数据结构基础(线性表+栈+队列+树+图)
线性表:顺序表示+链式表示
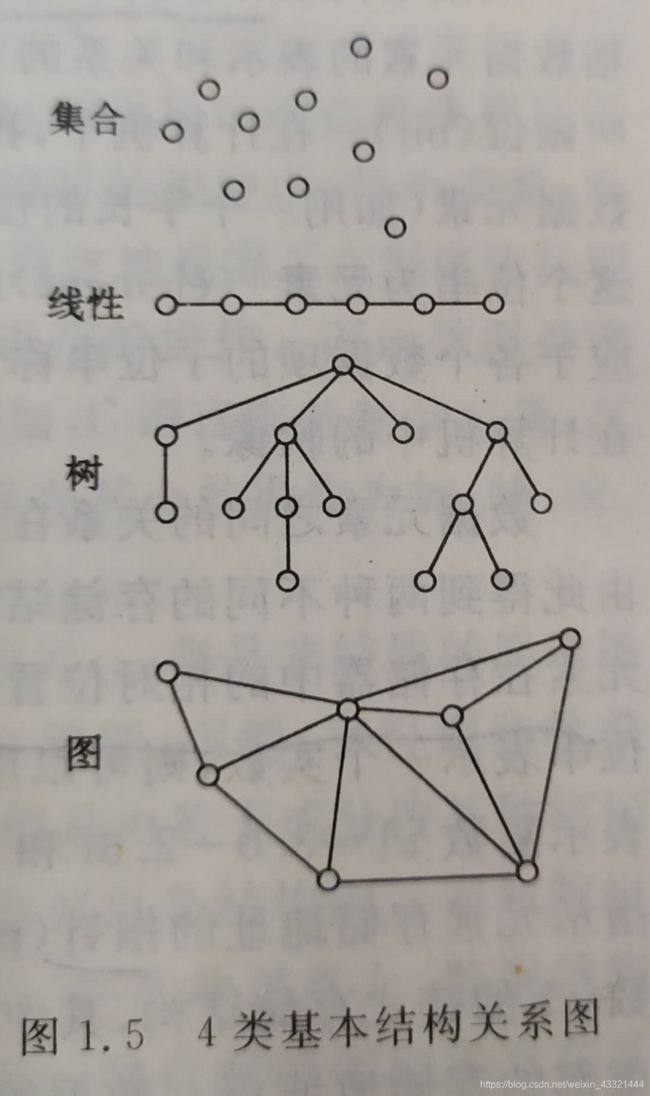
一、根据数据元素之间分为4类基本结构:
(1)集合(2)线性结构(3)树形结构(4)图状结构或网状结构
typedef int Status;
二、双向链表中插入一个结点时指针的变化情况:
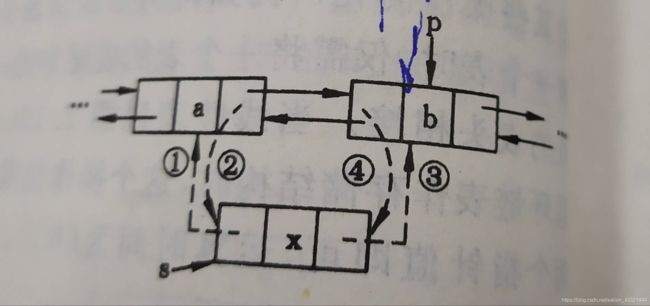
s -> prior = p -> prior;
p -> proir -> next = s;
s -> next = p;
p -> proir = s;
三、栈的应用:表达式求值
- 计算过程:expression = 3*(7-2) operandStack, operatorStack;
- 读到字符0-9,operandStack进栈
- 读到±*/ && operatorStack为空,operatorStack进栈
- 读到 “(” || 优先级比栈顶优先级高的字符,operatorStack进栈
- 读到优先级不如栈顶优先级的,计算
- 读到 ”)“ 并且栈顶是 ”(“,operatorStack出栈
- 读到字符串末尾 && operatorStack为空,计算结束
- operandStack.top()就是计算结果。
#include
#include
#include
#include "ImprovedStack.h"
int priority(char c)
{
int k;
switch (c)
{
case '*':k = 2; break;
case '/':k = 2; break;
case '+':k = 1; break;
case '-':k = 1; break;
case '(':k = 0; break;
case ')':k = 0; break;
default:k = -1; break;
}
return k;
}
void processAndOperator(Stack& operandStack,Stack& operatorStack){
double result;
int op1=operandStack.pop();
int op2=operandStack.pop();
switch(operatorStack.pop()){
case '+':
result=op1+op2;
cout<priority(operatorStack.peek())))
{
operatorStack.push(c);
i++;
}
else if(c==')'&&operatorStack.peek()=='(')
{
operatorStack.pop();
i++;
}
