故障分析系列(01) —— scrapy爬虫速度突然变慢原因分析
故障分析系列(01) —— scrapy爬虫速度突然变慢原因分析
1. 问题背景
- 在所有环境都没变的情况下,scrapy爬虫每天能爬取的数据量从3月5号开始急剧减少,后面几天数据量也是越来越少。

2. 环境
- 系统:win7
- python 3.6.1
- scrapy 1.4.0
- 网络:电信100Mb
- 代理:阿布云(服务商是阿里云)
- 爬取站点:amazon,amztracker
3. 排查步骤
3.1. 抓取scrapy爬虫的Log
# 文件 settings.py中
import datetime
LOG_LEVEL = 'DEBUG' # log等级设置为debug模式
startDate = datetime.datetime.now().strftime('%Y%m%d')
LOG_FILE = f"redisClawerSlaver_1_log{startDate}.txt" # 将log写入文件中
# 小技巧:因为debug模式下,一天下来,log会非常大,用Notepad++无法打开,可以使用UltraEdit来打开
-
后来分析Log,搜索failed, 发现了大量的 timeout error,占到了错误的九成,而且这两个站点的链接都有:
-
大量的Timeout会导致大量的重试,而且每个timeout,都要等待20s,才返回错误,所以极大的拉慢了爬虫的速度。

-
结论1:所以大胆猜测可能有几个原因:
-
第一,本地网络变慢。
-
第二,爬取的站点发生了变化,包括爬取的内容发生了变化。
-
第三,阿布云代理故障。
-
第四,爬虫错误。
-
**思考与完善:**其实在这一步,应该做好详细的error统计的,记录在数据库中,这个后期要完善起来。补充一下,形如此类:
# 文件 spider.py中
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import TimeoutError, TCPTimedOutError, DNSLookupError, ConnectionRefusedError
yield response.follow(
url=re.sub(r'page=\d+',f'page={page}',url,count=1),
meta={'dont_redirect':True,'key':response.meta['key']},
callback=self.galance,
errback=self.error # 做好error记录
)
RETRY = 4 # settings中最大重试次数
def error(self, failure):
if failure.check(HttpError):
response = failure.value.response
if response.meta['depth'] < RETRY:
failure.request.dont_filter = True
yield failure.request
else:
yield {
'url': response.url, 'error': 'HttpError', 'depth': response.meta['depth'],
'priority': response.request.priority, 'status': response.status,
'callback': response.request.callback.__name__,
'key': response.meta.get('key') or response.meta.get('item', {}).get('key', ''),
} # 日志用
elif failure.check(TimeoutError, TCPTimedOutError, ConnectionRefusedError, DNSLookupError):
request = failure.request
yield {
'url': request.url,
'error': 'TimeoutError',
'priority': request.priority,
'callback': request.callback.__name__,
'key': request.meta.get('key') or request.meta.get('item', {}).get('key', ''),
} # 日志用,只在最后一次超时后才执行
else:
request = failure.request
yield {'url': request.url, 'error': 'UnknownError', 'priority': request.priority,
'callback': request.callback.__name__} # 日志用
3.2. 爬取站点以及链接检查。
- 这个部分,可以参考之前的文章:
- python实现自动监测目标网站的爬取速度_以及整体网络环境分析:http://blog.csdn.net/zwq912318834/article/details/77411148
- 第二种方式:就是将Log中这些失败的链接放到浏览器中,看能不能打开。
2018-03-17 00:10:29 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying (failed 1 times): User timeout caused connection failure: Getting https://www.amazon.com/s/ref=lp_3734591_nr_n_6/143-5700955-1921713?fst=as%3Aoff&rh=n%3A1055398%2Cn%3A%211063498%2Cn%3A1063278%2Cn%3A1063282%2Cn%3A3734591%2Cn%3A3734671&bbn=3734591&ie=UTF8&qid=1517900687&rnid=3734591 took longer than 20.0 seconds..
2018-03-17 00:10:29 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying (failed 1 times): User timeout caused connection failure: Getting https://www.amazon.com/s/ref=lp_3422251_nr_n_8/134-3091133-0771864?fst=as%3Aoff&rh=n%3A3375251%2Cn%3A%213375301%2Cn%3A10971181011%2Cn%3A3407731%2Cn%3A3422251%2Cn%3A7261122011&bbn=3422251&ie=UTF8&qid=1517900684&rnid=3422251 took longer than 20.0 seconds..
- 结论2:发现这些失败的链接基本上都能在浏览器中打开,说明站点和本地网络的联通度没有问题。
3.3. 本地网络和代理网络检查。
- 这个部分,也可以参考之前的文章:
- python实现自动监测目标网站的爬取速度_以及整体网络环境分析:http://blog.csdn.net/zwq912318834/article/details/77411148
3.3.1. 本地网络检查
- 可以选择三种方式来确认:
- 第一种:找专门的网速测试网站,进行测试。

