基于全局误差重构的深度卷积神经网络压缩方法
最近在看这篇文章,翻译出来略作整理,本人能力有限,翻译不足之处还请谅解
摘要
近年来,在图像分类、目标检测、目标分析和人脸校正等诸多领域,卷积神经网络(CNNs)都取得了巨大的成功。通过百万级甚至十亿级的参数,CNN模型在处理数量巨大的训练数据时显示出强大的能力。然而,由于模型存储方面的巨大代价,这些模型严重不足,这也限制了此类模型在一些内存有限的平台上的应用,如手机、嵌入式设备等。在本文中,我们的目标是在不损失分辨率的前提下尽可能地压缩CNN模型。主要想法是对输出重构误差进行明确地建模,然后最小化误差找到一个令人满意的率失真,该误差是原始数据与压缩的CNN之间的误差。于是,我们提出了全局重构误差算法(简称GER),首次以分层的方式改进了基于奇异值分解的低秩逼近算法,此算法对全连接层进行了粗糙的压缩。接下来,这种分层初始化的压缩值通过后向传播的方法从全局的角度进行优化。本文提出的GER算法针对两个广泛采用的卷积神经网络AlexNet和VGGNet-19,在ILSVRC2012图像分类数据集上进行了评估。与目前效果最好的其他几个CNN压缩算法相比,本文提出的算法在以上两个网络上均取得了最好的率失真。1.引言
近年来,卷积神经网络在计算机视觉领域已经展现了引人注目的成绩。例如,图像分类[A. Krizhevsky and Hinton, 2012; Y. Lecun and Haffner, 1998; Simonyan and Zisserman, 2014; C. Szegedy and Rabinovich, 2015; Zeiler and Fergus, 2014; Y. Jia and Darrell, 2014; K. He and Sun, 2015],目标检测[R. Girshick and Malik, 2014; K. He and Sun, 2014],以及图像重建[Y. Gong and Lazebnik, 2014]. 虽然神经网络的研究在学术界已经有着很长一段历史[Fukushima,1980],CNNs的巨大成功还是主要取决于当下先进的计算资源。例如,训练一个像AlexNet[A. Krizhevsky and Hinton, 2012]或VGGNet[Simonyan and Zisserman, 2014] 一样的判别式CNN模型,一般都需要上亿个参数,然后通过大量的带标签或者没有标签的数据利用近似优化算法(如随机梯度下降算法)进行微调,这主要是在GPU或分布式环境[J. Deng and Li, 2009]下进行的。类似的,CNNs的多种营养杯引入到学术界,像AlexNet [A. Krizhevsky and Hinton, 2012], VGGNet[Simonyan and Zisserman, 2014], GoogleNet [C. Szegedy and Rabinovich, 2015]等。即使是在像ImageNet ILSVRC[J. Deng and Li, 2009]类似的挑战任务中,所提交的性能最好的结果,其CNNs的存储代价也是很大的,也是要求很大数量的参数(大约10^8),[A. Krizhevsky and Hinton, 2012;Zeiler and Fergus, 2014; P. Sermanet and LeCun, 2013]。举个例子,一个8层的AlexNet网络包含600,000个节点,需要240MB的存储空间,然而一个19层的VGGNet则包含1.5M个节点,需要548MB的内存。在这种环境下,现存在CNNs不能直接应用在要求紧凑内存的手机或嵌入式设备上。与此相反的,有研究表示拥有百万级别参数的CNNs易于出现严重的过参数化[M. Denil and Freitas, 2013]。因此,在训练一个判别式CNN时并不是所有的参数和结构都是必须的,另一方面,在[Ba and Caruana, 2014]的研究中表明,浅层的或者简化的CNNs所产生的效果与拥有百万级别参数的深度CNNs根本没法相比。因此,一个自然的想法是在不降低分类精确度的情况下发现并且抛弃深度CNNs中多余的参数。
CNNs的压缩最近已经吸引了一部分研究者的注意,这些研究者又可以进一步分为3类:参数共享、参数修剪和矩阵分解。关于参数分享,Gong等人[Y. Gong and Bourdev, 2014]通过在参数上进行矢量量化来减少参数空间的冗余。Chen等人[W. Chen and Chen, 2015]提出了HashenNet模型,该模型使用一个低消耗的hash函数将相连接的两层的权重聚集到一个hash buckets中达到共享参数的目的。Cheng等人 [Y. Chengand Chang, 2015]提出在全连接层使用循环行列式预测代替原来的线性卷积预测,这减少了存储消耗并且可以利用快速傅里叶变换(FFT)来加速计算。关于参数修剪,Srinivas和Babu [Srinivas and Babu, 2015]探索减少了减少神经元的个数,并且提出了一种“数据自由”的修剪算法来移除多余的神经元。Han等人[S. Han and Dally, 2015]旨在减少整个网络参数和操作的总数。以上两种修剪算法从参数数量和计算量两方面进行了很大的削减。关于矩阵分解,Denil等人[M. Denil and Freitas, 2013]采用低秩分解方法以逐层的方式来压缩全连接层的权重。Novikov等人[A. Novikov and Vetrov, 2015]将稠密的全连接层权重矩阵转化为Tensor Train形式,以便于很大程度上减少参数的数目,同时保留层的表达能力。
然而,目前最好的方法[M. Denil and Freitas, 2013; Y. Gong and Bourdev, 2014; Srinivas and Babu,2015]仍旧依赖于分层的参数压缩,这无法提供一个明确的模型来衡量分类精度整体的损失。换句话说,这些工作可以看成对CNNs的分层、内隐、局部的压缩。从“内隐”压缩的角度,现有的工作都是只考虑通过最小化欧氏距离
 来逼近全连接层的参数W以求得W ̃。这种设置确实还存在很多问题,无法直接恢复用于分类的CNNs的输出(即学习到的特征)。从“局部”压缩的角度,一个更好的解决方案是以全局的方式保留分类精度,对整个全连接层压缩所有的参数。同时,内部层权重的相关性被忽略[M. Denil and Freitas, 2013; Y. Gong and Bourdev, 2014;Srinivas and Babu, 2015]。特别地,由于非线性激活函数(如sigmoid.tahn[Y. LeCun and Muller, 2012],或者线性校正单元(ReLU)[Nair and Hinton, 2010]),网络中每一层W和W ̃小的量化误差可能被放大和传播,导致大的产生式误差,这一点在我们的实验中有所体现。
来逼近全连接层的参数W以求得W ̃。这种设置确实还存在很多问题,无法直接恢复用于分类的CNNs的输出(即学习到的特征)。从“局部”压缩的角度,一个更好的解决方案是以全局的方式保留分类精度,对整个全连接层压缩所有的参数。同时,内部层权重的相关性被忽略[M. Denil and Freitas, 2013; Y. Gong and Bourdev, 2014;Srinivas and Babu, 2015]。特别地,由于非线性激活函数(如sigmoid.tahn[Y. LeCun and Muller, 2012],或者线性校正单元(ReLU)[Nair and Hinton, 2010]),网络中每一层W和W ̃小的量化误差可能被放大和传播,导致大的产生式误差,这一点在我们的实验中有所体现。
本文中,我们提出了一个新的“确定的”、“全局的”压缩CNNs框架,结构如图1所示:

