R语言 电力窃漏电用户自动识别实验
实验所用数据上传在我的资源了
一、实验目的
了解数据挖掘的过程。
掌握神经网络构建分类模型。
二、实验内容
实验数据包含所有窃漏电用户及正常用户的窃漏电评价指标数据(电量、线损及告警)和该用户在当天是否窃漏电的标签。选取其中291个样本数据,得到专家样本,数据见“model.csv”。使用神经网络实现分类预测模型,并使用混淆矩阵对模型进行评价。
三、实验方法与步骤
1、 把已经过预处理的专家样本数据“model.csv”读入工作空间。
2、 把工作空间的建模数据随机分成两部分,一部分用于训练,另一部分用于测试。
3、 使用nnet包里的nnet()函数以及训练数据构建神经网络模型,使用predict函数和构建的神经网络模型分别对训练数据和测试数据进行分类。
4、 使用混淆矩阵并计算准确率,对模型进行评价。
代码实现(将完整代码粘贴到以下区域,关键代码应使用注释说明):
> data_FB=read.csv("E:/TZZY/zwy/chapter1/窃漏电用户分布分析.csv",header = TRUE)
> View(data_FB)
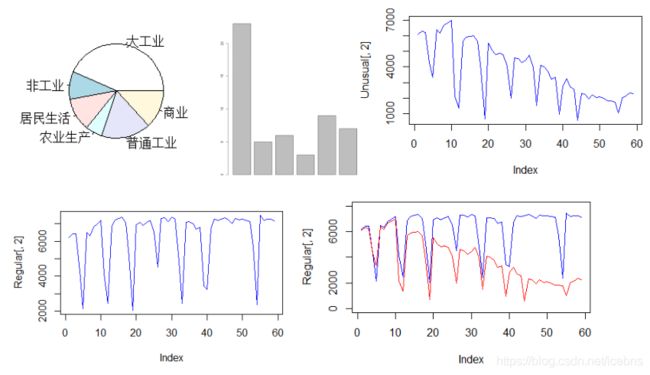
> Type = table(data_FB[,3])
> Type
大工业 非工业 居民生活 农业生产 普通工业 商业
23 5 6 3 9 7
> pie(Type)
> Unusual<-read.csv("E:/TZZY/zwy/chapter1/窃电用电量数据.csv",header = TRUE)
> View(Unusual)
> plot(Unusual[,2],type = "l",col="blue")
> Regular<-read.csv("E:/TZZY/zwy/chapter1/正常用电量数据.csv",header = TRUE)
> View(Regular)
> plot(Regular[,2],type = "l",col="blue")
> plot(Regular[,2],ylim = c(0,8000),type = "l",col = "blue")#无法显示
> lines(Unusual[,2],col="red",type="l")
> lagrange <- function(x, xi, yi) {
+ n <- length(xi)
+ lage <- 0
+ for (i in 1:n) {
+ li <- 1
+ for (j in 1:n) {
+ if (i != j) {
+ li <- li * (x - xi[j]) / (xi[i] - xi[j])
+ }
+ }
+ lage <- li * yi[i] + lage
+ }
+ return(lage)
+ }
> missing_data=read.csv("E:/TZZY/zwy/chapter1/missing_data.csv",header=F)
> View(missing_data)
> missdata <- missing_data
> missdata
V1 V2 V3
1 235.8333 350.8333 478.3231
2 236.2708 351.2708 515.4564
3 238.0521 353.0521 517.0909
4 235.9063 350.9063 514.8900
5 236.7604 351.7604 NA
6 NA 352.4167 486.0912
7 237.4167 353.6563 516.2330
8 238.6563 NA NA
9 237.6042 352.6042 435.3508
10 238.0313 353.0313 487.6750
11 235.0729 350.0729 NA
12 235.5313 350.5313 660.2347
13 NA 349.4688 621.2346
14 234.4688 NA 611.3408
15 235.5000 350.5000 643.0863
16 235.6354 350.6354 642.3482
17 234.5521 349.5521 NA
18 236.0000 NA 602.9347
19 235.2396 350.2396 589.3457
20 235.4896 350.4896 556.3452
21 236.9688 351.9688 538.3470
> for (k in 1:3) {
+ #共有三列都有缺失数据,所以这里1至3
+ x <- which(is.na(missing_data[, k]))
+ x1 <- c(0, x) #x1=(0, 5, 8, 11, 17)
+ x2 <- c(x, nrow(missing_data)+1) #x2=(5, 8, 11, 17, 22)
+ x12 <- x2 - x1 - 1 #x12=(4, 2, 2, 5, 4)
+ #缺失值前面的序数
+ xx1 <- x12[1:(length(x12) - 1)] #xx1 =(4, 2, 2, 5)
+ #缺失值后面的序数
+ xx2 <- x12[2:(length(x12))] #xx2=(2, 2, 5, 4)
+ j <- 1
+ for (m in x) {
+ if (xx1[j] >= 5) {
+ xi <- (m - 5):(m - 1)
+ } else {
