基于神经网络的文本分类(基于Pytorch实现)
《Convolutional Neural Networks for Sentence Classification》
作者:Yoon Kim
单位:New York University
发表会议及时间:EMNLP 2014
1、文本分类简介
文本分类,指的是给定分类体系,将文本分类到某个或者几个类别中。根据其目标类别的数量,文本分类涵盖了二分类、多分类、多标签分类等常见分类场景。
文本分类是计算语言学的一个分支,同时也是自然语言处理中最基础的一个任务。
1.1 文本分类研究意义
文本分类是自然语言处理中最基础的一个任务,涵盖了新闻主题分类、情感分类、关系分类、意图识别等常见的自然语言处理场景。所以,开展文本分类相关的研究具有十分重要的理论意义和应用价值。

1.2 文本表示
文本分类中的关键问题在于文本表示,所谓文本表示指的是,通过某种方式将自然语言文本编码为计算机可以处理的形式(向量),这是实现自然语言理解中最基础也是最重要的步骤。文本表示方法主要有两种,一种是基于词袋的文本表示,一种是基于词嵌入的文本表示。

1.3文本分类发展历史
趋势:让机器更准确地捕获文本中的关键信息;

1.3.1 基于规则的文本分类
基本思想:就是使用人工编写特定的规则来进行分类,一般情况下,当文本中含有特定词语、短语或者模型时即将其判定为相应的类别,是最古老也是最简单的一种分类方法。

大 体 流 程 大体流程 大体流程

举 例 说 明 举例说明 举例说明
这种基于规则的文本分类方法效果并不好,因为语言表达形式十分灵活,语法规则无法覆盖所有的情况。而且这种方法高度依赖于专家。
1.3.2 基于特征的文本分类
基本思想:通过人工设计和提取特征。例如:词法特征、句法特征等,使用机器学习模型来捕获句子中所蕴含的关键信息,从而减少噪声词对最终结果的影响。
以向量空间模型为例:
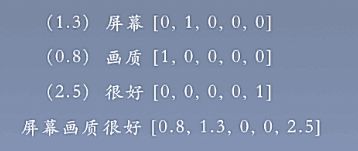
- 使用词袋模型来表示每个词;
- 使用词项作为特征项,使用词在文档中的TF-IDF值作为词的权重(特征权重);
- 使用加权求和得到文本表示;
- 训练一个分类器(LR、SVM)进行文本分类
1.3.3 基于神经网络的文本分类
基本思想:首先将输入的文本进行分词等一系列基础操作,随后将句子中的单词转化为低维的词表示,使用编码器(卷积神经网络、循环神经网络)得到句子表示,最终得到文本的目标类别。