我们核心的创新点在于引入了全局误差重构算法,该算法可以对原始输入的输出与压缩CNNs的输出之间的重构误差进行建模。以这种方式,隐含层和交互层之间的权重参数也被联合压缩。同时,我们没有对原始数据与层间近似参数的重构误差进行最小化,GER直接建立一个目标函数来恢复CNNs的输出,也包括全连接层的非线性激活函数的影响。
在实际应用中,我们通过基于SVD的低秩分解来对全连接层的权重进行初始化压缩,从可跟踪的角度这样能够放宽约束条件。接下来,像分层及粗压缩会通过后向传播最小化全局误差来进一步在层间联合优化,该优化方法使用随机梯度下降算法很好地解决了非凸优化问题。
本文提出的算法采用AlexNet和VGGNet-19两个被广泛采用的CNNs在ILSVRC2012图像分类库上进行评估。试验证明与其他目前最好的CNN压缩方法[M. Denil and Freitas,
2013; Y. Gong and Bourdev, 2014; X. Zhang and Sun, 2015].相比,本文提出的GER压缩方案在率失真方面表现最好。本文的主要贡献主要在一下三方面:
l 引入明确的目标函数来直接最小化网络压缩前后的重构误差,而现存的其他方法都没有直接最小化原始数据和压缩参数的差值。
l 在网络压缩的过程中我们对隐含层之间的链接进行全局建模,能够解决分层计算存在压缩误差的问题。
l 引入一种有效的优化方法解决相应的非凸优化问题,第一次使用基于SVD的低秩分解放宽约束条件,使用随机梯度下降学习最优化参数。.
2.基于低秩分解的CNN初始化压缩
2.1预备知识
我们定义一个特征矩阵![]() 作为输入来压缩一个全连接CNN,这里d是特征向量的维数,n是特征向量的个数(在初始的CNN网络AlexNet中可以是上一个卷基层的输出),压缩的全连接CNN前向传播的第l层可以表示为:
作为输入来压缩一个全连接CNN,这里d是特征向量的维数,n是特征向量的个数(在初始的CNN网络AlexNet中可以是上一个卷基层的输出),压缩的全连接CNN前向传播的第l层可以表示为:

此处 ![]() 是权重矩阵的元素,向量
是权重矩阵的元素,向量![]() 代表传输函数f(`)前后的激活单元。一般地,f(.)是非线性变换,例如,线性校正单元(ReLU)、sigmoid、tanh等。
代表传输函数f(`)前后的激活单元。一般地,f(.)是非线性变换,例如,线性校正单元(ReLU)、sigmoid、tanh等。
2.2 线性响应的分层低秩近似
首先考虑l层和l+1 层之间初始权重的低秩近似。为了找到一个近似的低秩子空间,我们最小化神经元响应的重构误差:
此处,![]() ,对于同一个输入信号X,两个线性变换的误差可以改写为
,对于同一个输入信号X,两个线性变换的误差可以改写为

通过SVD求解公式3, ,其中
,其中![]() 、
、![]() 是对应于U和V前k个奇异向量的子矩阵,
是对应于U和V前k个奇异向量的子矩阵,![]() 的对角元素是相应的S的k个最大奇异值,通过在W上运行SVD,S是一个对角矩阵。接下来,我们得到
的对角元素是相应的S的k个最大奇异值,通过在W上运行SVD,S是一个对角矩阵。接下来,我们得到![]() 的分解值
的分解值![]() ,此处,
,此处,![]() ,
, 。
。
2.3 拓展至非线性响应
对于CNN中更常出现的非线性传输,近似矩阵的结果不等于原来的值。因此,在设计参数矩阵W的低秩近似时,非线性传输应该被考虑在内。以ReLU为例,ReLU定义为f(.)=max(.,0),为了最小化ReLU响应的重构误差,我们有:

此处,第一项 ![]() 是第l层的非近似输入(l-1层的输出),第二项
是第l层的非近似输入(l-1层的输出),第二项![]() 是近似的l层输入。公式4的求解能够通过一个交互的求解程序来逐层优化。为了更清楚地说明,我们反向考虑这种逐层优化:以公式4为例,在优化中我们将
是近似的l层输入。公式4的求解能够通过一个交互的求解程序来逐层优化。为了更清楚地说明,我们反向考虑这种逐层优化:以公式4为例,在优化中我们将 ![]() 固定为常数,记为
固定为常数,记为![]() ,用
,用![]()
![]() 代替 。然后公式4中每一层的优化可以改写为:
代替 。然后公式4中每一层的优化可以改写为:

不幸的是,由于非线性参数的存在及低秩的限制,公式5也难以求解。为了得到一个可行的解决方法,我们将公式5放宽到:
此处,λ是惩罚参数, ![]() 是与
是与![]() 相同尺寸的一系列附加值。如果λ--->∞,公式6的结果将收敛于公式5的结果。为了求解公式6 ,我们进一步应用交互的求解程序,该程序固定
相同尺寸的一系列附加值。如果λ--->∞,公式6的结果将收敛于公式5的结果。为了求解公式6 ,我们进一步应用交互的求解程序,该程序固定 ![]() ,求解近似值
,求解近似值![]() ,反之亦然。优化的具体细节如下:
,反之亦然。优化的具体细节如下:
交互步骤I:固定![]() 更新
更新 ![]()
我们将公式7改写为秩回归问题
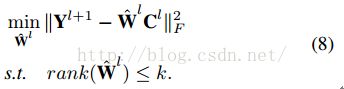
此处,![]() 是Frobenius范数。令
是Frobenius范数。令 ,公式8可以通过GSVD求解。
,公式8可以通过GSVD求解。
1.GSVD将![]() 分解为
分解为 ![]()
2.公式8中![]() 可以由
可以由![]() 给出,此处
给出,此处![]() 、 是U、V的前k列,
、 是U、V的前k列,![]() 是S的前k个奇异值
是S的前k个奇异值
3.得到分解值![]() ,这里 ,
,这里 , ![]()
交互步骤 II:固定![]() 更新
更新![]()
向量 ![]() 中的每一个元素都是彼此独立。我们将公式6 重写为 1-D 优化过程:
中的每一个元素都是彼此独立。我们将公式6 重写为 1-D 优化过程:

此处,![]()
![]() 是 的第j个输入。由于ReLU的限制,我们分别考虑
是 的第j个输入。由于ReLU的限制,我们分别考虑![]() 和
和![]() 两种情况,然后我们得到公式9的结果。
两种情况,然后我们得到公式9的结果。
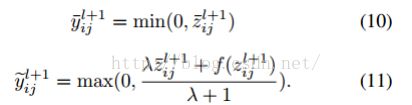
注意:公式9中,如果 ![]() ,
,![]() ,其他 。我们采用梯度下降解决上述1-D、非线性最小方差问题。
,其他 。我们采用梯度下降解决上述1-D、非线性最小方差问题。
上述的交互式优化在Algorithm I 中进一步说明。
此处, 是 的第j个输入。由于ReLU的限制,我们分别考虑 和 两种情况,然后我们得到公式9的结果。
注意:公式9中,如果 < , ,其他 。我们采用梯度下降解决上述1-D、非线性最小方差问题。
上述的交互式优化在Algorithm I 中进一步说明。

![]() 的初始值根据公式3的现象情况给出,理论上讲,λ应逐步增大到无穷,然而,如果λ太大,交互求解程序很难有效。为了执行更多的交互次数,折中方案是我们首先增加λ至1,接下来在得到收敛之后
的初始值根据公式3的现象情况给出,理论上讲,λ应逐步增大到无穷,然而,如果λ太大,交互求解程序很难有效。为了执行更多的交互次数,折中方案是我们首先增加λ至1,接下来在得到收敛之后![]() 的结果,此值作为所有全连接层压缩的初始值。
的结果,此值作为所有全连接层压缩的初始值。
3.通过全局误差重构进行层间压缩
以自下而上的方式,使用低秩分解得到的CNN初始压缩粗略近似于每一层的 ![]() 。正如上述讨论的,压缩误差会逐层累加,导致输出层产生大的总误差。为了解决这个问题,本文提出的全局误差重构(GER)旨在在各层间进行联合优化,如图2所示
。正如上述讨论的,压缩误差会逐层累加,导致输出层产生大的总误差。为了解决这个问题,本文提出的全局误差重构(GER)旨在在各层间进行联合优化,如图2所示

特别地,如果原始的CNN模型有m个全连接层,我们最小化非线性响应的全局结构误差的方法如下:

这里,![]() 是输出的非近似,
是输出的非近似,![]() 包含隐含层的m-1个权重,如下:
包含隐含层的m-1个权重,如下:

为了找到可能的几等,我们使用公式 4 的结果来放宽公式 12 的约束条件,令![]() 作为
作为![]() 的相应矩阵。公式 12 可以被改写为
的相应矩阵。公式 12 可以被改写为

这里, l = 0,1,···m-1,![]() 可以写为:
可以写为:

公式 15 中,![]() 和
和 ![]() 是通过求解公式 4 得到的 W 的近似分解。为了学习参数
是通过求解公式 4 得到的 W 的近似分解。为了学习参数![]() 和
和![]() , 在后向传播中采用了随机梯度下降算法,这需要计算目标函数与所有权重的梯度。因此,公式 14 中代价函数的误差信号通过下式得到
, 在后向传播中采用了随机梯度下降算法,这需要计算目标函数与所有权重的梯度。因此,公式 14 中代价函数的误差信号通过下式得到
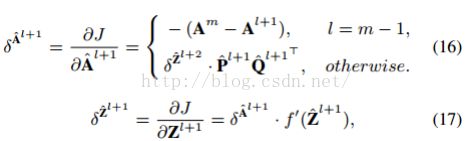
此处,![]() ,得到
,得到![]() 之后,我们计算目标函数与参数之间的两个梯度:
之后,我们计算目标函数与参数之间的两个梯度:

此处, l = m-1,m-2,···, 0·。注意:随机梯度下降算法能降低计算误差。 Algorithm 2 GER 优化算法的具体细节。

4.实验结果
为了评估GER 的性能,我们在ILSVRC2012图像分类数据集上进行了综合实验。我, 将GER应用在两个被广泛应用的CNNs网络AlexNet和VGGNet-19,将其结果与最近提出的效果最好的算法[M. Denil and Freitas, 2013; Y. Gong and Bourdev, 2014; X. Zhangand Sun, 2015]相比较。
4.1 实验设置
数据集。
我们在ILSVRC图像分类数据集上基于CNN压缩对GER进行测试。数据集包含来自1000类的超过1,000,000训练数据,还包含50,000张验证图像,其中每一类包含50张图像,我们从训练样本中随机选取100,000张图像(每一类100张)用于训练,并且在验证样本上进行测试。
实施细节
我们在AlexNet和VGGNet-19网络上应用GER。VGGNet-19包含16个卷基层和3个全连接层,AlexNet包含5个卷基层和3个全连接层。压缩网络使用Caffee训练,电脑配置为NVIDIAGTX TITAN X、12G显卡。学习率初始值0.01,每训练10次减半;权重衰减设为0.0005,动量设置为0.9。
基准
我们将GER与最近提出的4中效果最好的方法进行比较,包括基于PQ的压缩(PQ)[Y. Gong and Bourdev,2014],低秩分解(LRD)[M. Denil andFreitas,2013],通过交互求解程序的分层优化(AS)[X. Zhang and Sun, 2015],二值压缩(BIN)[Y. Gong andBourdev, 2014]。至于可替代方法,我们比较了GER与GER-IC,两者的不同在于在第二部分(仅仅是在该部分,其他部分相同)后者是基于SVD来初始化压缩的。
评估报告
验证样本的分类误差被用作评估报告。我们使用top-1分类误差和top-5分类误差来评估不同的压缩方法,然后我们从率失真的角度评价压缩性能,这反应了压缩率和分类误差平衡。
率失真比较
我们采用2^5~2^10之间不同的阶次k来实现不同的压缩率。对PQ,我们固定中心的数目为256(8位),然后变化分割的维度s=1,2,4,8. 对于LRD和通过交互求解程序的分层优化这两种方法,我们采用与GER相同的压缩标准,k的变化范围是2^5~2^10. 对于BIN,由于没有参数可以调节,压缩率固定为32.
top-1和top-5分类错误如图3所示,该图表明了在率失真上一致的趋势。
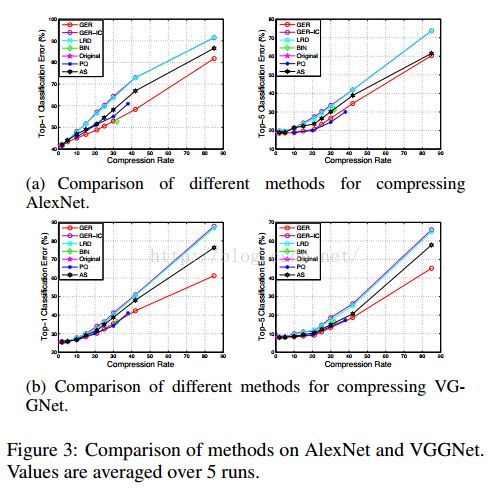
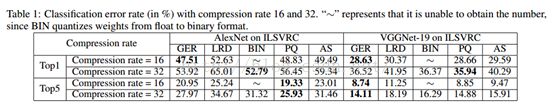
在内部层近似方面,GER-IC实现了与LRD相似的分类误差。然而,通过以全局的方式明确地建模重构误差,在压缩全连接层时,GER的表现要好于LRD和AS。进一步解释,GER得益于它的“确定的”压缩,这有效地组合了初始的分层压缩和层间全局压缩,然而,LRD和AS是不确定的压缩,它只考虑了局部的内部层关系。注意,PQ取得了比LRD和AS更好的性能。然而,据图3所示,PQ难以取得高的压缩率,这可能是由于有限的编码字典尺寸。相反的,与其他基准相比,GER取得了最好的率失真。最后,正如Gong等人发现的[Y. Gong and Bourdev, 2014],再将压缩率固定为32时,最简单的二值压缩取得了良好的效果。当对数据进行剧烈压缩时,基本的二值量化也是一个很好的选择。然而,当我们想控制压缩率时,这种方法就很难被采用,反过来这也是我们方法的关键优势。表1中固定压缩率时的分类误差表明,与其他基准相比,GER仍取得了最佳效果,特别是对于VGGNet-19。
单层误差
我们固定初始的未压缩版本的其它层来分析压缩每一层的分类误差。结果如图4所示
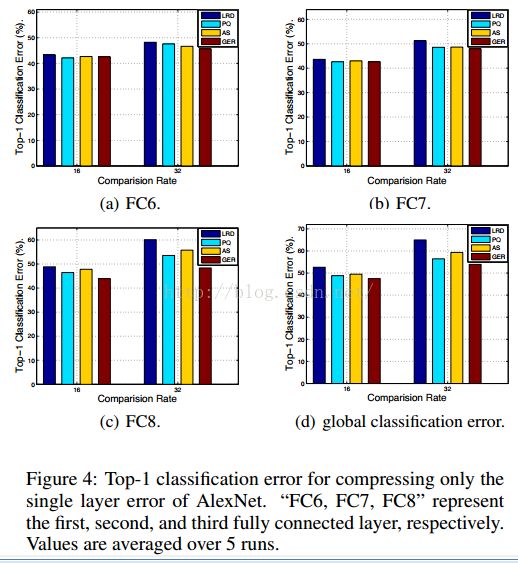
我们发现,使用所有的基准压缩前两层卷基层(FC6和FC7)都不会降低准确率。相反,对所有基准除了GER,压缩最后一个卷基层时都会导致巨大的分类误差。这种优势是因为GER能对所有层间通过调节和微调自动调整内部层误差。
5.总结
本文中,我们提出通过一个新的全局误差重构方法压缩卷积神经网络来减少模型的存储,这使得在手机、嵌入式等内存有限的设备中应用卷积神经网络成为可能。GER首先使用基于SVD的低秩分解近似类来粗略压缩全连接层的参数。这种分层初始化压缩在后向传播中以全局的方式被在层间进一步联合优化。之前的方法只是考虑恢复内部权重参数,与此不同,GER还对原始输出与压缩CNNs输出之间的重构误差进行明确建模,这极大地减少了由非线性激活造成的累积误差。通过与最近的CNN压缩方法相比,已经证明本文提出的GER方法能取得最好的率失真效果。接下来的工作,我们应该将该方法从全连接层扩展至卷基层,同时,进一步加速卷基层的计算。