+ xi <- (m - xx1[j]):(m - 1)
+ }
+ if (xx2[j] >= 5) {
+ xi <- c(xi, (m + 1):(m + 5))
+ } else {
+ xi <- c(xi, (m + 1):(m + xx2[j]))
+ }
+ yi <- missing_data[xi, k]
+ missdata[m, k] <- lagrange(m, xi, yi)
+ print(c(m, missdata[m, k]))
+ j <- j + 1
+ }
+ }
[1] 6.0000 237.1512
[1] 13.000 235.315
[1] 8.0000 352.9031
[1] 14.0000 348.6058
[1] 18.0000 349.6297
[1] 5.0000 503.7444
[1] 8.0000 472.0948
[1] 11.0000 634.3942
[1] 17.0000 618.1972
> View(missdata)
> Power <- read.csv("E:/TZZY/zwy/chapter1/用户日用电量.csv")
> View(Power)
> k <- rep(0, nrow(Power))
> Down <- Power$日电量
> for (i in 1:nrow(Power)) {
+ if (i <= 5) {
+ l <- 1:(i + 5)
+ }
+ if (i >5 & i < (nrow(Power) - 5)) {
+ l <- (i - 5):(i + 5)
+ }
+ if (i >= (nrow(Power) - 5)) {
+ l <- (i-5):nrow(Power)
+ }
+ k[i] <- cov(Down[l], l) / var(l)
+ }
> #标记用电量趋势
> Decrease <- rep(0, nrow(Power))
> for (i in 2:nrow(Power)) {
+ if (k[i] < k[i - 1]) {
+ Decrease[i] <- 1
+ }
+ if (k[i] >= k[i - 1]) {
+ Decrease[i] <- 0
+ }
+ }
> Decrease
[1] 0 1 1 0 0 0 0 1 1 1 1 0 1 1 1 1 0 0 0 0 0 1 0 0 0 0 1 1 0 0
[31] 1 1 1 1 0 0 0 0 0 0 0 1 1
> #统计十一天内趋势下降次数
> Total <- rep(0, nrow(Power))
> for (i in 1:nrow(Power)) {
+ if (i < 5) {
+ m <- 1:(i + 5)
+ }
+ if (i >= 5 & i <= nrow(Power) - 5) {
+ m <- (i - 4):(i + 5)
+ }
+ if (i > nrow(Power) - 5) {
+ m <- (i - 4):nrow(Power)
+ }
+ Total[i] <- sum(Decrease[m])
+ }
> Total
[1] 2 2 3 4 5 6 5 5 6 7 8 8 7 6 5 4 5 4 3 2 1 2 3 3 3 4 4 5 6 6
[31] 6 5 4 4 4 3 3 3 2 2 2 2 2
> View(Total)
> data_loss <- read.csv("E:/TZZY/zwy/chapter1/线损.csv")
> View(data_loss)
> data_loss$日线损率 <- (data_loss[, 3] - data_loss[, 4]) / data_loss[, 3]
> # 便于代码调用,将日线损率数据赋予变量v
> V <- data_loss$日线损率
> # Vb为当天与后5天共6天的线损率平均值
> # Vf为当天与前5天共6天的线损率平均值
> n <- nrow(data_loss)
> #back后面
> Vb <- rep(0, n)
> #front前面
> Vf <- rep(0, n)
> #设置变量E,存放线损指标
> E <- rep(0, n)
> for (i in 1:n) {
+ if (i <= 5) {
+ Vb[i] <- mean(V[i:(i + 5)])
+ Vf[i] <- mean(V[1:i])
+ }
+ if (i > 5 & i < n - 5) {
+ Vb[i] <- mean(V[i:(i + 5)])
+ Vf[i] <- mean(V[(i - 5):i])
+ }
+ if (i >= n - 5) {
+ Vb[i] <- mean(V[i:n])
+ Vf[i] <- mean(V[(i - 5):i])
+ }
+ if ((Vb[i] - Vf[i]) / Vf[i] > 0.01) {
+ E[i] <- 1
+ }
+ if ((Vb[i]-Vf[i]) / Vf[i] <= 0.01) {
+ E[i] <- 0
+ }
+ }
> View(data_loss)
> #告警类指标
> data_alarm <- read.csv("E:/TZZY/zwy/chapter1/告警.csv")
> data <- read.csv("E:/TZZY/zwy/chapter1/用户.csv")
> View(data_alarm)
> View(data)
> # 构造ID&date属性
