先进后出),所以此时对它求引用计数返回其地址。
下面让我们重点看一下sidetable_retainCount()这个方法 - 当 isa 的 nonpointer = 1 的情况我们开头也分析过了,此时 isa 指针也用来存储引用计数,如果引用计数溢出则将溢出部分存储在哈希表中
- 下面让我们研究一下不使用isa优化是怎么从哈希表中获取引用计数的
uintptr_t
objc_object::sidetable_retainCount()
{
SideTable& table = SideTables()[this];
size_t refcnt_result = 1;
table.lock();
RefcountMap::iterator it = table.refcnts.find(this);
if (it != table.refcnts.end()) {
// this is valid for SIDE_TABLE_RC_PINNED too
refcnt_result += it->second >> SIDE_TABLE_RC_SHIFT;
}
table.unlock();
return refcnt_result;
}
- 首先得到 SideTable 实例。
- 成员变量 refcnts 就是之前说的保存引用计数的哈希表,在哈希表中根据指针值查找引用计数。
-
it->second >> SIDE_TABLE_RC_SHIFT注意result从第三位才开始保存数据,所以需要将数据向右移动2位才能取到引用计数。第1位用来保存该对象是否被用__weak修饰的变量引用,第2位用来表示该对象是否正在析构 - 将右移后得到的数+1(refcnt_result)后返回。这也是为什么之前说哈希表保存的引用计数是实际值 -1 之后的值的原因。
Retain
在非 ARC 环境中可以使用retain和release方法对引用计数进行加减操作,在 ARC 环境中我们无需也无法使用这两个方法操作引用计数,但是你可以使用CFRetain()对对象进行 retain 操作。最终会调用 objc_object的rootRetain方法
inline id
objc_object::rootRetain()
{
assert(!UseGC);
if (isTaggedPointer()) return (id)this;
return sidetable_retain();
}
类似于上一节中获取引用计数的方法,当对象属于Tagged Pointer时则返回该对象。所以我们接着看sidetable_retain()方法:
id objc_object::sidetable_retain()
{
#if SUPPORT_NONPOINTER_ISA
assert(!isa.nonpointer);
#endif
SideTable& table = SideTables()[this];
table.lock();
size_t& refcntStorage = table.refcnts[this];
if (! (refcntStorage & SIDE_TABLE_RC_PINNED)) {
refcntStorage += SIDE_TABLE_RC_ONE;
}
table.unlock();
return (id)this;
}
首先得到 SideTable 实例。从实例中得到存储引用技术的哈希表refcnts,在哈希表中根据对象的地址找到对应的引用计数refcntStorage,判断引用计数的值是否有溢出,如果没有则对引用计数 + 1,返回对象。
上一节我们讲过 refcntStorage 中第三位才开始用来存储引用计数,所以读数时需要先往右边移动两位,那为什么这里的代码没有呢?
#define SIDE_TABLE_WEAKLY_REFERENCED (1UL<<0)
#define SIDE_TABLE_DEALLOCATING (1UL<<1) // MSB-ward of weak bit
#define SIDE_TABLE_RC_ONE (1UL<<2) // MSB-ward of deallocating bit
#define SIDE_TABLE_RC_PINNED (1UL<<(WORD_BITS-1))
#define SIDE_TABLE_RC_SHIFT 2
注意观察SIDE_TABLE_RC_ONE的定义,是一个8字节的 unsigned long 类型,值为1,向左偏移了两位。refcntStorage += SIDE_TABLE_RC_ONE两者相加的话则直接从第三位开始相加了,所以可以使用 SIDE_TABLE_RC_ONE 对引用计数进行 +1 和 -1 操作。
同样的,在上面的代码中, SIDE_TABLE_RC_PINNED用来判断引用计数值是否有溢出。
Release
release 最终会调用 objc_object的方法rootRelease()
inline bool
objc_object::rootRelease()
{
if (isTaggedPointer()) return false;
return sidetable_release(true);
}
uintptr_t objc_object::sidetable_release(bool performDealloc)
{
#if SUPPORT_NONPOINTER_ISA
assert(!isa.nonpointer);
#endif
SideTable& table = SideTables()[this];
bool do_dealloc = false;
table.lock();
RefcountMap::iterator it = table.refcnts.find(this);
if (it == table.refcnts.end()) {
do_dealloc = true;
table.refcnts[this] = SIDE_TABLE_DEALLOCATING;
} else if (it->second < SIDE_TABLE_DEALLOCATING) {
// SIDE_TABLE_WEAKLY_REFERENCED may be set. Don't change it.
do_dealloc = true;
it->second |= SIDE_TABLE_DEALLOCATING;
} else if (! (it->second & SIDE_TABLE_RC_PINNED)) {
it->second -= SIDE_TABLE_RC_ONE;
}
table.unlock();
if (do_dealloc && performDealloc) {
((void(*)(objc_object *, SEL))objc_msgSend)(this, SEL_dealloc);
}
return do_dealloc;
}
在这个方法你可以知道为什么哈希表中保存的引用计数是实际值 -1 之后的值。
it->second < SIDE_TABLE_DEALLOCATING用来判断保存的引用计数值是否小于1,如果小于1的话则对该值标记为正在析构:it->second |= SIDE_TABLE_DEALLOCATING;,并且在随后对该对象发送 delloc 消息。
举个例子,一个对象 sark,实际的引用计数为1,在哈希表中保存的值为0,当这个对象进行release操作后,sark 的引用计数变成了0,也就是需要进行销毁操作了。而到了该方法中,会判断保存的引用计数的值是否小于1,如果是的话则进行 delloc 操作,并且将哈希表中存储的值标记为正在析构状态。而 sark 原先保存着的引用计数值就是 =0,这样设计避免了在哈希表存储的引用计数出现负数的情况。
alloc,new, copy 和 mutableCopy
copy 以及 mutableCopy是NSCopying和NSMutableCopying协议上的方法,需要在各类上自己去实现copyWithZone:和mutableCopyWithZone:方法。无论是深拷贝还是浅拷贝都会增加引用计数。
+ (id)new {
return [callAlloc(self, false/*checkNil*/) init];
}
+ (id)alloc {
return _objc_rootAlloc(self);
}
[cls alloc]以及[cls allocWithZone:nil]方法最终会调用callAlloc()方法,所以 alloc 和 new 这两个方法后面都会调用callAlloc()这个方法,因为 Objective-C 2.0 忽视垃圾回收和 NSZone,那么后续的调用顺序依次是为:
callAlloc()
class_createInstance()
_class_createInstanceFromZone
calloc()
calloc()函数相比于malloc()函数的优点是它将分配的内存区域初始化为0,相当于malloc()后再用memset()方法初始化一遍。
单例
其实这一节是对上一节内容的补充。
记得我刚出来工作的时候,单例是这样写的:
@implementation Son
+ (instancetype)shareManager
{
static Son *son;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
son = [super allocWithZone:nil];
});
return son;
}
+ (instancetype)allocWithZone:(struct _NSZone *)zone
{
return [self shareManager];
}
@end
当时组长问我为什么要这样子写(因为跟他们写的方式不一样),我也答不上来,因为这种代码都是直接google的。但是看了callAlloc()实现之后我明白为什么了。
在上一节我们已经知道了 alloc 和 new 都会接着调用callAlloc()
static ALWAYS_INLINE id
callAlloc(Class cls, bool checkNil, bool allocWithZone=false)
{
if (slowpath(checkNil && !cls)) return nil;
#if __OBJC2__
if (fastpath(!cls->ISA()->hasCustomAWZ())) {
// No alloc/allocWithZone implementation. Go straight to the allocator.
// fixme store hasCustomAWZ in the non-meta class and
// add it to canAllocFast's summary
if (fastpath(cls->canAllocFast())) {
// No ctors, raw isa, etc. Go straight to the metal.
bool dtor = cls->hasCxxDtor();
id obj = (id)calloc(1, cls->bits.fastInstanceSize());
if (slowpath(!obj)) return callBadAllocHandler(cls);
obj->initInstanceIsa(cls, dtor);
return obj;
}
else {
// Has ctor or raw isa or something. Use the slower path.
id obj = class_createInstance(cls, 0);
if (slowpath(!obj)) return callBadAllocHandler(cls);
return obj;
}
}
#endif
// No shortcuts available.
if (allocWithZone) return [cls allocWithZone:nil];
return [cls alloc];
}
如果类重载了allocWithZone方法,那么cls->ISA()->hasCustomAWZ()将会返回YES,也就是说当我们用alloc或者new创建实例的时候,就不会走系统的方法,而会走重载的allocWithZone方法了。我们在重载allocWithZone方法时返回[self shareManager](注意此时的self代表Son类), 因为shareManager方法返回的是一个静态变量。
还有一个需要注意的点就是在shareManager中,我们使用son = [super allocWithZone:nil];初始化实例,为什么不使用son = [[super alloc] init];来初始化呢?
代码中的[super alloc];在编译后会变成objc_msgSendSuper(objc_super super, @selector(alloc))(大致意思是这样)。其中objc_super是一个结构体,只有两个成员变量id receiver和Class class,receiver 仍是 self(Son类), class 为 Father类。当我们想通过[super alloc]创建实例的时候,会从 Father类中查找 +alloc 方法,如果没有实现则在 NSObject 中查找 +alloc 方法。而方法里面的参数 self 仍旧为 Son 类而不是 Father 类,所以还是会去调用重载的allocWithZone方法,导致死循环。
引用
Objective-C 引用计数原理