大 体 流 程 大体流程 大体流程
这篇论文就是基于神经网路的文本分类的开山之作。
1.3.4 总结
- 基于规则的文本分类方法:
优点:易于实现,无需训练数据;
缺点:人工成本较高,效果较差; - 基于特征的文本分类方法:
优点:易于复用,能够进行信息的筛选;
缺点:人工提取特征的成本很高; - 基于神经网络的文本分类方法:
优点:无序人工特征,一般效果很好;
缺点:可解释性差,训练资源消耗大;
2、卷积神经网络相关技术
2.1 卷积神经网络
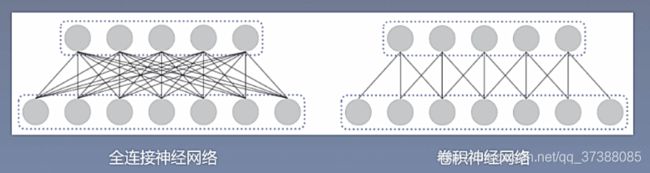
卷积神经网络:多层感知层是一种全连接的结构,但是全连接的网络会存在一定程度的冗余,卷积神经网络通过局部连接和权重共享的方法来实现对多层感知机的共享。
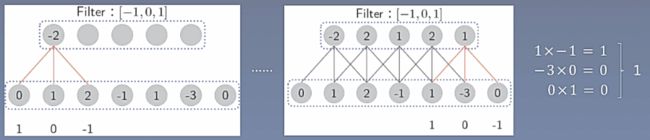
一维卷积操作:给定一个序列 X = { x 1 , x 2 , . . . , x n } X=\{x_1,x_2,...,x_n\} X={x1,x2,...,xn}和一个滤波器 F = { f 1 , f 2 , . . . , f m } F=\{f_1,f_2,...,f_m\} F={f1,f2,...,fm},卷积操作被定义为: y t = ∑ k = 1 m f k ∗ x t − k + 1 y_t=\sum_{k=1}^mf_k*x_{t-k+1} yt=k=1∑mfk∗xt−k+1
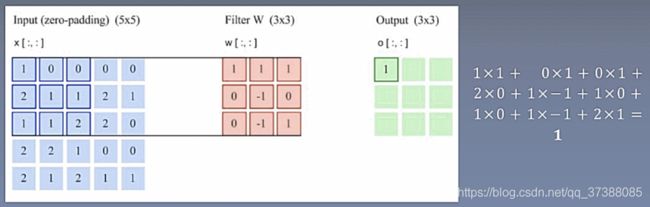
二维卷积操作:
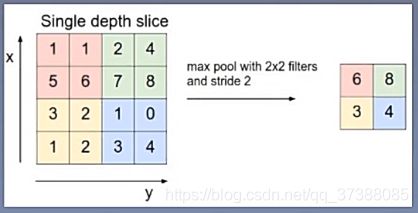
池化操作:池化本事是一种降采样的操作,用于降低特征维度并保留有效信息。、
- 减少模型参数,避免过拟合,提高训练速度;
- 保证特征的位置、旋转、伸缩不变性(CV);
- 将变长的输入转换成固定长度(NLP)
3、论文提出的模型
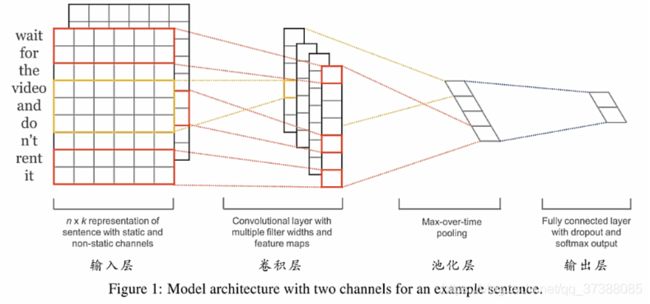
输入层把原始的词转换为向量表示,卷积层提取不同层次的特征得到特征向量,池化层是对卷积层的结果进行取和,最后经过全连接和softmax来输出当前句子的类别。在输入层中得到的是词向量,到了池化层之后得到的就是句子向量。
首先看模型输入层,输入层可以理解为把一句话转换成一个二维的矩阵,这个矩阵每一行都是一个词的词向量。第i个词的词表示为 x i ∈ R k x_i\in R^k xi∈Rk,即一个k维的实值向量。n表示数据中最长的句子的长度,当句子长度小于n的时候,通过在后面补零向量。
有了词表示之后,通过卷积神经网络提取特征。卷积操作为: c i = f ( w . x i : i + h − 1 + b ) c_i=f(w.x_{i:i+h-1}+b) ci=f(w.xi:i+h−1+b)上述公式表示使用窗口大小为h的滤波器(filter),也就是卷积核的高度,卷积核的宽度也就是词向量的维度,一般把这个区域称为感受野。接着得到特征图(feature map): c = [ c 1 , c 2 , . . . , c n − h + 1 ] c=[c_1,c_2,...,c_{n-h+1}] c=[c1,c2,...,cn−h+1]即当前滤波器所有输出的拼接。
从图中可以看出,有的感受野的高度为3,有的卷积核的高度为2,不同的感受野提取到的特征不同。在自然语言处理中,卷积核的宽度一般是词向量的宽度。
经过卷积后, 通过最大池化得到每个特征图中的最大值,保留当前卷积核卷积之后的最重要的特征。不同的卷积核可以捕获不同的信息,不同卷积核的特征图经过最大池化之后保留下来的重要信息不同。
注:一个滤波器得到一个结果,通常我们会使用多个滤波器(调整感受野)来捕获多种特征。
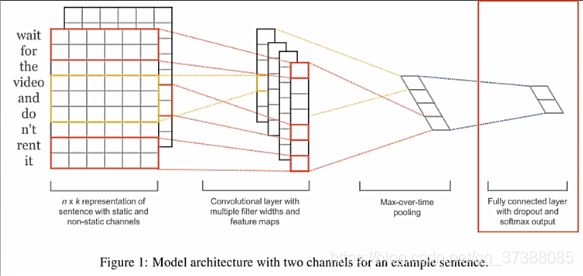
经过池化之后的数据经过全连接层得到最后的输出,全连接层的作用为: y = w ∗ z + b y=w*z + b y=w∗z+b将句子向量转化为一个维度和类别数相同的向量,输出经过softmax之后,其对应的每一维度为某一类别的概率,这样输出就具有了实际的含义。
在实际操作中,一般中最后的全连接层中使用dropout(随机失活): y = w ∗ ( z o r ) + b y=w*(zor)+b y=w∗(zor)+b公式中r是失活向量,以一定概率取值为1,否则取值为0。
dropout的好处是防止隐层单元的自适应,减轻过拟合的程度。