前言
个人珍藏的80道Java多线程/并发经典面试题,现在给出11-20的答案解析哈,并且上传github哈~
https://github.com/whx123/JavaHome
个人珍藏的80道多线程并发面试题(1-10答案解析)
11、为什么要用线程池?Java的线程池内部机制,参数作用,几种工作阻塞队列,线程池类型以及使用场景
回答这些点:
- 为什么要用线程池?
- Java的线程池原理
- 线程池核心参数
- 几种工作阻塞队列
- 线程池使用不当的问题
- 线程池类型以及使用场景
为什么要用线程池?
线程池:一个管理线程的池子。
- 管理线程,避免增加创建线程和销毁线程的资源损耗。
- 提高响应速度。
- 重复利用。
Java的线程池执行原理
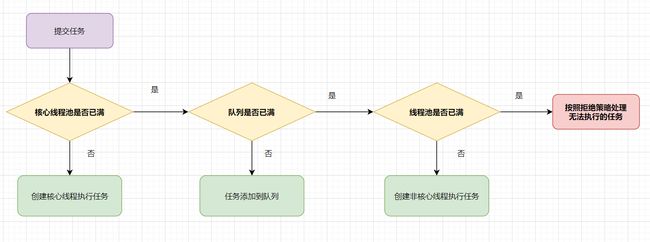
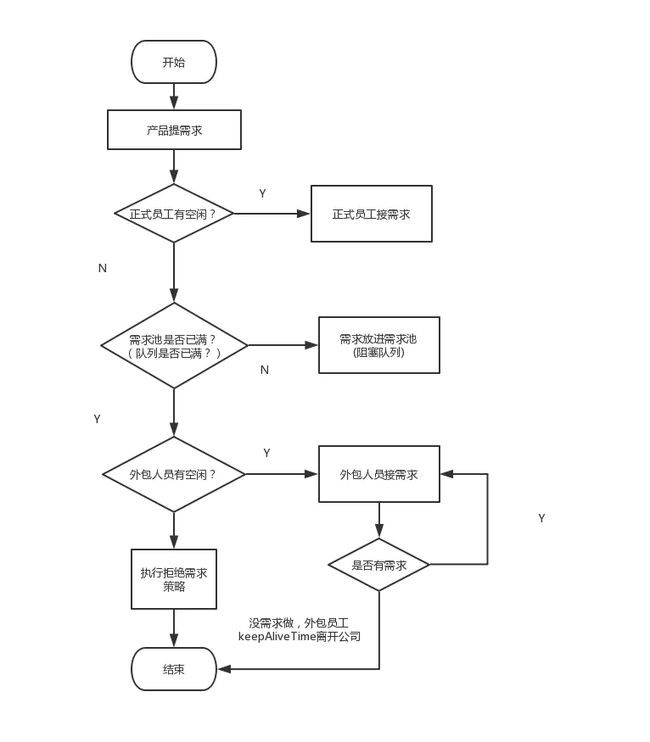
为了形象描述线程池执行,打个比喻:
- 核心线程比作公司正式员工
- 非核心线程比作外包员工
- 阻塞队列比作需求池
- 提交任务比作提需求
线程池核心参数
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize: 线程池核心线程数最大值
- maximumPoolSize: 线程池最大线程数大小
- keepAliveTime: 线程池中非核心线程空闲的存活时间大小
- unit: 线程空闲存活时间单位
- workQueue: 存放任务的阻塞队列
- threadFactory: 用于设置创建线程的工厂,可以给创建的线程设置有意义的名字,可方便排查问题。
- handler:线城池的饱和策略事件,主要有四种类型拒绝策略。
四种拒绝策略
- AbortPolicy(抛出一个异常,默认的)
- DiscardPolicy(直接丢弃任务)
- DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池)
- CallerRunsPolicy(交给线程池调用所在的线程进行处理)
几种工作阻塞队列
- ArrayBlockingQueue(用数组实现的有界阻塞队列,按FIFO排序量)
- LinkedBlockingQueue(基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列)
- DelayQueue(一个任务定时周期的延迟执行的队列)
- PriorityBlockingQueue(具有优先级的无界阻塞队列)
- SynchronousQueue(一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态)
线程池使用不当的问题
线程池适用不当可能导致内存飙升问题哦
有兴趣可以看我这篇文章哈:源码角度分析-newFixedThreadPool线程池导致的内存飙升问题
线程池类型以及使用场景
- newFixedThreadPool
适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
- newCachedThreadPool
用于并发执行大量短期的小任务。
- newSingleThreadExecutor
适用于串行执行任务的场景,一个任务一个任务地执行。
- newScheduledThreadPool
周期性执行任务的场景,需要限制线程数量的场景
- newWorkStealingPool
建一个含有足够多线程的线程池,来维持相应的并行级别,它会通过工作窃取的方式,使得多核的 CPU 不会闲置,总会有活着的线程让 CPU 去运行,本质上就是一个 ForkJoinPool。)
有兴趣可以看我这篇文章哈:面试必备:Java线程池解析
12、谈谈volatile关键字的理解
volatile是面试官非常喜欢问的一个问题,可以回答以下这几点:
- vlatile变量的作用
- 现代计算机的内存模型(嗅探技术,MESI协议,总线)
- Java内存模型(JMM)
- 什么是可见性?
- 指令重排序
- volatile的内存语义
- as-if-serial
- Happens-before
- volatile可以解决原子性嘛?为什么?
- volatile底层原理,如何保证可见性和禁止指令重排(内存屏障)
vlatile变量的作用?
- 保证变量对所有线程可见性
- 禁止指令重排
现代计算机的内存模型

- 其中高速缓存包括L1,L2,L3缓存~
- 缓存一致性协议,可以了解MESI协议
- 总线(Bus)是计算机各种功能部件之间传送信息的公共通信干线,CPU和其他功能部件是通过总线通信的。
- 处理器使用嗅探技术保证它的内部缓存、系统内存和其他处理器的缓存数据在总线上保持一致。
Java内存模型(JMM)
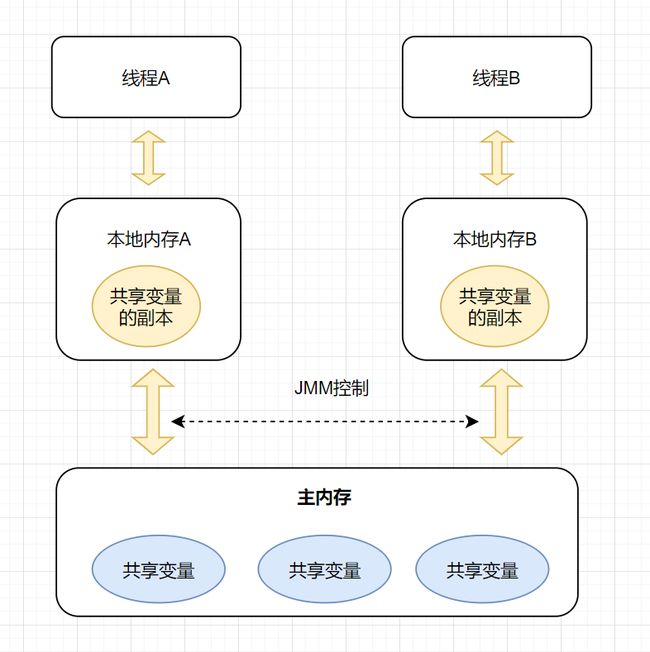
什么是可见性?
可见性就是当一个线程 修改一个共享变量时,另外一个线程能读到这个修改的值。
指令重排序
指令重排是指在程序执行过程中,为了提高性能, 编译器和CPU可能会对指令进行重新排序。

volatile的内存语义
- 当写一个 volatile 变量时,JMM 会把该线程对应的本地内存中的共享变量值刷新到主内存。
- 当读一个 volatile 变量时,JMM 会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
as-if-serial
如果在本线程内观察,所有的操作都是有序的;即不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不会被改变。
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
步骤C依赖于步骤A和B,因为指令重排的存在,程序执行顺讯可能是A->B->C,也可能是B->A->C,但是C不能在A或者B前面执行,这将违反as-if-serial语义。

