From Import AI
先给大家拜个早年了。
加密货币AI的黎明:强化学习+区块链?

...为什么加密可能是基于RL-交易系统的终极试验场,以及为什么这将需要大量的基础研究的突破性成功...
在过去的几个月里, AI 大牛 Denny Britz 一直在想, 什么样的 AI 技术可以应用于学习有利可图的加密货币呢。
“这类似于多人游戏的训练, 如 DotA, 同时还有很多类似研究。我对交易一无所知, 但在过去的几个月里一直在研究这个领域的项目。 "他写道。
深度强化学习与交易:
Britz 是热衷于使用深度强化学习交易,因为它可以进一步从精确的交易策略中去除人这个因素,而在市场中获利。此外,它有希望能在更短的时间内比人类更快地采取行动。美中不足的是,需要建立对你想要进行交易的市场的模拟器,并设法使这模拟器在与真实数据有相同模式。那么之后就可以将学到的政策转移到一个真正的市场,祈祷你的模型没有过拟合,
这些都不简单。而且还得升级AI可以模拟其他市场参与者,以及行为对决策的影响,这也是个大难题
阅读更多:Introduction to Learning to Trade with ReinforcementLearning
DeepMind的IMPALA告诉我们,迁移学习已经开始初现实力了:

具有相同参数的一组强化学习AI,在一大堆计算机的帮组下完成了众多任务...
DeepMind最近发布了关于IMPALA的详细信息。IMPALA是一个可以完成“DeepMind Lab”一组30个的3D任务,以及57个Atari游戏的强化学习AI。它还展示了一些迁移学习方面的能力,这意味着它能用解决一个任务所获得的知识来解决另一个任务,从而提高算法的数据效率。
技术:
Weighted Actor-Learner Architecture(IMPALA)将众多子代理(Actor 行动者)扩展到数以千计的机器上,这些代理将它们的体验(状态,动作和奖励顺序)再传回到集中式学习者。在实际训练中,还通过规范化个体代理和元代理的学习来实现了一些有趣的技巧,比如通过一种称为V-trace的新的非关闭策略的行为者 - 评论者算法来避免时间消退问题。结果是一种比传统的RL算法(如A2C)有更多数据效率的算法。
数据中心规模的AI训练:
如果你不认为计算是AI研究的战略决定因素,那么就请看看这篇文章吧:IMPALA通过其大规模分布式实施达到每秒250,000帧的吞吐量,给每个IMPALA代理就分配了500 CPUS加1个GPU。 DeepMind指出,这种系统每天可以实现210亿帧的吞吐量。
迁移学习:
IMPALA代理可以同时接受多个任务的训练,在完整的Atari-57数据集上获得高达59.7%这样人类表现的中间分数,大概与在单一游戏训练的简单A3C代理的表现相当。在IMPALA迁移学习方法能够与微调的单一环境实现(它们的表现通常远远超出人类的表现)相抗衡之前,显然还有一段路要走,但这种迹象是让人高兴的。同时,当他们在DeepMind Lab(该公司基于Quake的3D测试平台)的30套环境中进行测试时也显示出类似的很有效的迁移学习特性。
为什么重要:
大型计算机类似于大型望远镜,让研究人员能够探索研究的外部界限,并迅速传遍整个科学研究领域。 IMPALA就是这样的一种当组织有很大的运算资源时,可以快速进行设计的算法。 DeepMind写道:“以这样的规模规模来进行训练可以快速地试验新想法,并开辟未探索的机会。”
阅读更多:IMPALA: Scalable Distributed Deep-RL with ImportanceWeighted Actor-Learner Architectures (Arxiv)
iDoctor的兴起:研究人员利用Apple Watch app来预测医疗状况:
...与苹果手表配对的消费者应用程序使大规模的研究成为可能......
至今为止,深度学习对大量数据的渴求,使得在医疗环境中应用它很棘手。原因是缺乏研究者有权限访问和测试的大规模的数据集。现状可能很快就会改变,因为研究人员找出如何利用现有可用的医疗自动测量记录传导数据,通过消费者的设备来升级数据集,获得比以的更大数量级的医疗数据集,并且以这种方式来利用现有广泛部署的软件。
加州大学旧金山分校医学部利用心率app Cardiogram 和Apple Watch的新研究。使用 Apple Wach 采集的数据,与Cardiogram app配对,训练的AI系统,称为“DeepHeart”。有14000名参与者献出数据,能更好地预测糖尿病,高血压,睡眠呼吸暂停和高胆固醇等疾病的病情。
如何工作:
DeepHeart 通过一组神经网络(convnets 和 resnets)摄取数据。该神经网络将数据喂进双向LSTMs,学会模拟与传感器数据关联的较长时间模式。并且实验两种形式的模型来提取数据,以提高系统的采样效率。
结果:
比基于其他人工智能方法,如多层感知,随机森林,决策树,支持向量机和逻辑回归,Deepheart获得更高的预测准确率。然而,我们没有能看到与医生的比较,所以这些AI技术如何与广泛部署的人类系统相比并不容易。研究人员报告说,预训练使他们能够进一步提高数据效率。下一步,研究人员希望探索像Clockwork RNNs 和PhaseLSTMs 和 Gaussian Process RNNs 这样的技术,通过建模研究真正的大量数据(比如每个测试人员一年的数据)来研究如何完善这些系统。
重要性:
智能手机的崛起和通用传感器的成本降低,使世界高效运转,让人类和日常接触的物品能产生更大量的不精确的信息。迄今证明,深度学习被证明是一种有效的工具,可以大量使用不精确的数据,期待更多。
阅读更多:
DeepHeart: Semi-Supervised Sequence Learning forCardiovascular Risk Prediction (Arxiv).
中药处方与舌头图像:
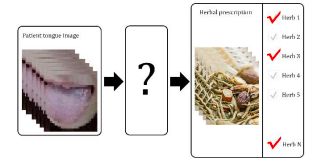
...不同的文化意味着不同的治疗,这意味着不同的AI系统...
研究人员利用标准化的图像分类技术来创建预测系统,能从舌头的图像预测中药处方。这非常有趣,,这非常有趣,因为它证明了人工智能技术在中国的应用广度和步伐,人们为这些系统提供数据。
数据集:
566种不同种类的草药及其关联的中国中药处方,超过50名志愿者提供的9585张舌头照片。
更多:Automatic construction of Chinese herbal prescriptionfrom tongue image via convolution networks and auxiliary latent therapy topics(Arxiv).
Google研究人员:在进化算法与强化学习算法之间的战斗中,目前进化获胜:

...需要一个整体数据中心来建立一个模型...
去年,谷歌研究人员引起了轰动,他们发现可以使用强化学习(RL)来让计算机学习如何设计更好的图像分类器。大约在同一时间,其他的研究人员发现,你可以使用进化算法做同样的事情。但是,谁更好呢?谷歌研究人员利用其巨(tu)大(hao)计算资源,揭示了这个隐藏在庞大计算尺度里的答案。
结果:
规则化的进化方法(绰号:'AmoebaNet')产生了一个关于CIFAR-10图像分类的新技术,与ImageNet上的RL方法相当,并且在移动设备(即轻量级)ImageNet上性能略高。在“小规模”单个CPU进行测试时,进化算法要么优于或等于RL的表现。在训练的最初阶段,进化算法也比RL提高了准确性。对于大规模实验(每个实验450个GPU(!!!)),他们发现随着进化趋向更高的精度,进化算法和RL系统的效果差不多。 此外,进化算法使得计算的效率大大高于RL变体,且具有更高的精度。
方法:
研究人员在设计一个由两个基本模块组成的网络时测试RL和进化算法:一个正常单元和一个抑制单元,它们以前馈模式叠加形成一个图像分类器。他们测试了两种变种:非正规化(去除每个时间段性能最差的网络)和规则化(去除网络中时间最早的网络)。 对于RL,他们使用TRPO来学习设计新的架构,他们在小范围内测试了这个设计(可以运行的实验 一个CPU)以及大型计算机(每个450个GPU,运行7天左右)。
意义:
这一切实践中的意味着三重意义:
- 无论谁拥有最大的计算机,都可以进行最大的实验来阐明可能有用的数据点,以开发更好的人工智能系统理论(例如,这里的观点是,RL和进化算法都收敛于类似的准确性)。
- 人工智能研究正在分化为“低计算”和“高计算”的领域,只有少数玩家能够运行真正的大型(约450个gpu)实验。
- 双重用途: 随着人工智能系统变得更有能力,它们也变得更加危险。像这样的实验表明,非常大的计算操作人员将能够更早地探索潜在危险,让他们发出警告信号,这意味着你可以尽早地不用踩坑了。
更多: Regularized Evolution for Image Classifier ArchitectureSearch (Arxiv).
我开车像不像老司机哇?研究人员做出了可泛化性(微弱)的注视预测系统:

......弄清楚驾驶员正在看什么,会影响到驾驶员的安全性和注意力......
现代AI最有用的(也是潜在的危险)方面之一是,用一个现成的数据集非常容易,只需要用一个特定领域的数据稍微增加它,就可以解决原始数据集没考虑到的新任务了。加利福尼亚大学圣地亚哥分校的新研究就是这样,该研究提出通过使用ImageNet和新数据的组合来更好地预测驾驶员注视的位置。由此产生的注视预测系统击败了其他基线,并在其训练集之外也能进行有效泛化。
数据集:
为了收集研究的原始数据集,研究人员在安装了两台车内摄像机和一台车外摄像机;内部的两个摄像头从不同的角度捕捉驾驶员的脸部,外部的摄像头则捕捉道路的情况。他们还为驾驶员可能注视的七个不同区域手动进行了标注,提供了主要的训练数据。这个数据集由十一个长时间驾驶组成,由是十个不同的人分别驾驶两辆不同的汽车,全部使用相同的相机设置。
技术:
研究人员提出了一个两阶段的流程,包括了一个输入预处理流程。 它会执行脸部检测,然后通过四种不同的技术进一步分辨。这些图像然后被送到第二阶段,该阶段由四种不同的神经网络方法(AlexNet,VGG,ResNet和SqueezeNet)中的一种来进行微调。
结果:
研究人员用一种最先进的基线(具有手工设计特征的随机森林分类器)来与他们的方法进行对比。并发现他们的方法,在预测注视区域中的哪一个(向前,右侧,左侧,中央仪表板,后视镜,速度表,闭眼/睁眼)时,驾取得了更好的表现。
研究人员还试图复制另一种使用神经网络的最先进基线。该系统使用来自每段驾驶数据前70%进行训练,接下来的15%用于验证,最后15%用于测试。换句话说,该系统在相同的人员和汽车训练,并且(取决于外部地形的变化程度)类似的背景,作为随后测试的内容。研究人员得到了“98.7%的非常高的准确性”,当在不同段的驾驶数据进行测试时,准确度下降到82.5%,这清楚地表明,通过单段驾驶来训练会过拟合。
泛化:
研究人员在一个完全独立的数据集(哥伦比亚凝视数据集)上测试了他们训练好的模型。这个数据集适用于不同的领域,其中没有车,而是坐着很多人,被要求查看对面墙上的特定点。
研究人员从先前的数据集中取得了最好的模型,并将其应用于新数据并测试了其预测能力。他们检测到了一定程度的泛化,能够正确预测像凝视和定向这样的基本特征。这种(轻微)泛化是另一个迹象,表明他们为自己的数据集采用的数据集和测试制度有助于泛化。
阅读更多:Driver Gaze Zone Estimation using Convolutional NeuralNetworks: A General Framework and Ablative Analysis (Arxiv)
研究人员发布了语言基准测试工具Texygen:
...有着多种开源语言模型的评估和测试平台...
上海交通大学和伦敦大学学院的研究人员最近发布了Texygen,由Tensorflow库实现的文本基准测试平台。 Texygen包括一系列语言模型的开源实现,包括Vanilla MLE,以及基于GAN的方法(SeqGAN,MaliGAN,RankGAN,TextGAN,GSGAN,LeakGAN)。Texygen包含了多种不同的评估方法,包括BLEU以及NLL-oracle等新技术。
该平台还可以用合成数据和真实数据一起训练,这样研究人员可以在验证自己想法同时而无需去抓去庞大的数据集。
为什么重要:
语言建模在深度学习中是一个蓬勃发展的领域,所以用另一个系统来测试新的方法将进一步帮助研究人员评估自己对整个领域的贡献。更好更广泛的基线可以更容易看到真正的创新。
为什么它也可能无关紧要:
所有这里提到的技巧都只涉及到很少的语言学相关的隐结构图,所以尽管它们可能具有令人印象深刻的词语认知功能。但可能要么是大量数据,要么是强大的模型假设造成的。
阅读更多:Texygen: A Benchmarking Platform for Text GenerationModels (Arxiv).