> data_alarm$ID_date <- paste(data_alarm[, 1], data_alarm[, 2])
> data$ID_date <- paste(data[, 1], data[, 2])
> # 统计用户每天的告警次数
> D <- data.frame(matrix(0, nrow(data), nrow(data_alarm)))
> for (i in (1:nrow(data))) {
+ for (k in (1:nrow(data_alarm))) {
+ if (data$ID_date[i] == data_alarm$ID_date[k]) {
+ D[i, k] <- 1
+ } else {
+ D[i, k] <- 0}
+ }
+ }
> #按行计算总和
> D$sum <- apply(D, 1, sum)
> data$alarm_ind <- D$sum
> #只保留ID,日期和告警次数
> data <- data[, c(1, 2, 6)]
> View(data)
> #专家样本数据分割代码实现
> Data<-read.csv("E:/TZZY/zwy/chapter1/model.csv")
> head(Data)
时间 用户编号 电量趋势增长指标 线损指标 告警类指标
1 2014年9月6日 9900667154 4 1 1
2 2014年9月20日 9900639431 4 0 4
3 2014年9月17日 9900585516 2 1 1
4 2014年9月14日 9900531154 9 0 0
5 2014年9月17日 9900491050 3 1 0
6 2014年9月13日 9900461501 2 0 0
是否窃漏电
1 1
2 1
3 1
4 0
5 0
6 0
> colnames(Data)<-c("time","userid","ele_ind","loss_ind","alarm_ind","class")
> set.seed(1)
> ind<-sample(2,nrow(Data), replace = TRUE, prob = c(0.8, 0.2))
> trainData<-Data[ind==1,]
> testData<-Data[ind==2,]
> #数据存储
> write.csv(trainData,"E:/TZZY/zwy/chapter1/t1.csv",row.names=FALSE)
> write.csv(testData,"E:/TZZY/zwy/chapter1/t2.csv",row.names=FALSE)
> #模型构建
> trainData<-read.csv("E:/TZZY/zwy/chapter1/t1.csv")
> View(trainData)
> str(trainData)
'data.frame': 244 obs. of 6 variables:
$ time : Factor w/ 19 levels "2014年9月10日",..: 16 11 8 8 11 10 19 9 7 16 ...
$ userid : num 9.9e+09 9.9e+09 9.9e+09 9.9e+09 9.9e+09 ...
$ ele_ind : int 4 4 2 3 3 3 4 10 10 2 ...
$ loss_ind : int 1 0 1 1 1 0 1 1 1 0 ...
$ alarm_ind: int 1 4 1 0 3 0 0 2 3 3 ...
$ class : int 1 1 1 0 1 0 0 1 1 0 ...
> trainData<-transform(trainData,class=as.factor(class))
> library(nnet)
#设定神经网络的输入节点为ele_ind,loss_ind,alarm_ind,输出节点为class,数据为traindata,隐层节点数为10,权值的衰减参数为0.05
> nnet.model<-nnet(class~ele_ind+loss_ind+alarm_ind,trainData,size=10,decat=0.05)
# weights: 51
initial value 145.828042
iter 10 value 60.432715
iter 20 value 43.198470
iter 30 value 37.766738
iter 40 value 34.227301
iter 50 value 33.415754
iter 60 value 32.777508
iter 70 value 32.597031
iter 80 value 32.582463
iter 90 value 32.576003
iter 100 value 32.573308
final value 32.573308
stopped after 100 iterations
> #模型评价
> testData<-read.csv("E:/TZZY/zwy/chapter1/t2.csv")
> View(testData)
> str(testData)
'data.frame': 47 obs. of 6 variables:
$ time : Factor w/ 16 levels "2014年9月11日",..: 4 3 10 1 16 15 14 11 7 11 ...
$ userid : num 9.90e+09 9.90e+09 9.90e+09 8.91e+09 8.81e+09 ...
$ ele_ind : int 9 2 5 0 3 5 2 4 4 2 ...
$ loss_ind : int 0 0 0 0 0 1 1 0 1 1 ...
$ alarm_ind: int 0 0 2 2 1 1 4 0 0 2 ...
$ class : int 0 0 1 0 0 1 1 0 0 0 ...
> testData<-transform(testData,class=as.factor(class))
> xx=predict(nnet.model,testData,type = "class")
> confusion<-table(testData$class, xx)
> confusion
xx
0 1
0 39 1
1 3 4
> accuracy<-sum(diag(confusion))*100/sum(confusion)
> accuracy
- 91.48936
三、实验结果
实验结果(将混淆矩阵、准确率截图粘贴到以下区域):

四、思考与实验总结
1、本案例数据挖掘过程大致包含哪些步骤?用一句话简要介绍每个步骤。
答:
读取文件:通过read.csv()读入数据,使用View()函数,浏览数据。
数据探索(绘图):barplot()绘制柱状图,pie()绘制扇形图,plot()散点图(type=”l”时是折线图)。
数据清洗:主要目的是从业务以及建模的相关方面考虑,筛选出需要的数据。在本案例中需要清洗不可能存在窃漏电行为的大用户和节假日用电数据。
缺失值处理:采用拉格朗日插值法,对缺失数据进行插补。
数据变换:将特征不明显的数据重新构造,得出能反映用户窃漏电行为的某些规律,数据变换后的数据作为专家样本。
数据分割:把数据随机分成两部分,一部分用于训练,另一部分用于测试。
模型构建:采用神经网络方法,基于专家样本,构建能根据用电数据,自动识别窃漏电用户的模型。
模型评价:使用混淆矩阵和准确度进行模型评价。
2、通过查看nnet()的帮助文档、查询网络资料等方式,总结nnet()函数的参数和用法。
答:
nnet包执行单隐层前馈神经网络,nnet()函数涉及的主要参数有隐层节点数(size)、节点权重(weights)、最大迭代次数(maxit)等,为了达到最好的分类效果,这些都是需要用户根据经验或者不断地尝试来确定的。
用法:
nnet(x, ...)
nnet(formula, data, weights, ...,
subset, na.action, contrasts = NULL)
nnet(x, y, weights, size, Wts, mask,
linout = FALSE, entropy = FALSE, softmax = FALSE,
censored = FALSE, skip = FALSE, rang = 0.7, decay = 0,
maxit = 100, Hess = FALSE, trace = TRUE, MaxNWts = 1000,
abstol = 1.0e-4, reltol = 1.0e-8, ...)
参数对照:
formula:形式类~x1+x2+的公式。。。
x:例如x值的矩阵或数据框。
y:例如目标值的矩阵或数据框。
weights:每个示例的权重-如果缺少,则默认为1。
size:隐藏层中的单位数。如果存在跳过层单位,则可以为零。
data:优先从中获取公式中指定变量的数据帧。
subset:指定要在训练样本中使用的案例的索引向量。
na.action:指定在找到NAs时要执行的操作的函数。默认操作是使过程失败。
contrasts:在模型公式中作为变量出现的部分或全部因素的对比列表。
Wts:初始参数向量。如果缺失,随机选择。
mask:指示应优化哪些参数的逻辑向量(默认为全部)。
linout:线性输出单位开关。默认物流输出单位。
Entropy:熵(=最大条件似然)拟合开关。默认为最小二乘法。
softmax:切换和最大条件似然拟合。
censored:softmax上的一种变体,其中非零目标表示可能的类。
skip :切换以添加从输入到输出的跳过层连接。(是否允许跳过隐藏层)
rang:[范围,范围]上的初始随机权重。
decay:重量衰减参数。默认值0。
maxit:最大迭代次数。默认值100。
Hess:如果为真,则在找到的最佳权重集处的拟合度量的Hessian将作为组件Hessian返回。
trace:用于跟踪优化的开关。默认为真。
MaxNWts:允许的最大重量。代码中没有内在限制,但是增加maxnwt可能会允许非常缓慢和耗时的拟合。
abstol:符合标准低于abstol,则停止,这表示符合要求。
reltol:如果优化器无法将拟合条件减少至少1-reltol的因子,则停止。
... :传入或传出其他方法的参数。