else if(priority(c)<=priority(operatorStack.peek()))
{
processAndOperator(operandStack,operatorStack);
}
}
return operandStack.pop();
}
int main(){
string expression;
cout<<"Enter an expression: ";
while(getline(cin,expression)){
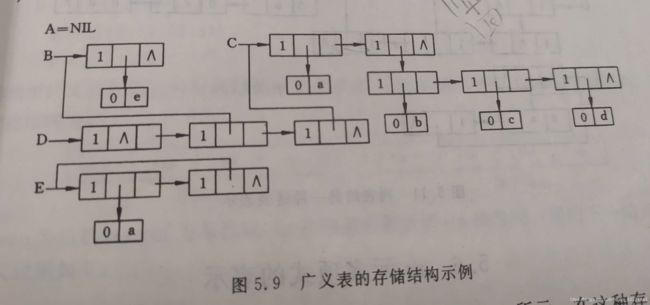
cout< 四、广义表
- LS = (a1, a2, a3,…an) 第一个元素a1是表头,其余元素组成的表(a2, a3,…an)是LS的表尾。
- E= (a, E)这是一个递归的表,长度是2。
例题:
(1) A = ();
(2) B =(e)
(3) C = (a,(b,c,d))
(4) D = (A ,B,C)
(5) E =(a,(E))
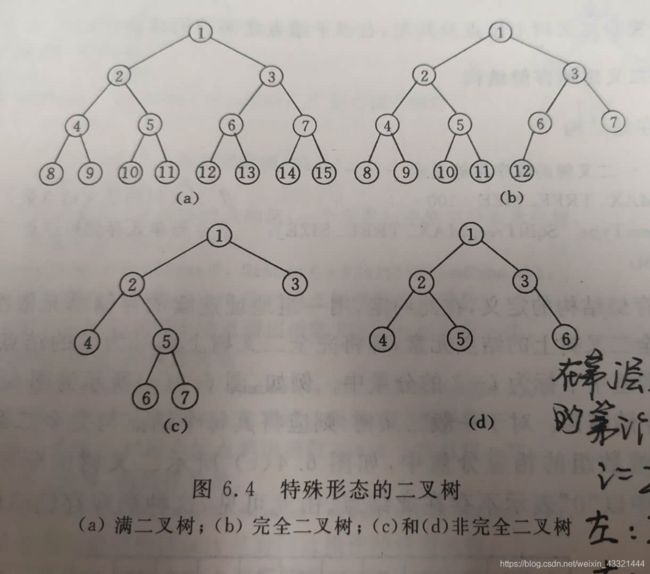
五、树和二叉树
- 二叉树的性质:
- 在二叉树第 i 层最多有2的(i-1)次方个结点。
- 深度为k的二叉树最多有2的k次方-1个结点。
- 任何一颗二叉树T,如果其终端结点数是n0,度为2的结点数为n2,则n0 = n2 + 1;
- 满二叉树:一颗深度为k且有2的k次方-1个结点的二叉树
- 完全二叉树:深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1到n的结点一一对应,称为完全二叉树。
- 具有n个结点的完全二叉树的深度:Log2(n)(以2为底n的对数)向下取整+1;
六、二叉树的遍历
先序遍历:根,左子树,右子树
中序遍历:左子树,根,右子树
后序遍历:左子树,右子树,根
按层遍历:从根开始,依次向下,对于每一层从左向右遍历。
二叉树的非递归遍历:借助栈来实现
(1) 非递归先根遍历二叉树
- 当栈不为空 || 当前节点不为空,执行操作:
- 从根节点开始,输出当前结点;
- 依次输出树中最左端的节点,并入栈。
- 当节点为空停止入栈,取栈顶元素为当前节点并出栈,如果当前节点有右子树,则遍历其右子树。
void PreorderPrint(SearchBTree T) // 先序根(序)遍历二叉树并打印出结点值
{
if (T == nullptr)
{
cout << "Empty tree!";
exit(1);
}
Stack S = new StackNode; // 借助栈来实现
initStack(S);
TreeNode* pT = T; // 创建临时结点指向根节点
while (pT || !isEmpty(S)) // 当结点不为空或者栈不为空执行循环
{
if (pT) // 当pT不为空
