基于HMM和维特比算法的中文分词
隐马尔可夫模型(HMM)是将分词作为字在字串中的序列标注任务来实现的。其基本思路是:每个字在构造一个特定的词语时都占据着一个确定的构词位置,现规定每个字最多只有四个构词位置:即B(词首)、M(词中)、E(词尾)和S(单独成词),那么下面句子(1)的分词结果就可以直接表示成如(2)所示的逐字标注形式:
(1)中文/分词/是/文本处理/不可或缺/的/一步!
(2)中/B文/E分/B词/E是/S文/B本/M处/M理/E不/B可/M或/M缺/E的/S一/B步/E!/S
用数学抽象表示如下:用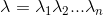 代表输入的句子,n为句子长度,
代表输入的句子,n为句子长度, 表示字,
表示字,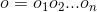 代表输出的标签,那么理想的输出即为:
代表输出的标签,那么理想的输出即为:
![]()
在分词任务上,o即为B、M、E、S这四种标记, 为诸如“中”“文”等句子中的每个字,包括标点等非中文字符。
为诸如“中”“文”等句子中的每个字,包括标点等非中文字符。
需要注意的是,![]() 是关于2n个变量的条件概率,且n不固定。因此,几乎无法对
是关于2n个变量的条件概率,且n不固定。因此,几乎无法对![]() 进行精确计算。这里引入观测独立性假设,即每个字的输出仅仅与当前字有关,于是就能得到下式:
进行精确计算。这里引入观测独立性假设,即每个字的输出仅仅与当前字有关,于是就能得到下式:
![]()
事实上,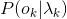 的计算要容易得多。通过观测独立性假设,目标问题得到极大简化。然而该方法完全没有考虑上下文,且会出现不合理的情况。比如按照之前设定的B、M、E和S标记,正常来说B后面只能是M或者E,然而基于观测独立性假设,我们很可能得到诸如BBB、BEM等的输出,显然是不合理的。
的计算要容易得多。通过观测独立性假设,目标问题得到极大简化。然而该方法完全没有考虑上下文,且会出现不合理的情况。比如按照之前设定的B、M、E和S标记,正常来说B后面只能是M或者E,然而基于观测独立性假设,我们很可能得到诸如BBB、BEM等的输出,显然是不合理的。
HMM就是用来解决该问题的一种方法。在上面的公式中,我们一直期望求解的是![]() ,通过贝叶斯公式能够得到:
,通过贝叶斯公式能够得到:
![]()
为给定的输入,因此 计算为常数,可以忽略,因此最大化
计算为常数,可以忽略,因此最大化![]() 等价于最大化
等价于最大化![]() .
.
针对![]() 作马尔可夫假设,得到:
作马尔可夫假设,得到:
![]()
同时,对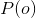 有:
有:
![]()
这里作齐次马尔可夫假设,每个输出仅仅与上一个输出有关,那么:
于是:
![]()
在HMM中,将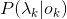 称为观测概率,
称为观测概率,![]() 称为转移概率。通过设置某些
称为转移概率。通过设置某些![]() ,可以排除类似BBB、EM等不合理的组合。
,可以排除类似BBB、EM等不合理的组合。
求解![]() 的常用方法是Veterbi算法。它是一种动态规划方法,核心思想是:如果最终的最优路径经过某个
的常用方法是Veterbi算法。它是一种动态规划方法,核心思想是:如果最终的最优路径经过某个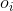 ,那么从初始节点到
,那么从初始节点到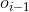 点的路径必然也是一个最优路径。
点的路径必然也是一个最优路径。
根据这个思想,可以通过递推的方法,在考虑每个时只需要求出所有经过各的候选点的最优路径,然后再与当前的结合比较。这样每步只需要算不超过![]() 次,就可以逐步找出最优路径。Viterbi算法的效率是
次,就可以逐步找出最优路径。Viterbi算法的效率是![]() ,l是候选数目最多的节点的候选数目,它正比于n,这是非常高效率的。
,l是候选数目最多的节点的候选数目,它正比于n,这是非常高效率的。
参考:https://book.douban.com/subject/30247776/
下面通过python来实现HMM,将其封装成一个类,类名即HMM:
class HMM(object):
def __init__(self):
# 状态值集合
self.state_list = ['B', 'M', 'E', 'S']
# 状态转移概率
self.A_dic = {}
# 观测概率
self.B_dic = {}
# 状态的初始概率
self.Pi_dic = {}
# 统计状态(B,M,E,S)出现次数,求P(o)
self.Count_dic = {}
# 计算转移概率、观测概率以及初始概率
def train(self, path):
# 初始化参数
def init_parameters():
for state in self.state_list:
self.A_dic[state] = {s: 0.0 for s in self.state_list} # 键为状态,值为字典(键为状态,值为转移概率值)
self.B_dic[state] = {} # 键为状态,值为字典(键为字或标点,值为观测概率值)
self.Pi_dic[state] = 0.0
self.Count_dic[state] = 0
def makeLabel(text):
out_text = []
if len(text) == 1:
out_text.append('S')
else:
out_text += ['B'] + ['M'] * (len(text) - 2) + ['E']
return out_text