- 第二种:360宽带测试。

- 第三种:编写脚本,直接爬取对应站点,观察所需的时间。
- 其实,到这一步的时候,就应该看出问题所在了,只是当时有盲点,只测试了amazon站,而没有去测试amztracker站,导致后面走了很多弯路。不说了,看看走的弯路吧…
The speed result of not use proxy for amazon detail page.
No_proxy Totalurls:20, successCount:20, totalSuccessTime:68.56400000000001, avgTime:3.4282000000000004, connectFailCount:0, proxyFailCount:0
- 结论3:本地网络连通度和速度都没有问题。
3.3.2. 代理网络检查
- 由于当时看到每天跑的**环境脚本(http://blog.csdn.net/zwq912318834/article/details/77411148)**中出现了代理失误率比较高的情况,而且速度达到了8秒左右,如下所示,所以,比较怀疑是代理这边出现问题。
Amazon Totalurls:20, successCount:14, totalSuccessTime:104.4075, avgTime:7.457678571428572, connectFailCount:0, proxyFailCount:6
- 于是找到阿布云代理,详细了解了他们代理的一些信息,比如说动态IP的时效性是20(为了提高爬虫速度,将timeout时间设置为了20s,这才是最合理的),然后请他们提供了一下我的代理使用情况的统计数据:
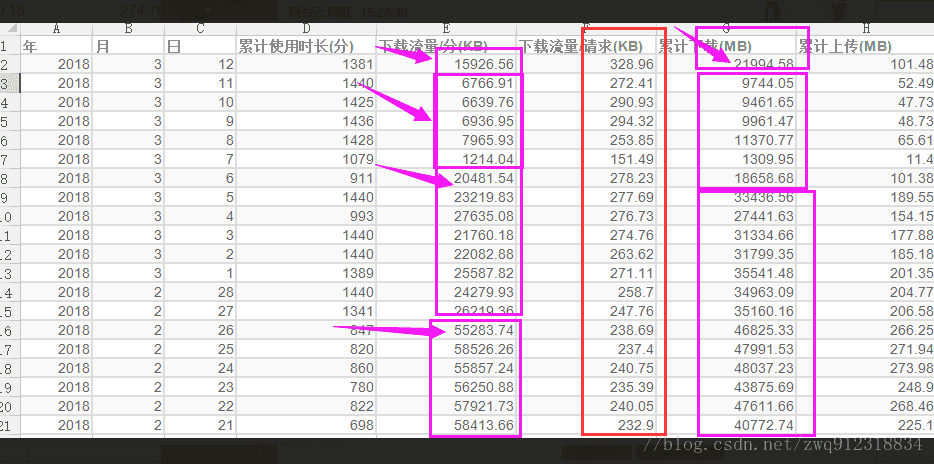
- 这是按天统计的数据,从这份数据中可以看到,每天scrapy向代理发送的请求数(下载流量/请求(KB))基本上维持不变,下载时长也一致,但是下载的数据量(下载流量/分(KB), 累计下载(MB))明显变少。
- 说明什么问题?:说明爬虫发出去的请求量没变,但是代理爬取下来的数据量明显变少,也就是说代理没法爬下来数据,问题在出在代理方。
4. 故障原因
- 然后在原有爬虫设置的基础之上,分别来跑 timeout 的url,最后发现:当跑amztracker站的链接时,在不加代理的情况下,是可以抓下来的。
2018-03-22 14:09:02 [scrapy.core.engine] DEBUG: Crawled (200) (referer: www.amazon.com)
- 但是在加代理的情况下,就发现这个amztracker站的链接都抓不下来。
# 在middleware.py中增加代理的情况下,会无法抓下来
18-03-21 11:09:22 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.amztracker.com/unicorn.php?rank=189599&category=Sports+%26+Outdoors> (failed 1 times): User timeout caused connection failure: Getting https://www.amztracker.com/unicorn.php?rank=189599&category=Sports+%26+Outdoors took longer than 20.0 seconds..
-
也就发现,是代理无法抓到amztracker这个站的页面。所以找到阿布云的客服人员,最终发现原因是:因为是召开2018全国两会期间,对国外站进行了管控,阿布云这边对amztracker站进行了屏蔽,后来他们将这个站的屏蔽打开,问题得以最终解决。
-
最终总结:其实在一开始的时候,就有机会很快分析问题的所在的。重点是做到心中有数,知道自己爬取了哪些页面,这些页面是否都能爬取,这些页面在加代理的情况下是否能爬取,需要做这样的测试。如果一开始就做了这样的测试,结果很快就出来了,而不用折腾这么久。
-
我们再看一下,爬虫在正常情况下,上传和下载的速度的对比情况如下,一旦爬虫异常,从速度上就可以观测得到: