滴滴-通过多智能体强化学习进行有效的大规模车队管理
1. 背景
1.1 在线乘车共享平台的意义
诸如Uber和滴滴出行之类的大型在线乘车共享平台已经改变了人们出行,生活和社交的方式。通过利用蜂窝网络和全球定位系统等信息技术的进步和广泛采用,共享乘车平台将道路上未充分使用的车辆重新分配给需要运输的乘客。运输资源的优化极大地缓解了交通拥堵,并弥补了运输供需之间曾经巨大的差距【1】。
1.2 主要挑战
乘车共享平台的一个主要挑战是平衡需求和供应,即乘客和驾驶员的接送订单。在大城市中,尽管每天要提供数百万次的拼车订单,但由于附近缺少可用的驾驶员,因此仍然无法满足大量的乘客要求。另一方面,有很多可用的驾驶员在其他位置寻找订单。如果将可用的驾驶员引导到需求量大的地点,则将大大增加所服务的订单数量,从而同时使社会各方面受益:运输能力的效用将得到改善,驾驶员的收入和乘客的满意度将得到提高。增加并扩大公司的市场份额和收入。车队管理是一项关键技术组件,它通过提前重新分配可用车辆来实现满足未来需求的高效率,从而平衡供需之间的差异。
1.3 滴滴出行的解决方法
近年来,随着深度强化学习(DRL)在建模先前难以解决的智力挑战性决策问题【3,4】中取得的巨大成功。鉴于这些进展,滴滴提出了一种新颖的DRL方法,以学习用于车队管理的高效分配策略。
主要包括以下部分:
-
通过设置合适的agent、reward以及state提出一种有效的用于大规模车队管理的多智能体强化学习方法;
-
提出上下文化多主题强化学习框架,并开发了两种具体的算法:
- contextual multi-agent actor-critic(cA2C)
- contextual deep Q-learning(cDQN)
在多主体DRL中,上下文算法不仅可以在每次数千个学习主体之间实现有效的显式协调,而且还 可以适应动态变化的动作空间。
2.解决方案
2.1 问题说明
考虑了为在线乘车共享平台管理大量可用的同类车辆的问题。管理的目标是通过将可用车辆重新定位到需求缺口比当前缺口大的位置,来最大化平台的总商品量(GMV:所有已服务订单的价值)。图1中提供了该问题的时空图示。
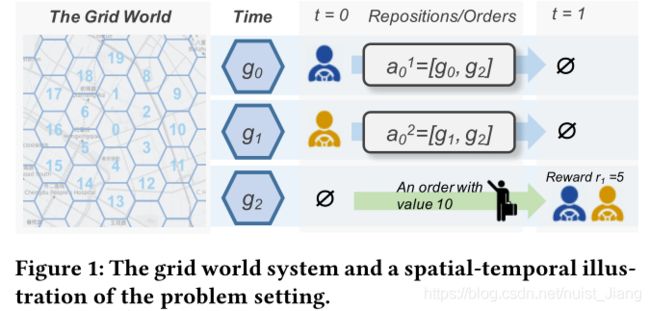
在该图中,使用六边形网格世界表示地图,并将一天的持续时间分为T=144个时间间隔(每个间隔10分钟)。在每个时间间隔,订单在每个网格中随机出现,并由同一网格或六个附近网格中的可用车辆提供服务。车队管理的目标是提前确定从每个网格到相邻网格的可用车辆数量,以便为大多数订单提供服务。
2.2 模型参数说明
为了解决这个问题,滴滴使用多智能体强化学习【5】来表述这个问题。在此构想中,使用一组具有较小动作空间的同种类的代理集,然后将全局奖励划分到每个网格。由于简化了行动维度和基于拆分奖励的明确信用分配,相比单一代理设置,这将导致更有效的学习过程。形式上,我们将车队管理问题建模为N个agent的马尔可夫博弈G,它由元组 G = ( N , S , A , P , R , γ ) G =(N,S,A,P,R,γ) G=(N,S,A,P,R,γ)定义,其中N, S , A , P , R , γ S,A,P,R, γ S,A,P,R,γ分别是代理的数量,状态集,联合动作空间,转移概率函数,奖励函数和折扣因子。具体定义如下:
- 代理:将可用的车辆(或等效地为空转的驾驶员)视为代理,并且同一时空节点中的车辆是同质的,即,位于相同时间间隔的相同区域的车辆被视为相同的代理(其中所有代理具有相同的策略)。
尽管唯一的异构代理的数量始终为 N N N,但代理的数量 N t N_{t} Nt随时间变化. - 状态 s t ∈ S s_{t}∈S st∈S:考虑到可用车辆和订单的空间分布(即每个网格中可用车辆和订单的数量)和当前时间t(使用one-hot编码),在每个时间 t t t维护一个全局状态 s t s_{t} st。代理 i i i的状态 s t i s_{t}^{i} sti定义为其所在网格的标识和共享的全局状态,例如, s i t = [ s t , g j ] ∈ R N × 3 + T s_{i}^{t}=[s_{t},g_{j}]∈R^{N×3+T} sit=[st,gj]∈RN×3+T,其中 g j g_{j} gj是网格ID的one-hot编码。我注意到,位于同一网格的代理具有相同的状态 s t i s_{t}^{i} sti。
- 动作 a t ∈ A = A 1 × . . . × A N t a_{t}∈A=A_{1}×...×A_{N_{t}} at∈A=A1×...×ANt: a t = { a t i } 1 N t a_{t}=\{a_{t}^{i}\}_{1}^{N_{t}} at={ati}1Nt表示在时间 t t t时的联合动作用于指导所有可用车辆的分配策略。每一个代理的动作空间 A i A_{i} Ai指明了该代理下一步可以到达的位置。其给定一个七个明确动作的集合 { k } k = 1 7 \{k\}_{k=1}^{7} {k}k=17,前六个动作表示将该代理分配到其相邻的六个网格,最后一个动作 a t i = 7 a_{t}^{i}=7 ati=7表示待在当前的网格。例如,如图1所示,动作 a 0 1 = 2 a_{0}^{1} = 2 a01=2表示在时间0时将第一个代理从当前网格分配到第二个相邻的网格。为了简明扼要的演示,使用 a t i ≜ [ g 0 , g 1 ] a_{t}^{i}≜[g_{0},g_{1}] ati≜[g0,g1]表示代理 i i i从网格 g 0 g_{0} g0移动到 g 1 g_{1} g1.此外,代理的行动空间取决于他们的位置。位于角网格处的代理具有较小的动作空间。我们还假定该动作是确定性的:如果 a t i ≜ [ g 0 , g 1 ] a_{t}^{i}≜[g_{0},g_{1}] ati≜[g0,g1],则代理 i i i将在时间 t + 1 t + 1 t+1到达网格 g 1 g_{1} g1。
- 奖励函数 R i ∈ R = S × A → R R_{i}∈R=S×A→R Ri∈R=S×A→R:每个代理都与奖励函数相关联,并且同一位置的所有代理都具有相同的奖励函数。第 i i i个代理尝试最大化它自己的期望折现收益: E [ ∑ k = 0 ∞ γ k r t + k i ] E[\sum_{k=0}^{∞}γ^{k}r_{t+k}^{i}] E[∑k=0∞γkrt+ki].其中对于第 i i i个代理每个单独的奖励 r t i r_{t}^{i} rti与动作 a t i a_{t}^{i} ati相关,被定义为在时间 t + 1 t+1 t+1与第 i i i个代理一样到达相同网格的所有的代理的平均收入。由于在同一时间和同一位置的单个奖励是相同的,因此我们在时间 t t t和网格 g j g_{j} gj上的奖励定义为 r t ( g j ) r_{t}(g_{j}) rt(gj)。这种设计旨在避免贪婪行为,这种贪婪行为会将过多的司机送往订单价值高的地方。同时这种设计还可以使每个代理的收益最大化以及GMV的最大化(一天中所有服务订单的价值)保持一致。
- 状态转移概率 p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_{t},a_{t}) p(st+1∣st,at): S × A × S → [ 0 , 1 ] S×A×S→[0,1] S×A×S→[0,1]:它给出了当前状态 s t s_{t} st转移到状态 s t s_{t} st下采取联合动作 a t a_{t} at的概率。注意到,尽管动作是确定的,但是每个时间段在不同的网格中都会出现新的车辆和订单。而存在的车辆也会出现随机地离线。
更具体地讲,通过基于图1中的上述问题给出示例。在时间 t = 0 t=0 t=0时,代理1通过动作 a 0 1 a_{0}^{1} a01从位置 g 0 g_{0} g0转移到位置 g 1 g_{1} g1,代理2也通过动作 a 0 2 a_{0}^{2} a02从位置 g 1 g_{1} g1转移到位置 g 2 g_{2} g2。在时间 t = 1 t=1 t=1,两个代理同时到达网格 g 2 g_{2} g2,而同时一个新的价值10的订单出现在该网格中,那么对于动作 a 0 1 a_{0}^{1} a01和动作 a 0 2 a_{0}^{2} a02的奖励 r 1 r_{1} r1就是所有在网格 g 2 g_{2} g2处的代理数除该订单的价值,也就是 10 2 = 5 \frac {10}{2}=5 210=5。
2.3 模型算法
在本节,滴滴提出了两种新颖的上下文多agent强化学习方法:上下文多智能体参与者评论(cA2C)和上下文DQN(cDQN)算法。我们首先简要介绍基本的多智能体强化学习方法。
2.3.1 Independent DQN
Indenpendent DQN【6】结合了independent Q-learning【7】和DQN【8。将小规模的agent扩展到大规模的agent的independent DQN的一种直接方法就是共享网络参数并使用ID来区分不同的agent。对于从所有agent收集到的transition,可以通过最小化以下损失函数来更新网络参数:
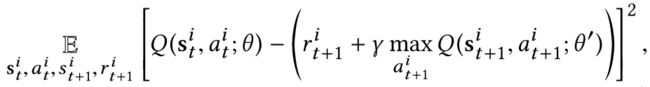
其中 θ ′ θ' θ′包括定期更新的目标Q网络的参数, θ θ θ包括输出基于ϵ-greedy policy【9】的动作价值的行为Q网络的参数。这种方法经过广泛的调整后仍可以很好地工作,但性能会出现较大差异,并且还会重新分配过多的车辆。此外,此外,由于每个代理都基于其动作价值(action value)独立执行其行为,因此很难实现大规模代理之间的协作。
2.3.2 Contextual DQN
我们假定allocation action之后的的位置转移已经确定,因此将agent转移到相同的网格的动作应该具有相同的动作价值(action value)。在这种情况下,对于所有的agent的价值不同的动作的总数应该与网格数相同。更正式地说,对于任意各一个agent i i i( s t i = [ s t , g i ] , a t i ≜ [ g i , g d ] , g i ∈ N e r ( g d ) s_{t}^{i}=[s_{t},g_{i}],a_{t}^{i}≜[g_{i},g_{d}],g_{i}∈Ner(g_{d}) sti=[st,gi],ati≜[gi,gd],gi∈Ner(gd)),那么以下公式成立:
Q ( s t i , a t i ) = Q ( s t , g d ) Q(s_{t}^{i},a_{t}^{i})=Q(s_{t},g_{d}) Q(sti,ati)=Q(st,gd)
因此,在每个时间步长,我们只需N个不同的action-value(Q(s_{t},g_{j},∀j=1,…,N),而上面提到的优化方法(损失函数)可以被替换为最小化为下面的均方差损失:
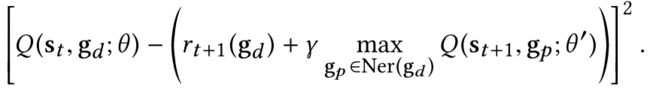
通过将动作价值函数的输出维度从 R ∣ s t ∣ → R 7 R^{|s_{t}|}→R^{7} R∣st∣→R7缩减到 R ∣ s t ∣ → R R^{|s_{t}|}→R R∣st∣→R.此外,我们为所有的agent在每一个时间段建立一个统一的动作价值表,作为协调agent的动作的基础。
地理环境(Geographic context)。
在六角形网格系统中,边界网格和被不可行网格(例如湖)包围的网格具有缩减的动作数量。为了适应这一点,我们为每个网格计算了一个地理环境 G g j ∈ R 7 G_{gj}∈R^{7} Ggj∈R7,是一个二进制向量用于过滤在网格 g j g_{j} gj上的agent的无效动作。向量 G g j G_{gj} Ggj中的第 k k k个元素表示从网格 g j g_{j} gj移动到第k个方向的有效性。定义KaTeX parse error: Expected 'EOF', got '}' at position 5: g_[d}̲为网格 g j g_{j} gj在第k个方向上的邻居网格,那么 G g j G_{gj} Ggj的第k个元素的值为:
[ G t , g j ] k = { 1 i f g d i s v a l i d g r i d , 0 o t h e r w i s e , [G_{t,g_{j}}]_{k} = \begin{cases} 1 \qquad \qquad if \ g_{d} \ is\ valid\ grid,\\ 0 \qquad \qquad otherwise, \end{cases} [Gt,gj]k={1if gd is valid grid,0otherwise,
其中, k = 0 , . . . , 6 k=0,...,6 k=0,...,6最后一个维度表示停留在当前维度,该值永远为1.
协作环境(Collaborative context):
为了避免代理在冲突的方向上的移动(例如,一些代理同时从网格 g 1 g_{1} g1转移到网格 g 2 g_{2} g2以及从网格 g 2 g_{2} g2转移到网格 g 1 g_{1} g1)。我们为每个时间阶段为每个网格 g j g_{j} gj提出一个协同环境 C t , g j ∈ R 7 C_{t,g_{j}}∈R^{7} Ct,gj∈R7.基于集中的动作价值 Q ( s t , g j ) Q(s_{t},g_{j}) Q(st,gj),我们限制有效的动作以使在网格 g j g_{j} gj的agent被导航到动作价值更高的网格或保持待在当前网格。因此,二进制向量 C t , g j C_{t,g_{j}} Ct,gj将限制移动到比待在当前网格的动作价值更低的网格。更正式地说,与动作价值 Q ( s t , g i ) Q(s_{t},g_{i}) Q(st,gi)相关的向量 C t , g j C_{t,g_{j}} Ct,gj的第k个元素的值被定义为:
[ C t , g j ] k = { 1 , i f Q ( s t , g i ) > = Q ( s t , g j ) , 0 , o t h e r w i s e . [C_{t,g_{j}}]_{k}= \begin{cases} 1,\qquad \qquad if\ Q(s_{t},g_{i})>=Q(s_{t},g_{j}),\\ 0,\qquad \qquad otherwise. \end{cases} [Ct,gj]k={1,if Q(st,gi)>=Q(st,gj),0,otherwise.
在计算完协作环境和地理环境之后,然后根据从这两种环境下幸存下来的动作价值来执行ϵ-greedy ploicy.假定代理 i i i在时间t,给定状态 s t i s_{t}^{i} sti时的原始动作价值 Q ( s t i ) ∈ R ≥ 0 7 Q(s_{t}^{i})∈R_{≥0}^{7} Q(sti)∈R≥07,那么应用上面的环境之后的有效的动作价值为:
q ( s t i ) = Q ( s t i ) ∗ C t , g j ∗ G t , g j q(s_{t}^{i})=Q(s_{t}^{i})*C_{t,g_{j}}*G_{t,g_{j}} q(sti)=Q(sti)∗Ct,gj∗Gt,gj
之所以启用协作环境,是因为将转移到相同位置的不同代理的动作价值限制为相同,以便可以进行比较,这在independent DQN中是不可能的。此方法要求操作值始终为非负值,因为代理始终获得非负值奖励,所以该值始终成立。 cDQN的算法在Alg 2中进行了详细说明。

2.3.3 Contextual Actor-Critic
现在,我们介绍了Contextual multi-agent actor-critic(cA2C)算法,这是一种multi-agent policy gradient算法,可对其策略进行调整以适应动态变化的动作空间。同时,它不仅在非平稳环境中获得了更稳定的性能,而且获得了更加高效的学习过程。在cA2C的设计中有两个主要思想:
- 1.A centralized value function shared by all agents with an expected update;;
- 2.Policy context embedding,在代理之间建立明确的协作方式,可以更快地进行培训练,并且可以灵活地针对不同的动作空间制定策略。通过最小化下面从Bellman方程得出的损失函数来学习集中状态-价值函数:
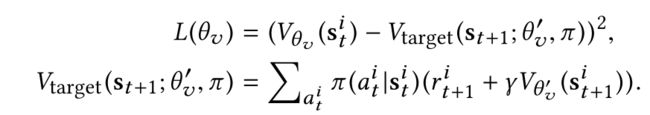
其中,我们使用 θ v θ_{v} θv来表示价值网络的参数,使用 θ v ′ θ_{v}^{'} θv′来表示目标价值网络。由于同时保持不动的agent被均质化并享有相同的内部状态,因此每个时间段都有 N N N个不同的agent状态,以及 N N N个不同的状态-价值 ( V ( s t , g j ) , ∀ j = 1 , . . . , N ) (V(s_{t},g_{j}),∀j=1,...,N) (V(st,gj),∀j=1,...,N)。状态-价值输出被定义为 v t ∈ R N v_{t}∈R^{N} vt∈RN,其中每个元素 ( v t ) j = V ( s t , g j ) (v_{t})_{j}=V(s_{t},g_{j}) (vt)j=V(st,gj)被看做是agent在时间 t t t时到网格 g j g_{j} gj得到的预期收益。为了价值函数的稳定学习,我们使用参数 θ v ′ θ_{v}^{'} θv′来修补目标价值网络 V t a r g e t V_{target} Vtarget,该参数在每一个episode的结尾更新。注意,方程式 L ( θ v ) L(θ_{v)} L(θv)预期更新和离线训练actor/critic的方式与使用TD error【10】的n步actor/critic在线训练中的更新不同,而预期更新和训练方式是更稳定,更高效。此外,可以在该集中式价值网络上建立多个agent之间的有效协作。
Policy Context Embedding.
