一、前言
本文为两类人准备:技术控和工具控。
如果你是工具控,想简单方便地下载无水印的视频,那么可以使用第三方去水印平台:
抖音短视频解析下载平台
如果你是技术控,想要使用自己写的代码下载视频,那么可以使用本文的方法,用python写爬虫下载视频,最新开源项目:
Python3批量下载抖音无水印视频
本文的代码已经不是最新的,但是抓取思路就是如此,可以参考,代码可以直接运行使用,持续维护中。
更新日志
2018.5.23:github代码已经修复无法下载问题。
2018.7.17:github代码已经修复参数验证问题。
2018.11.07:api更新
二、实战背景
抖音越来越火,感觉它有毒,越刷越上瘾,总感觉下一个视频一定会更精彩,根本停不下来。想将抖音里喜欢的小哥哥/小姐姐的视频全部存到电脑硬盘里该如何操作?不想有抖音的视频水印该如何处理?
当初写完代码的截屏:
注:想学习Python的小伙伴们 进群:984632579 领取从0到1完整学习资料 视频 源码 精品书籍 一个月经典笔记和99道练习题及答案
三、实战
首先,希望你已经具备手机APP抓包分析的能力
1、带水印视频下载
先说说带水印的视频如何抓去吧。在定好爬取目标的时候,我们应该知道自己需要那些步骤完成这项任务。比如本文中提到的任务:抖音APP固定用户的视频批量下载。
思考过程:
想要批量下载视频首先要获得这些视频的链接;
想要获得这些视频链接可以通过用户的主页进行查看,想进用户主页,我得知道用户主页链接;
用户主页链接可以通过抖音APP的搜索功能获取,那么搜索功能接口如何获取?当然是抓包看看喽!
瞧,这样思考下来,问题是不是梳理的很清楚?
搜索接口:
那么接下来就是抓包分析了,抓包过程请自行尝试。步骤是这样的:
配置好Fiddler,即确定Fiddler可以对手机APP进行抓包;
在手机APP搜索框中输入用户信息,点击搜索;
在Fiddler找到搜索接口;
分析这个接口传递参数规则;
写代码生成相应查询接口。
通过分析你会发现,我们通过搜索接口返回的JSON数据可以找到用户主页信息,接下里用同样的方法抓取主页用户信息再分析一波,这时候就遇到问题了,你会发现用户主页链接使用了as和cp参数进行了加密,这该如何是好?比如链接如下:
https://aweme.snssdk.com/aweme/v1/aweme/post/?user_id=63386731255&max_cursor=0&count=20...&as=a18575a0311bfa0c2d&cp=55bba65311d10ccde1
上述链接省略号部分是一些手机信息,这部分不是必须参数,可以省略。user_id是用户id可以通过上个搜索接口获取,count是用户视频数量,同样可以通过上个搜索接口获取。那最后的as和cp参数怎么办?
我没有逆向抖音APP,就是小小测试了一下,看看能不能绕过这个加密接口?抖音APP自带视频分享功能,分享链接格式如下:
https://www.douyin.com/share/video/6511132370416962829/?region=CN...share_iid=28037626243
中间参数都不重要,在此省略。www.douyin.com域名下存放的是分享的视频,那么这个用户主页信息是否可以通过这个域名进行访问呢?小小测试一下你会发现,完全没有问题!