{
Push(S, pT); // pT入栈
cout << pT->data << " "; // 打印当前结点
pT = pT->left; // pT移动指向其左孩子
}
else
{ // pT为空,则获取栈顶元素,并出栈
pT = getTop(S);
Pop(S); // 若pT为空表示左子树的左孩子全部遍历完,依次出栈
pT = pT->right; // 当左孩子及根结点遍历完之后,开始遍历其右子树
}
}
cout << endl;
delete S;
}
(2)非递归中根遍历二叉树
- 当栈不为空 || 当前节点为不为空,执行操作:
- 依次访问左结点入栈,但不输出。当节点为空,则停止入栈。
- 访问栈顶元素作为当前节点并出栈,如果当前节点有右子树,则遍历访问其右子树,如果右子树为空,则又进入循环,输出栈顶元素并出栈,再获取右子树。
void InorderPrint(SearchBTree T) // 中根(序)遍历二叉树并打印出结点值
{
if (T == nullptr)
{
cout << "Empty tree!";
exit(1);
}
Stack S = new StackNode; // 借助栈来实现
initStack(S);
TreeNode* pT = T; // 创建临时结点指向根节点
while (pT || !isEmpty(S)) // 当结点不为空或者栈不为空执行循环
{
if (pT) // 当pT不为空
{
Push(S, pT); // pT入栈
pT = pT->left; // pT移动指向其左孩子
}
else
{ // pT为空,则
pT = getTop(S);
Pop(S); cout << pT->data << " "; // 若pT为空表示左子树的左孩子全部遍历完,依次出栈并打印
pT = pT->right; // 当左孩子及根结点遍历完之后,开始遍历其右子树
}
}
cout << endl;
delete S;
}
(3)非递归后根遍历二叉树
- 非递归后根遍历相比前两个有点麻烦,需要引入一个中间变量标记已经访问节点。 当栈不为空或者当前节点为不为空,执行操作:
- 依次将根节点及其左子树的左端节点入栈,但不进行访问,当节点为空,停止入栈。
- 取栈顶元素作为当前节点,如果当前节点的右孩子(右子树)不为空且其右孩子不是上一次访问的节点。则当前节点变为其右子树,遍历其右子树。如果当前节点的右孩子为空或者其右孩子已经被访问,则访问当前节点,标记当前节点为已访问节点,出栈。将当前节点置为空(此时右孩子访问过了),继续取栈顶元素(为了访问根节点)。
void PostorderPrint(SearchBTree T) // 先根(序)遍历二叉树并打印出结点值
{
if (T == nullptr)
{
cout << "Empty tree!";