通过基于上下文屏蔽可用的动作空间来实现协作。在每个时间步上,地理环境都由等式 [ G t , g j ] k [G_{t,g_{j}}]_{k} [Gt,gj]k给出,并且协作环境是根据价值网络输出来计算的:
[ G t , g j ] k = { 1 i f V ( s t , g i ) > = V ( s t , g j ) , 0 o t h e r w i s e , [G_{t,g_{j}}]_{k} = \begin{cases} 1 \qquad \qquad if \ V(s_{t},g_{i})>=V(s_{t},g_{j}),\\ 0 \qquad \qquad otherwise, \end{cases} [Gt,gj]k={1if V(st,gi)>=V(st,gj),0otherwise,
其中,向量 C t , g j C_{t,g_{j}} Ct,gj的第k个元素与第k个动作的概率 π ( a t i = k ∣ s t i ) π(a_{t}^{i}=k|s_{t}^{i}) π(ati=k∣sti)相关联。让 P ( s t i ) ∈ R > 0 7 P(s_{t}^{i})∈R_{>0}^{7} P(sti)∈R>07定义用于在状态 s t i s_{t}^{i} sti条件下第 i i i个agent的来自policy网络输出的原始的logits.让 q v a l i d ( s t i ) = P ( s t i ) ∗ C t , g j ∗ G g j q_{valid}(s_{t}^{i})=P(s_{t}^{i})*C_{t,g_{j}}*G_{g_{j}} qvalid(sti)=P(sti)∗Ct,gj∗Ggj表示在网格 g j g_{j} gj上同时来考虑了agent i i i的地理环境协作环境的有效logits,其中 ∗ * ∗表示元素级别的乘法(element-wise multiplication).为了获得有效的masking,将输出logits P ( s t i ) P(s_{t}^{i}) P(sti)约束为正值。在网格 g j g_{j} gj的所有agent的有效动作的概率为:
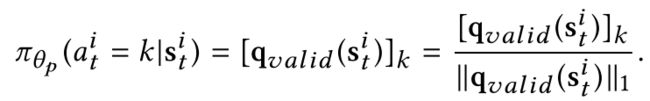
policy 的梯度可以被写作:
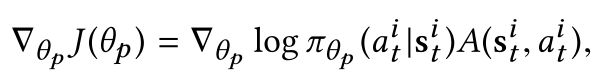
其中, θ p θ_{p} θp表示policy网络的参数,advantage A ( s t i , a t i ) A(s_{t}^{i},a_{t}^{i}) A(sti,ati) 由下面公式计算:
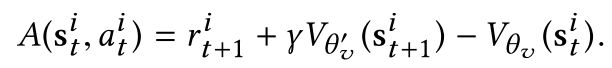
具体细节在算法4中给出。
图2给出了contextual multi-agent actor-critic的解释。左侧部分显示了基于集中式价值网络输出的分散执行协作。右侧部分说明了将上下文嵌入策略网络。

另外,用于cDQN的 ϵ-greedy policy的见算法1,cDQN算法见算法2, Contextual Multi-agent Actor-Critic Policy forward见算法3.




【0】Lin K, Zhao R, Xu Z, et al. Efficient Large-Scale Fleet Management via Multi-Agent Deep Reinforcement Learning[C]. knowledge discovery and data mining, 2018: 1774-1783.
【1】Z Li, Y Hong, and Z Zhang. 2016. Do on-demand Ride-Sharing Services Affect Traffic Congestion? Evidence from Uber Entry. Technical Report. Working paper, available at SSRN: https://ssrn. com/abstract= 2838043.
【2】Richard S Sutton and Andrew G Barto. 1998. Reinforcement learning: An intro-
duction. Vol. 1. MIT press Cambridge.
【3】Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529–533.
【4】David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. 2017. Mastering the game of go without human knowledge. Nature 550, 7676 (2017), 354.
【5】Lucian Busoniu, Robert Babuska, and Bart De Schutter. 2008. A comprehensive survey of multiagent reinforcement learning. IEEE Transactions on Systems, Man, And Cybernetics-Part C: Applications and Reviews, 38 (2), 2008 (2008).
【6】Ardi Tampuu, Tambet Matiisen, Dorian Kodelja, Ilya Kuzovkin, Kristjan Korjus, Juhan Aru, Jaan Aru, and Raul Vicente. 2017. Multiagent cooperation and com- petition with deep reinforcement learning. PloS one 12, 4 (2017), e0172395.
【7】Ming Tan. 1993. Multi-agent reinforcement learning: Independent vs. cooperative agents. In ICML. 330–337.
【8】Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529–533.
【9】Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529–533.
【10】Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Tim- othy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 2016. Asyn-chronous methods for deep reinforcement learning. In ICML. 1928–1937.