https://www.douyin.com/aweme/v1/aweme/post/?user_id=63386731255&max_cursor=0&count=20
这就是没有加密的接口,惊不惊喜,意不意外?根据这个用户主页接口,我们就可以轻松获取用户主页所有的视频链接了。
2、无水印视频下载
方法一:
无水印视频下载很简单,有一个通用的方法,就是使用去水印平台即可。
我使用的去水印平台是:http://douyin.iiilab.com/
在输入框中输入视频链接点击视频解析,就可以获得无水印视频链接。
这个网站当初我写代码的时候是好使的,当初用这个网站下了一些无水印视频,不过写这篇文章的时候发现这个取水印平台无法正常解析了,等它修复好了再用这个功能吧。
这个平台不仅包括抖音视频去水印,还支持火山、快手、陌陌、美拍等无水印视频。所以做一个这个网站的接口还是很合适的。
简单测试了一下,这个网站的API是需要付费解析的,如果通过模拟请求的方式有些困难,因此决定上浏览器模拟器Splinter。
Splinter是个好东西,跟Selenium使用类似
这里使用方法就不累述,不过有一点可以说的是,我们可以配置headless参数,来将Splinter配置为无头浏览器,啥事无头浏览器呢?就是运行Splinter不调出浏览器界面,直接在后台模拟各种请求,很是方便。
这部分的代码很简单,无非就是填充元素,确定解析按钮位置,点击按钮,获取视频下载链接即可。这点小问题,就自行分析吧。
整体代码:
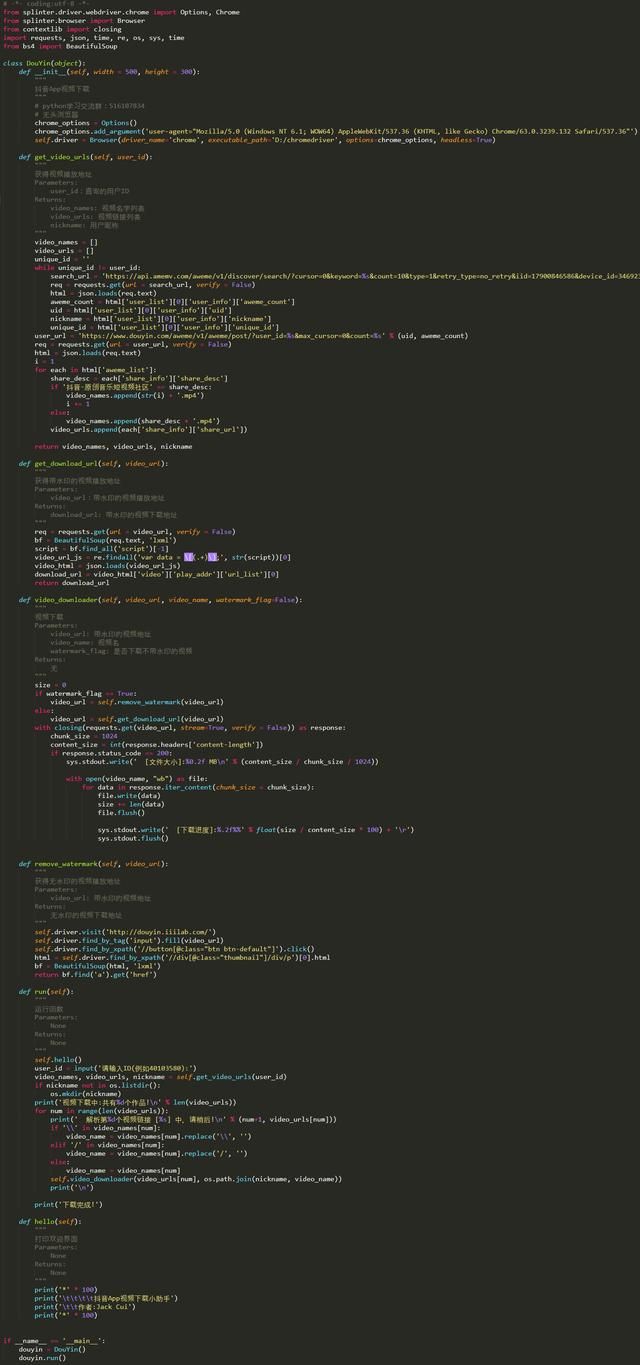
方法二:
这个方法是通过网友@羽葵的反馈得知的,对下载链接直接修改即可得到无水印下载链接。
download_url = video_html['video']['play_addr']['url_list'][0].replace('playwm','play')
方法简单粗暴,很好用。好处就是处理速度飞快,缺点是这种方法通用性不强,不同视频发布平台的打码方法可能有不同,需要自行分析。
四、总结
玩爬虫的日子还是很有意思的,好久没有那种舒爽感了。还有,找工作也是蛮心累的事。