exit(1);
}
Stack S = new StackNode; // 借助栈来实现
initStack(S);
TreeNode* pT = T; // 创建临时结点指向根节点
TreeNode* qT = nullptr;
while (pT || !isEmpty(S)) // 当结点不为空或者栈不为空执行循环
{
if (pT) // 当pT不为空
{
Push(S, pT); // pT入栈
pT = pT->left; // pT移动指向其左孩子
}
else
{
pT = getTop(S); // 取栈顶元素作为当前结点
if (pT->right && pT->right != qT) // 若当前节点有右孩子且不是上一次已经被访问的结点
{
pT = pT->right; // 指向其右孩子
}
else
{ // 若当前结点没有右孩子或者未被访问,则
Pop(S); // 出栈
cout << pT->data << " "; // 访问当前结点的数据
qT = pT; // 令pT记录当前结点,用于稍后判断是否已经被访问过
pT = nullptr; // 将当前结点赋值为空
}
// 当左孩子及根结点遍历完之后,开始遍历其右子树
}
}
cout << endl;
delete S;
}
(4)按层遍历
- 初始时,根结点入队列
- 然后,while循环判断队列不空时,使用poll()方法获取对头结点,输出它,并把它的所有孩子结点入队列。
public void levelTraverse(BinarySearchTree tree){
levelTraverse(tree.root);
}
private void levelTraverse(BinaryNode root){
if(root == null)
return;
Queue> queue = new LinkedList<>();//层序遍历时保存结点的队列
queue.offer(root);//初始化
while(!queue.isEmpty()){
BinaryNode node = queue.poll();//获取对头元素并删除
System.out.print(node.element + " ");//访问节点
if(node.left != null)
queue.offer(node.left);
if(node.right != null)
queue.offer(node.right);
}
}
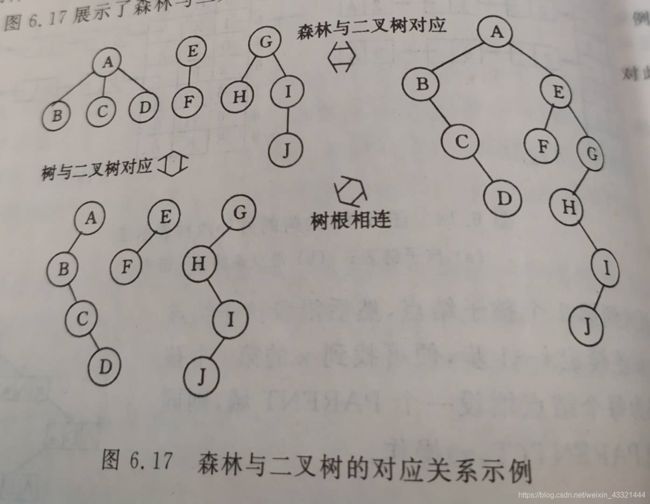
七、森林与二叉树
森林中的每棵树先变成二叉树,然后再连接起来。
八、Huffman树及其应用
- Huffman树,又称最优树,是一类带权路径长度最短的树。
- 树的路径长度:根结点到每一个结点的路径长度之和。