Happens-before
Java语言中,有一个先行发生原则(happens-before):
- 程序次序规则:在一个线程内,按照控制流顺序,书写在前面的操作先行发生于书写在后面的操作。
- 管程锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
- 线程终止规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
- 传递性:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
volatile可以解决原子性嘛?为什么?
不可以,可以直接举i++那个例子,原子性需要synchronzied或者lock保证
public class Test {
public volatile int race = 0;
public void increase() {
race++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<100;j++)
test.increase();
};
}.start();
}
//等待所有累加线程结束
while(Thread.activeCount()>1)
Thread.yield();
System.out.println(test.race);
}
}
volatile底层原理,如何保证可见性和禁止指令重排(内存屏障)
volatile 修饰的变量,转成汇编代码,会发现多出一个lock前缀指令。lock指令相当于一个内存屏障,它保证以下这几点:
- 1.重排序时不能把后面的指令重排序到内存屏障之前的位置
- 2.将本处理器的缓存写入内存
- 3.如果是写入动作,会导致其他处理器中对应的缓存无效。
2、3点保证可见性,第1点禁止指令重排~
有兴趣的朋友可以看我这篇文章哈:Java程序员面试必备:Volatile全方位解析
13、AQS组件,实现原理
AQS,即AbstractQueuedSynchronizer,是构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。可以回答以下这几个关键点哈:
- state 状态的维护。
- CLH队列
- ConditionObject通知
- 模板方法设计模式
- 独占与共享模式。
- 自定义同步器。
- AQS全家桶的一些延伸,如:ReentrantLock等。
state 状态的维护
- state,int变量,锁的状态,用volatile修饰,保证多线程中的可见性。
- getState()和setState()方法采用final修饰,限制AQS的子类重写它们两。
- compareAndSetState()方法采用乐观锁思想的CAS算法操作确保线程安全,保证状态
设置的原子性。
对CAS有兴趣的朋友,可以看下我这篇文章哈~
CAS乐观锁解决并发问题的一次实践
CLH队列

CLH(Craig, Landin, and Hagersten locks) 同步队列 是一个FIFO双向队列,其内部通过节点head和tail记录队首和队尾元素,队列元素的类型为Node。AQS依赖它来完成同步状态state的管理,当前线程如果获取同步状态失败时,AQS则会将当前线程已经等待状态等信息构造成一个节点(Node)并将其加入到CLH同步队列,同时会阻塞当前线程,当同步状态释放时,会把首节点唤醒(公平锁),使其再次尝试获取同步状态。
ConditionObject通知
我们都知道,synchronized控制同步的时候,可以配合Object的wait()、notify(),notifyAll() 系列方法可以实现等待/通知模式。而Lock呢?它提供了条件Condition接口,配合await(),signal(),signalAll() 等方法也可以实现等待/通知机制。ConditionObject实现了Condition接口,给AQS提供条件变量的支持 。

ConditionObject队列与CLH队列的爱恨情仇:
- 调用了await()方法的线程,会被加入到conditionObject等待队列中,并且唤醒CLH队列中head节点的下一个节点。
- 线程在某个ConditionObject对象上调用了singnal()方法后,等待队列中的firstWaiter会被加入到AQS的CLH队列中,等待被唤醒。
- 当线程调用unLock()方法释放锁时,CLH队列中的head节点的下一个节点(在本例中是firtWaiter),会被唤醒。
模板方法设计模式
什么是模板设计模式?
在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤。
AQS的典型设计模式就是模板方法设计模式啦。AQS全家桶(ReentrantLock,Semaphore)的衍生实现,就体现出这个设计模式。如AQS提供tryAcquire,tryAcquireShared等模板方法,给子类实现自定义的同步器。
独占与共享模式
- 独占式: 同一时刻仅有一个线程持有同步状态,如ReentrantLock。又可分为公平锁和非公平锁。
- 共享模式:多个线程可同时执行,如Semaphore/CountDownLatch等都是共享式的产物。
自定义同步器
你要实现自定义锁的话,首先需要确定你要实现的是独占锁还是共享锁,定义原子变量state的含义,再定义一个内部类去继承AQS,重写对应的模板方法即可啦
AQS全家桶的一些延伸。
Semaphore,CountDownLatch,ReentrantLock
可以看下之前我这篇文章哈,AQS解析与实战
14、什么是多线程环境下的伪共享
- 什么是伪共享
- 如何解决伪共享问题
什么是伪共享
伪共享定义?
CPU的缓存是以缓存行(cache line)为单位进行缓存的,当多个线程修改相互独立的变量,而这些变量又处于同一个缓存行时就会影响彼此的性能。这就是伪共享
现代计算机计算模型,大家都有印象吧?我之前这篇文章也有讲过,有兴趣可以看一下哈,Java程序员面试必备:Volatile全方位解析

