mysql innodb索引原理
聚簇索引
聚集索引就是按照每张表的主键顺序构造一颗B+树。
查询优化器倾向于采用聚集索引,因为聚集索引能在叶子结点直接找到数据,并且因为定义了数据的逻辑顺序,能特别快的访问针对范围值的查询。
在Innodb中,聚簇索引默认就是主键索引。如果没有主键,则按照下列规则来建聚簇索引:
1:没有主键时,会用一个非空并且唯一的索引列做为主键,成为此表的聚簇索引;
2:如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
我们知道了innodb引擎索引使用了B+树结构,那么为什么不是其他类型树结构,例如二叉树呢?
计算机在存储数据的时候文件系统的最小单元是块,一个块的大小是4k,InnoDB存储引擎也有自己的最小储存单元—页(Page),一个页的大小是16K。文件系统中一个文件大小只有1个字节,但不得不占磁盘上4KB的空间。同理,innodb的所有数据文件的大小始终都是16384(16k)的整数倍。
所以在MySQL中,存放索引的一个块节点占16k,mysql每次IO操作会利用系统的预读能力一次加载16K。这样,如果这一个节点只放1个索引值是非常浪费的,因为一次IO只能获取一个索引值,所以不能使用二叉树。
所以在MySQL中,存放索引的一个块节点占16k,mysql每次IO操作会利用系统的预读能力一次加载16K。这样,如果这一个节点只放1个索引值是非常浪费的,因为一次IO只能获取一个索引值,所以不能使用二叉树。
B树和B+树的区别在于,B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
非聚集索引
也称为非聚集索引,其叶子节点不包含行记录的全部数据,叶子结点除了包含键值以外,每个叶子结点中的索引行还包含一个书签,该书签就是相应行的聚集索引键。
如下图可以表示辅助索引和聚集索引的关系(图片源自网络,看大概意思即可):
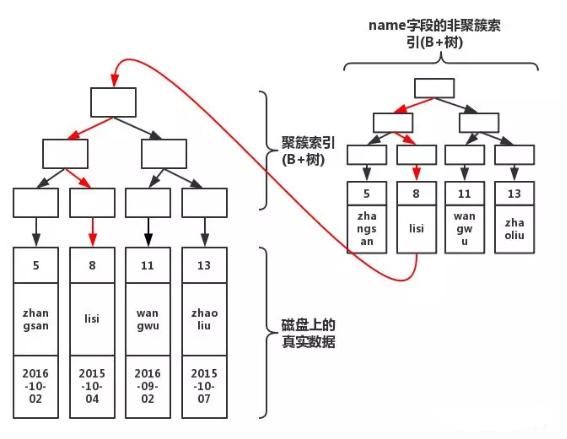
当通过辅助索引来寻找数据时,innodb存储引擎会通过辅助索引叶子节点获得只想主键索引的主键,既然后再通过主键索引找到完整的行记录。
联合索引
联合索引是指对表上的多个列进行索引。联合索引也是一颗B+树,不同的是联合索引的键值数量不是1,而是大于等于2。。
例如有user表,字段为id,age,name,现发现如下两条sql使用频率最多:
Select * from user where age = ? ;
Select * from user where age = ? and name = ?;
这时候不需要为age和name单独建两个索引,只需要建如下一个联合索引即可:
create index idx_age_name on user(age, name)
联合索引的另一个好处已经对第二个键值进行了排序处理,有时候可以避免多一次的排序操作。
覆盖索引
覆盖索引,即从辅助索引中就可以得到查询所需要的所有字段值,而不需要查询聚集索引中的记录。覆盖索引的好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。
例如上面有联合索引(age,name),如果如下:
select age,name from user where age=?
就能使用覆盖索引了。
覆盖索引的另一个好处是对于统计问题,例如:
select count(*) from user
innodb存储引擎并不会选择通过查询聚集索引来进行统计。由于user表上还有辅助索引,而辅助索引远小于聚集索引,选择辅助索引可以减少IO操作。
索引只建合适的,不建多余的
因为每当增删数据时,B+树都要进行调整,如果建立多个索引,多个B+树都要进行调整,而树越多、结构越庞大,这个调整越是耗时耗资源。如果减少了这些不必要的索引,磁盘的使用率可能会大大降低。
索引列的数据长度能少则少
索引数据长度越小,每个块中存储的索引数量越多,一次IO获取的值更多。
Where 条件中in和or可以使用索引, not in 和 <>操作无法使用索引;
多用指定列查询,只返回自己想到的数据列,少用select *;
联合索引中如果不是按照索引最左列开始查找,无法使用索引;最左匹配原则;
联合索引中精确匹配最左前列并范围匹配另外一列可以用到索引;
联合索引中如果查询中有某个列的范围查询,则其右边的所有列都无法使用索