- 结点的带权路径长度 = 该结点到树根的路径长度 * 结点上权
- 带权路径长度WPL最小的二叉树称为最优二叉树或Huffman树
1.构造Huffman树: Huffman算法
(1)对权值进行排序,树的集合为F
(2)选择最小的两个权值作为左右子树构建一个新的二叉树,
根节点的权值是左右子树结点权值之和。
(3)删除这两棵树,将新生成的二叉树添加到F中。
(4)一直重复,(2)(3),直到F中只有一棵树为止。
Huffman编码:左0右1
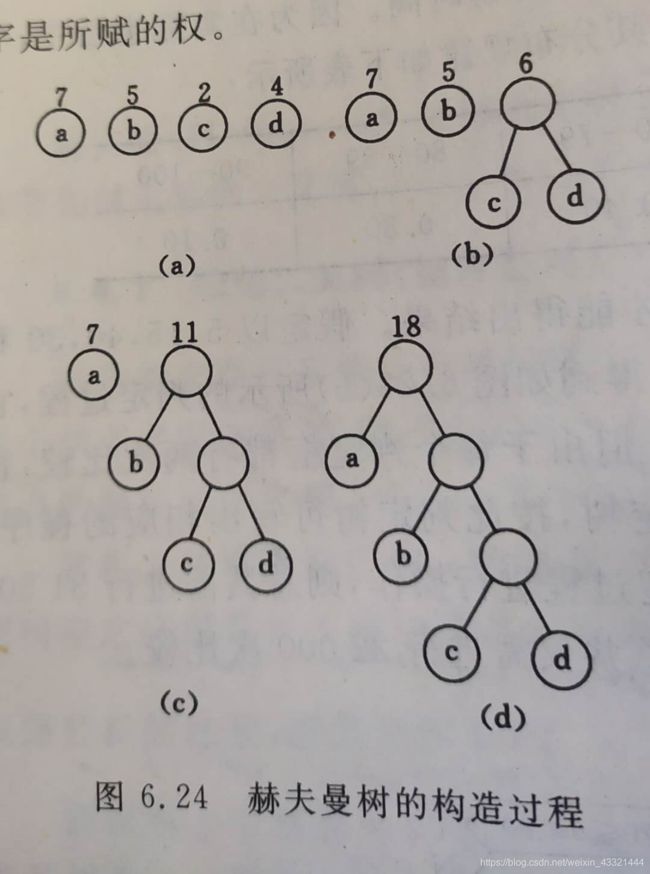
WPL = 71 + 52 + 23 + 43 = 35
九、图
1.图的存储结构:邻接矩阵+邻接表
(1)邻接矩阵
- 用两个数组分别存储数据元素(顶点)信息+数据元素之间的关系信息
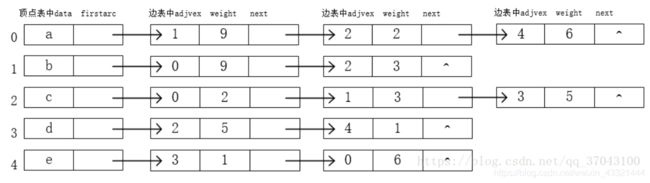
(2)邻接表
- 邻接表是图的一种链式存储结构,表结点+头结点
- 每个表结点由3个域组成,其中邻接点域(adjvex)指示与顶点vi邻接的点在图中的位置,链域(nextarc)知识下一条边或弧的结点,info存储信息,如权值等。
- 每个链表上有一个头结点,由链域(firstarc),指向链表中第一个结点,数据域(data)
头结点 表结点
2.图的遍历
(1)深度优先搜索DFS,类似于树的先根遍历。
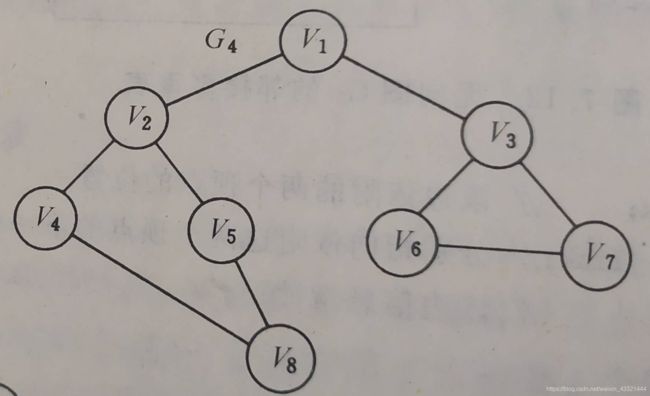
深度优先搜索(DFS):v1 -> v2 -> v4 ->v8 -> v5 -> v3 -> v6 -> v7
(2)广度优先搜索(BFS),类似于树的按层遍历的过程
广度优先搜索(BFS)序列:v1 -> v2 -> v3 -> v4 -> v5 -> v6 -> v7 -> v8
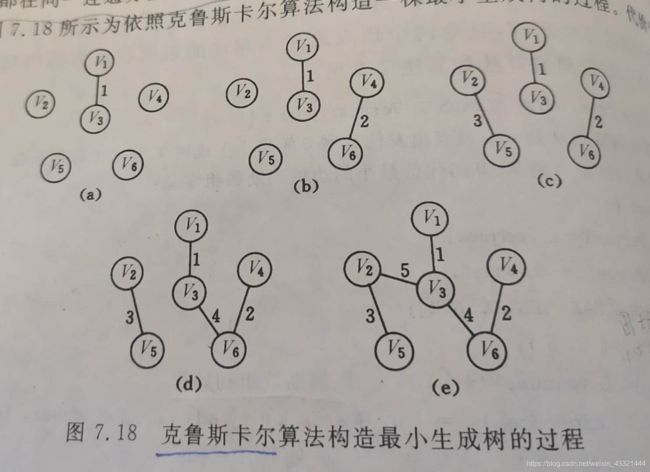
3.最小生成树
构造连接网的最小代价生成树(简称为最小生成树)问题,一颗生成树的代价就是树上各边的代价之和。Prim算法+Kruskal算法
(1)Prim算法
- N = (V,(E));TE:最小生成树中边的集合。 V:所有顶点的集合
- 初始化:TE={}, U={u0} (u0∈V);
- 重复执行以下操作:
在所有的u∈U,v∈V-U的边(u,v)∈E中找权值最小的边(u0,v0),加入TE中,同时vo并入集合U中,直到U=V为止。 - 此时TE中有n-1条边, T={V,{TE}}为N的最小生成树。
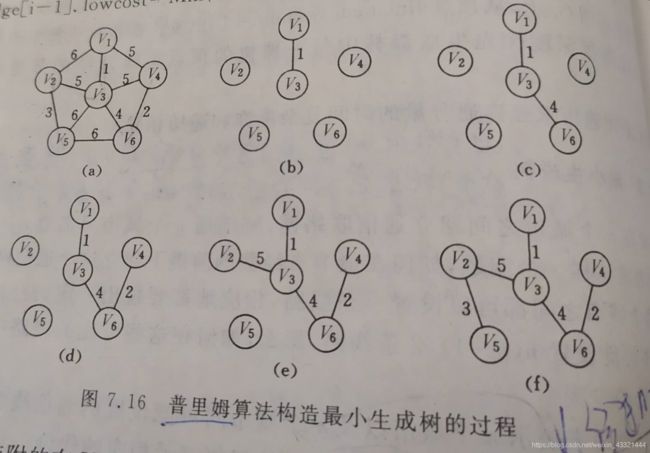
- 假设网中有n个结点,Prim算法时间复杂度是O(n²),与边数无关,适合求边稠密的网的最小生成树。
- Kruskal算法刚好相反,设变数是e,它的实践复杂度O(eloge),与结点数无关,适合求边稀疏的网的最小生成树。
(2)Kruskal算法
- 假设连通网N=(V,{E}),令最小生成树的初始状态为只有n个顶点而没有边的非连通图T=(V,{}),图中每个顶点自成一个联通分量。
- 在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量上,则将此边加入到T中,否则舍去此边而选择下一条代价最小的边。
- 依次类推,直到T中所有顶点都在同一连通分量上为止。
4.有向无环图及其应用
一个无环的有向图称为:有向无环图,简称DAG(directed acycline graph)图
应用:拓扑排序+关键路径
(1)拓扑排序
- 由某个集合上的一个偏序得到该集合上的一个全序,这个操作称为拓扑排序。
- 偏序:若集合X上的关系R是自反的、反对称的和传递的,则称R是集合X上的偏序关系
- 全序:设R是集合X上的偏序,如果对于每个x,y∈X,必有xRy或有yRx,则称R是集合X上的全序关系。
- 直观来看,偏序指集合中仅有部分成员之间可比较(部分有序),而全序指集合中全体成员之间均可比较(全体有序)。
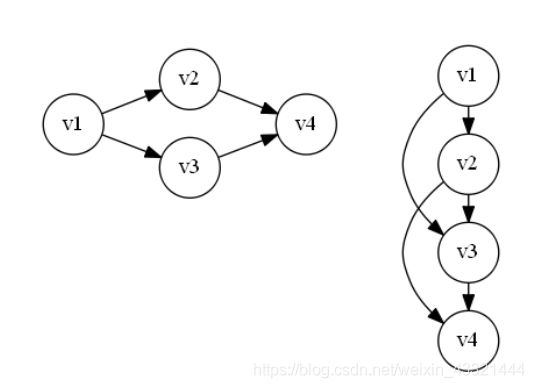
- 左图按照正常遍历那么有2种路径,分别为1234,1324。其中1始终在2,3遍历之前,2和3始终在4之前,2和3之间无法判断谁前谁后,所以这就是偏序。
- 再看右图在2和3之间加了一个指向,由2指向3,所以路线只有1234,所以它是全序。
AOV网中的拓扑排序算法
- AOV网(activity on vertex):顶点表示活动,弧表示活动间的优先关系的有向图
- 在有向图中选一个没有前驱的顶点并输出(入度为0的点)
- 在图中删除该顶点和所有以它为尾的弧(所有以该顶点出发的箭头)
- 重复上述两步,直到全部顶点都已输出,或者当前图中不存在无前驱的顶点为止。后一种情况说明有向图中存在环。
- 拓扑排序序列有很多种,下图只是其中一种。
(2)AOE中的关键路径
AOE网(activity on edge):边表示活动的网。AOE网是一个带权的有向无环图,其中,顶点表示事件,弧表示活动,权表示活动持续的事件。
路径长度最长的路径叫做关键路径。
5.最短路径问题 :迪杰斯特拉(DijKstra)算法
给定带权有向图G和源点v,求从v到G中其余各顶点的最短路径
(1)初始化时,S只含有源节点;
(2)从U中选取一个距离v最小的顶点k加入S中(该选定的距离就是v到k的最短路径长度);
(3)以k为新考虑的中间点,修改U中各顶点的距离;若从源节点v到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值是顶点k的距离加上k到u的距离;
(4)重复步骤(2)和(3),直到所有顶点都包含在S中。