- CPU执行速度比内存速度快好几个数量级,为了提高执行效率,现代计算机模型演变出CPU、缓存(L1,L2,L3),内存的模型。
- CPU执行运算时,如先从L1缓存查询数据,找不到再去L2缓存找,依次类推,直到在内存获取到数据。
- 为了避免频繁从内存获取数据,聪明的科学家设计出缓存行,缓存行大小为64字节。
也正是因为缓存行,就导致伪共享问题的存在,如图所示:

假设数据a、b被加载到同一个缓存行。
- 当线程1修改了a的值,这时候CPU1就会通知其他CPU核,当前缓存行(Cache line)已经失效。
- 这时候,如果线程2发起修改b,因为缓存行已经失效了,所以core2 这时会重新从主内存中读取该 Cache line 数据。读完后,因为它要修改b的值,那么CPU2就通知其他CPU核,当前缓存行(Cache line)又已经失效。
- 酱紫,如果同一个Cache line的内容被多个线程读写,就很容易产生相互竞争,频繁回写主内存,会大大降低性能。
如何解决伪共享问题
既然伪共享是因为相互独立的变量存储到相同的Cache line导致的,一个缓存行大小是64字节。那么,我们就可以使用空间换时间,即数据填充的方式,把独立的变量分散到不同的Cache line~
共享内存demo例子:
public class FalseShareTest {
public static void main(String[] args) throws InterruptedException {
Rectangle rectangle = new Rectangle();
long beginTime = System.currentTimeMillis();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
rectangle.a = rectangle.a + 1;
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
rectangle.b = rectangle.b + 1;
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("执行时间" + (System.currentTimeMillis() - beginTime));
}
}
class Rectangle {
volatile long a;
volatile long b;
}
运行结果:
执行时间2815
一个long类型是8字节,我们在变量a和b之间不上7个long类型变量呢,输出结果是啥呢?如下:
class Rectangle {
volatile long a;
long a1,a2,a3,a4,a5,a6,a7;
volatile long b;
}
运行结果:
执行时间1113
可以发现利用填充数据的方式,让读写的变量分割到不同缓存行,可以很好挺高性能~
15、 说一下 Runnable和 Callable有什么区别?
- Callable接口方法是call(),Runnable的方法是run();
- Callable接口call方法有返回值,支持泛型,Runnable接口run方法无返回值。
- Callable接口call()方法允许抛出异常;而Runnable接口run()方法不能继续上抛异常;
@FunctionalInterface
public interface Callable {
/**
* 支持泛型V,有返回值,允许抛出异常
*/
V call() throws Exception;
}
@FunctionalInterface
public interface Runnable {
/**
* 没有返回值,不能继续上抛异常
*/
public abstract void run();
}
看下demo代码吧,这样应该好理解一点哈~
/*
* @Author 捡田螺的小男孩
* @date 2020-08-18
*/
public class CallableRunnableTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
Callable callable =new Callable() {
@Override
public String call() throws Exception {
return "你好,callable";
}
};
//支持泛型
Future futureCallable = executorService.submit(callable);
try {
System.out.println(futureCallable.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("你好呀,runnable");
}
};
Future futureRunnable = executorService.submit(runnable);
try {
System.out.println(futureRunnable.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
executorService.shutdown();
}
}
运行结果:
你好,callable
你好呀,runnable
null
16、wait(),notify()和suspend(),resume()之间的区别
- wait() 使得线程进入阻塞等待状态,并且释放锁
- notify()唤醒一个处于等待状态的线程,它一般跟wait()方法配套使用。
- suspend()使得线程进入阻塞状态,并且不会自动恢复,必须对应的resume() 被调用,才能使得线程重新进入可执行状态。suspend()方法很容易引起死锁问题。
- resume()方法跟suspend()方法配套使用。
suspend()不建议使用,suspend()方法在调用后,线程不会释放已经占有的资 源(比如锁),而是占有着资源进入睡眠状态,这样容易引发死锁问题。
17.Condition接口及其实现原理
- Condition接口与Object监视器方法对比
- Condition接口使用demo
- Condition实现原理
Condition接口与Object监视器方法对比
Java对象(Object),提供wait()、notify(),notifyAll() 系列方法,配合synchronized,可以实现等待/通知模式。而Condition接口配合Lock,通过await(),signal(),signalAll() 等方法,也可以实现类似的等待/通知机制。
| 对比项 | 对象监视方法 | Condition |
|---|---|---|
| 前置条件 | 获得对象的锁 | 调用Lock.lock()获取锁,调用Lock.newCondition()获得Condition对象 |
| 调用方式 | 直接调用,object.wait() | 直接调用,condition.await() |
| 等待队列数 | 1个 | 多个 |
| 当前线程释放锁并进入等待状态 | 支持 | 支持 |
| 在等待状态中不响应中断 | 不支持 | 支持 |
| 当前线程释放锁并进入超时等待状态 | 支持 | 支持 |
| 当前线程释放锁并进入等待状态到将来的某个时间 | 不支持 | 支持 |
| 唤醒等待队列中的一个线程 | 支持 | 支持 |
| 唤醒等待队列中的全部线程 | 支持 | 支持 |
Condition接口使用demo
public class ConditionTest {
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
public void conditionWait() throws InterruptedException {
lock.lock();
try {
condition.await();
} finally {
lock.unlock();
}
}
public void conditionSignal() throws InterruptedException {
lock.lock();
try {
condition.signal();
} finally {
lock.unlock();
}
}
}
Condition实现原理
其实,同步队列和等待队列中节点类型都是同步器的静态内部类 AbstractQueuedSynchronizer.Node,接下来我们图解一下Condition的实现原理~
等待队列的基本结构图
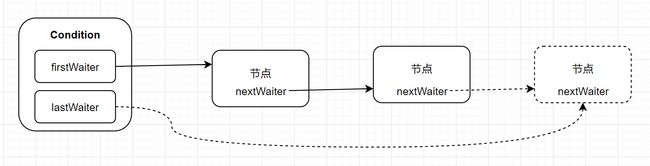
一个Condition包含一个等待队列,Condition拥有首节点(firstWaiter)和尾节点 (lastWaiter)。当前线程调用Condition.await()方法,将会以当前线程构造节点,并将节点从尾部加入等待队
AQS 结构图
ConditionI是跟Lock一起结合使用的,底层跟同步器(AQS)相关。同步器拥有一个同步队列和多个等待队列~