init_parameters()
line_num = 0
with open(path, encoding='utf-8') as f:
for line in f:
line_num += 1
line = line.strip() # 每个句子去掉首尾空格
if not line:
continue
word_list = [i for i in line if i != ' '] # 字的集合
line_list = line.split() # 词的集合
line_state = [] # 句子的状态序列
for w in line_list:
line_state.extend(makeLabel(w)) # 给句子中的每个词打标签
assert len(word_list) == len(line_state)
for k, v in enumerate(line_state):
self.Count_dic[v] += 1 # 统计每个状态的频数(B,M,E,S)
if k == 0:
self.Pi_dic[v] += 1 # 每个句子的第一个字的状态(B,S),用于计算初始状态概率
else:
self.A_dic[line_state[k - 1]][v] += 1 # 计算转移概率
self.B_dic[line_state[k]][word_list[k]] = \
self.B_dic[line_state[k]].get(word_list[k], 0) + 1.0 # 计算观测概率
self.Pi_dic = {k: v * 1.0 / line_num for k, v in self.Pi_dic.items()}
self.A_dic = {k: {k1: v1 / self.Count_dic[k] for k1, v1 in v.items()} for k, v in self.A_dic.items()}
self.B_dic = {k: {k1: (v1 + 1) / self.Count_dic[k] for k1, v1 in v.items()} for k, v in
self.B_dic.items()} # 加1平滑
return self
def viterbi(self, text, states, start_p, trans_p, emit_p):
"""
text:要切分的句子
states:状态值集合(B,M,E,S)
start_p:初始概率
trans_p:转移概率
emit_p:观测概率
"""
V = [{}] # 局部概率,每个时刻的概率为{'B':,'M':,'E':,'S':}
path = {} # 最优路径
# 初始化,计算初始时刻所有状态的局部概率,最优路径为各状态本身
for y in states:
V[0][y] = start_p[y] * emit_p[y].get(text[0], 0)
path[y] = [y]
# 初始化为{'B': ['B'], 'M': ['M'], 'E': ['E'], 'S': ['S']}
# 递推,递归计算除初始时刻外每个时间点的局部概率和最优路径
for t in range(1, len(text)):
V.append({}) # 每个时刻都有一个局部概率,用字典{}表示
newpath = {}
# 检验训练的观测概率矩阵中是否有该字
neverSeen = text[t] not in emit_p['S'].keys() and \
text[t] not in emit_p['M'].keys() and \
text[t] not in emit_p['E'].keys() and \
text[t] not in emit_p['B'].keys()
for y in states:
emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0 # 如果是未知字,则观测概率同设为1
(prob, state) = max(
[(V[t - 1][y0] * trans_p[y0].get(y, 0) * emitP, y0) for y0 in states if V[t - 1][y0] >= 0])
# 这里乘观测概率是为了方便计算局部概率,max即记录为局部概率,乘不乘观测概率对于max选择哪个t-1到t的最大概率路径没有影响
V[t][y] = prob # 迭代更新t时刻的局部概率V
newpath[y] = path[state] + [y] # 实时更新t时刻y状态的最优路径,传统的维特比算法只记录每个时刻的每个状态的反向指针
path = newpath # 更新t时刻所有状态的最优路径
# 终止,观测序列的概率等于T时刻的局部概率
(prob, state) = max([(V[len(text) - 1][y], y) for y in ['E', 'S']]) # 只需要考虑句尾是E或者S的情况
return prob, path[state]
def cut(self, text):
prob, pos_list = self.viterbi(text, self.state_list, self.Pi_dic, self.A_dic, self.B_dic) # 返回最优概率和最优路径
begin = 0
result = [] # 分词结果
for i, char in enumerate(text): # 以字为单位遍历句子
pos = pos_list[i]
if pos == 'B':
begin = i
elif pos == 'E':
result.append(text[begin: i + 1])
elif pos == 'S':
result.append(char)
return result测试一下分词效果:
hmm = HMM()
hmm.train('./msr_training.utf8')
text = '这是一个非常棒的方案!'
res = hmm.cut(text)
print(text)
print(res)这是一个非常棒的方案!
['这是', '一个', '非常', '棒', '的', '方案', '!']
在微软亚洲研究院的测试数据集上评测效果,主要评测参数包括准确率(Precision)、召回率(Recall)、F1值,计算方法为:
将文本的分词结果用数值对来表示。每一对数字对应一个词,表示词的首字和末字在文本中的位置。
例如有一个字符串文本:
万人大会堂今晚座无虚席
字符串中每个字符的索引分别为:
0 1 2 3 4 5 6 7 8 9 10
标准分词结果如下:
万|人|大会堂|今晚|座无虚席
分词结果用一个个数值对来表示(根据每个词在字符串中的索引顺序):
(0,0) (1,1) (2,4) (5,6) (7,10)
这样通过比较 标准分词结果 和 测试分词结果 的数值对的重合情况,就能计算出测试分词结果的正确分词数。从而计算出准确率和召回率。
参考:https://blog.csdn.net/wcy708708/article/details/82951899
精确率和召回率的计算公式:
精确率P=切分结果中正确分词数/切分结果中所有分词数 × 100%
召回率R=切分结果中正确分词数/标准答案中所有分词数 × 100%
![]()
同时与jieba分词工具的分词效果相比较:
def text2tuple(path, cut=True, J=False):
import jieba
with open(path) as f:
dic = {}
i = 0
for line in f:
line = line.strip()
if cut:
res = line.split()
else:
if J:
res = jieba.cut(line)
else:
res = hmm.cut(line)
dic[i] = []
num = 0
for s in res:
dic[i].append((num, num + len(s) - 1))
num += len(s)
i += 1
return dic
def test(test, gold, J=False):
dic_test = text2tuple(test, cut=False, J=J)
dic_gold = text2tuple(gold, J=J)
linelen = len(dic_test)
assert len(dic_test) == len(dic_gold)
num_test = 0
num_gold = 0
num_right = 0
for i in range(linelen):
seq_test = dic_test[i]
seq_gold = dic_gold[i]
num_test += len(seq_test)
num_gold += len(seq_gold)
for t in seq_test:
if t in seq_gold:
num_right += 1
P = num_right / num_test
R = num_right / num_gold
F1 = P * R / (P + R)
return P, R, F1
P, R, F1 = test('./msr_test.utf8', './msr_test_gold.utf8')
print("HMM的精确率:", round(P, 3))
print("HMM的召回率:", round(R, 3))
print("HMM的F1值:", round(F1, 3))
P, R, F1 = test('./msr_test.utf8', './msr_test_gold.utf8', J=True)
print("jieba的精确率:", round(P, 3))
print("jieba的召回率:", round(R, 3))
print("jieba的F1值:", round(F1, 3))结果如下:
HMM的精确率: 0.762
HMM的召回率: 0.789
HMM的F1值: 0.388
jieba的精确率: 0.815
jieba的召回率: 0.811
jieba的F1值: 0.407
效果比jieba分词工具相差不多。