Flink on yarn部署及任务提交
文章目录
- 1. 完成hadoop本地配置后启动
- 2. flink提交作业到yarn的两种方式
- 2.1 Flink ON Yarn启动流程
- 2.2 Flink YARN Session
- 2.2 Run a single Flink job on YARN
Hadoop单机yarn配置可参考博客,除了里面提到的./start-yarn.sh外,也可以使用./start-all.sh。
1. 完成hadoop本地配置后启动
# yarn方式启动,也可以使用 ./start-yarn.sh
~/software/hadoop-2.6.0-cdh5.15.1/sbin ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
20/08/03 17:34:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
Password:
localhost: starting namenode, logging to /Users/zhangbin19/software/hadoop-2.6.0-cdh5.15.1/logs/hadoop-zhangbin19-namenode-bj-m-218760a.local.out
Password:
localhost: starting datanode, logging to /Users/zhangbin19/software/hadoop-2.6.0-cdh5.15.1/logs/hadoop-zhangbin19-datanode-bj-m-218760a.local.out
Starting secondary namenodes [0.0.0.0]
Password:
0.0.0.0: starting secondarynamenode, logging to /Users/zhangbin19/software/hadoop-2.6.0-cdh5.15.1/logs/hadoop-zhangbin19-secondarynamenode-bj-m-218760a.local.out
20/08/03 17:34:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /Users/zhangbin19/software/hadoop-2.6.0-cdh5.15.1/logs/yarn-zhangbin19-resourcemanager-bj-m-218760a.local.out
Password:
localhost: starting nodemanager, logging to /Users/zhangbin19/software/hadoop-2.6.0-cdh5.15.1/logs/yarn-zhangbin19-nodemanager-bj-m-218760a.local.out
# 查看进行 可以发现均已启动
~/software/hadoop-2.6.0-cdh5.15.1/sbin jps
11892 SecondaryNameNode
12069 NodeManager
12789 Jps
11798 DataNode
11992 ResourceManager
11723 NameNode
1069
11085 Launcher
2. flink提交作业到yarn的两种方式
强烈建议参考官方文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/yarn_setup.html
2.1 Flink ON Yarn启动流程
两种模式:
- Job模式(小Session模式)
- Session模式
Job模式
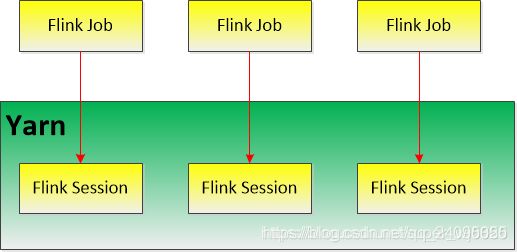
每个Flink Job单独在yarn上声明一个Flink集群,即提交一次,生成一个Yarn-Session。
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar ...
Session模式

常驻Session,yarn集群中维护Flink Master,即一个yarn application master,运行多个job。
启动任务之前需要先启动一个一直运行的Flink集群:
#1启动一个一直运行的flink集群
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 -d
#2 附着到一个已存在的flink yarn session
./bin/yarn-session.sh -id application_1463870264508_0029
总览yarn提交流程(基于1.8)
Flink架构
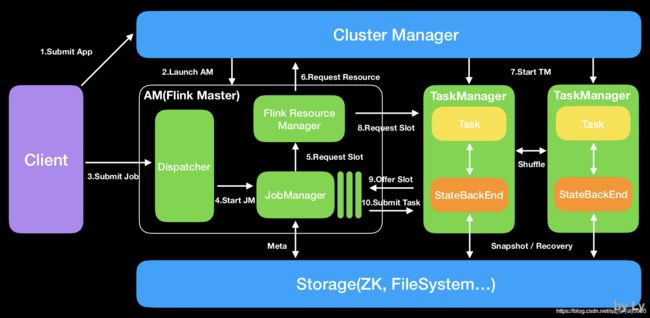
Flink基本组件
-
Dispatcher(Application Master)提供REST接口来接收client的application提交,它负责启动JM和提交application,同时运行Web UI。
-
ResourceManager:一般是Yarn,当TM有空闲的slot就会告诉JM,没有足够的slot也会启动新的TM。kill掉长时间空闲的TM。
-
JobManager :接受application,包含StreamGraph(DAG)、JobGraph(logical dataflow graph,已经进过优化,如task chain)和JAR,将JobGraph转化为ExecutionGraph(physical dataflow graph,并行化),包含可以并发执行的tasks。其他工作类似Spark driver,如向RM申请资源、schedule tasks、保存作业的元数据,如checkpoints。如今JM可分为JobMaster和ResourceManager(和下面的不同),分别负责任务和资源,在Session模式下启动多个job就会有多个JobMaster。
-
TaskManager:类似Spark的executor,会跑多个线程的task、数据缓存与交换。
Flink On Yarn
Flink1.7之后,新增了Dispatcher,在on yarn流程上略有却别
Without dispatcher

- 当开始一个新的Flink yarn 会话时,客户端首先检查所请求的资源(containers和内存)是否可用。如果资源够用,之后,上传一个jar包,包含Flink和HDFS的配置。
- 客户端向yarn resource manager发送请求,申请一个yarn container去启动ApplicationMaster。
- yarn resource manager会在nodemanager上分配一个container,去启动ApplicationMaster
- yarn nodemanager会将配置文件和jar包下载到对应的container中,进行container容器的初始化。
- 初始化完成后,ApplicationMaster构建完成。ApplicationMaster会为TaskManagers生成新的Flink配置文件(使得TaskManagers根据配置文件去连接到JobManager),配置文件会上传到HDFS。
- ApplicationMaster开始为该Flink应用的TaskManagers分配containers,这个过程会从HDFS上下载jar和配置文件(此处的配置文件是AM修改过的,包含了JobManager的一些信息,比如说JobManager的地址)
- 一旦上面的步骤完成,Flink已经建立并准备好接受jobs。
With dispatcher

Dispatcher组件负责接收作业提交,持久化它们,生成JobManagers以执行作业并在Master故障时恢复它们。此外,它知道Flink会话群集的状态。
引入Dispatcher是因为:
- 某些集群管理器需要一个集中的作业生成和监视实例
- 它包含独立JobManager的角色,等待提交作业
更多flink on yarn启动流程相关说明推荐此博客:https://blog.csdn.net/super_wj0820/article/details/90726768
2.2 Flink YARN Session
第一步中我们已经完成了hadoop yarn集群启动,接下来我们以session的方式启动提交一个flink作业。
首先启动一个session:
./bin/yarn-session.sh -n 1 -jm 1024m -tm 1024m -d
启动一个flink demo作业(flink官方文档案例):
# 拉取输入文本,输入流从此获取
wget -O LICENSE-2.0.txt http://www.apache.org/licenses/LICENSE-2.0.txt
# 推动到hdfs
hadoop fs -copyFromLocal LICENSE-2.0.txt /
# 启动demo作业
~/software/flink-1.10.1 ./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs://localhost:8020/LICENSE-2.0.txt --output hdfs://localhost:8020/wordcount-result.txt
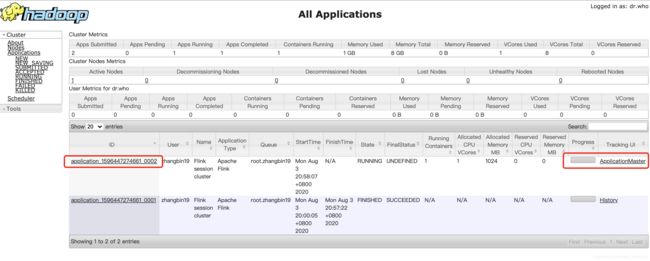
http://localhost:8088/cluster 中可查看yarn中的作业。
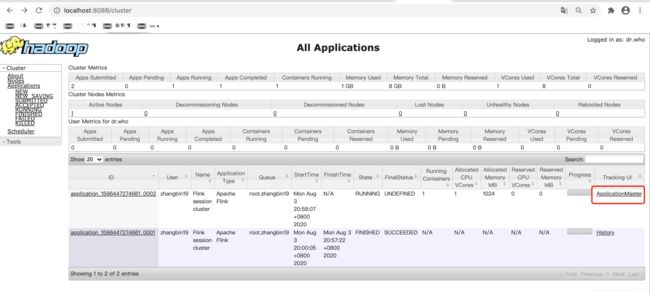
点击AM进入Flink UI:
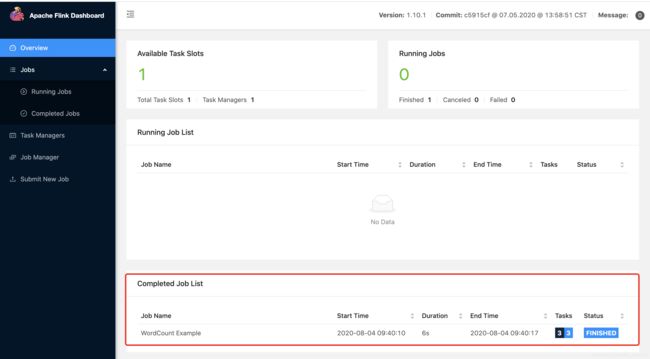
以为是一个批处理的Demo,所以很快就完成了。
可以查看hdfs文件中的输出结果:
hdfs dfs -text /wordcount-result.txt
第一种方式执行完毕。
测试第二种Run a single Flink job on YARN之前记得先关掉之前启动的yarn-session。
# 通过yarn application -kill +appId 杀死session任务
~/software/flink-1.10.1 yarn application -kill application_1596447274661_0002
20/08/04 09:53:05 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
20/08/04 09:53:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Killing application application_1596447274661_0002
20/08/04 09:53:05 INFO impl.YarnClientImpl: Killed application application_1596447274661_0002
2.2 Run a single Flink job on YARN
通过添加-m yarn-cluster作为单个flink任务提交到yarn集群中
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar \
--input hdfs://localhost:8020/LICENSE-2.0.txt --output hdfs://localhost:8020/wordcount-result1.txt
注意因为之前已经产生了一个wordcount-result.txt文件,这里要改个名字,不然会报错。
如下图003为初次提交成功的任务,004为因为要生成的输出信息txt已存在执行失败的任务。
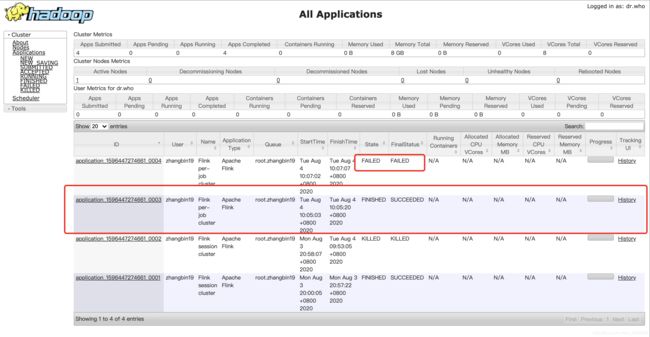
因为批处理Demo程序很小所以这里运行很快,连Flink UI都没来的及进去就从执行时的ApplicationMaster变成执行结束的History状态了。。如果执行大一点的批处理任务或者流处理任务就可以很方便的进到Flink UI查看作业运行情况了。