等待

当调用await()方法时,相当于同步队列的首节点(获取了锁的节点)移动到Condition的等待队列中。
通知

调用Condition的signal()方法,将会唤醒在等待队列中等待时间最长的节点(首节点),在
唤醒节点之前,会将节点移到同步队列中。
18、线程池如何调优,最大数目如何确认?
在《Java Concurrency in Practice》一书中,有一个评估线程池线程大小的公式
Nthreads=NcpuUcpu(1+w/c)
- Ncpu = CPU总核数
- Ucpu =cpu使用率,0~1
- W/C=等待时间与计算时间的比率
假设cpu 100%运转,则公式为
Nthreads=Ncpu*(1+w/c)
估算的话,酱紫:
- 如果是IO密集型应用(如数据库数据交互、文件上传下载、网络数据传输等等),IO操作一般比较耗时,等待时间与计算时间的比率(w/c)会大于1,所以最佳线程数估计就是 Nthreads=Ncpu*(1+1)= 2Ncpu 。
- 如果是CPU密集型应用(如算法比较复杂的程序),最理想的情况,没有等待,w=0,Nthreads=Ncpu。又对于计算密集型的任务,在拥有N个处理器的系统上,当线程池的大小为N+1时,通常能实现最优的效率。所以 Nthreads = Ncpu+1
有具体指参考呢?举个例子
比如平均每个线程CPU运行时间为0.5s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU核心数为8,那么根据上面这个公式估算得到:线程池大小=(1+1.5/05)*8 =32。
参考了网上这篇文章,写得很棒,有兴趣的朋友可以去看一下哈:
- 根据CPU核心数确定线程池并发线程数
19、 假设有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完后执行?
可以使用join方法解决这个问题。比如在线程A中,调用线程B的join方法表示的意思就是:A等待B线程执行完毕后(释放CPU执行权),在继续执行。
代码如下:
public class ThreadTest {
public static void main(String[] args) {
Thread spring = new Thread(new SeasonThreadTask("春天"));
Thread summer = new Thread(new SeasonThreadTask("夏天"));
Thread autumn = new Thread(new SeasonThreadTask("秋天"));
try
{
//春天线程先启动
spring.start();
//主线程等待线程spring执行完,再往下执行
spring.join();
//夏天线程再启动
summer.start();
//主线程等待线程summer执行完,再往下执行
summer.join();
//秋天线程最后启动
autumn.start();
//主线程等待线程autumn执行完,再往下执行
autumn.join();
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
class SeasonThreadTask implements Runnable{
private String name;
public SeasonThreadTask(String name){
this.name = name;
}
@Override
public void run() {
for (int i = 1; i <4; i++) {
System.out.println(this.name + "来了: " + i + "次");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果:
春天来了: 1次
春天来了: 2次
春天来了: 3次
夏天来了: 1次
夏天来了: 2次
夏天来了: 3次
秋天来了: 1次
秋天来了: 2次
秋天来了: 3次
20. LockSupport作用是?
- LockSupport作用
- park和unpark,与wait,notify的区别
- Object blocker作用?
LockSupport是个工具类,它的主要作用是挂起和唤醒线程, 该工具类是创建锁和其他同步类的基础。
public static void park(); //挂起当前线程,调用unpark(Thread thread)或者当前线程被中断,才能从park方法返回
public static void parkNanos(Object blocker, long nanos); // 挂起当前线程,有超时时间的限制
public static void parkUntil(Object blocker, long deadline); // 挂起当前线程,直到某个时间
public static void park(Object blocker); //挂起当前线程
public static void unpark(Thread thread); // 唤醒当前thread线程
看个例子吧:
public class LockSupportTest {
public static void main(String[] args) {
CarThread carThread = new CarThread();
carThread.setName("劳斯劳斯");
carThread.start();
try {
Thread.currentThread().sleep(2000);
carThread.park();
Thread.currentThread().sleep(2000);
carThread.unPark();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class CarThread extends Thread{
private boolean isStop = false;
@Override
public void run() {
System.out.println(this.getName() + "正在行驶中");
while (true) {
if (isStop) {
System.out.println(this.getName() + "车停下来了");
LockSupport.park(); //挂起当前线程
}
System.out.println(this.getName() + "车还在正常跑");
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void park() {
isStop = true;
System.out.println("停车啦,检查酒驾");
}
public void unPark(){
isStop = false;
LockSupport.unpark(this); //唤醒当前线程
System.out.println("老哥你没酒驾,继续开吧");
}
}
}
运行结果:
劳斯劳斯正在行驶中
劳斯劳斯车还在正常跑
劳斯劳斯车还在正常跑
停车啦,检查酒驾
劳斯劳斯车停下来了
老哥你没酒驾,继续开吧
劳斯劳斯车还在正常跑
劳斯劳斯车还在正常跑
劳斯劳斯车还在正常跑
劳斯劳斯车还在正常跑
劳斯劳斯车还在正常跑
劳斯劳斯车还在正常跑
LockSupport的park和unpark的实现,有点类似wait和notify的功能。但是
- park不需要获取对象锁
- 中断的时候park不会抛出InterruptedException异常,需要在park之后自行判断中断状态
- 使用park和unpark的时候,可以不用担心park的时序问题造成死锁
- LockSupport不需要在同步代码块里
- unpark却可以唤醒一个指定的线程,notify只能随机选择一个线程唤醒
Object blocker作用?
方便在线程dump的时候看到具体的阻塞对象的信息。
公众号

参考与感谢
- 《java并发编程的艺术》
- 杂谈 什么是伪共享(false sharing)?
- 根据CPU核心数确定线程池并发线程数
- LockSupport的用法及原理
- 探讨缓存行与伪共享