KGSF:通过基于语义融合的知识图谱来改善会话推荐系统 KDD2020

论文链接:https://arxiv.org/pdf/2007.04032.pdf
代码链接:https://github.com/RUCAIBox/KGSF
1、摘要
会话推荐系统(CRS)旨在通过交互式对话向用户推荐高质量的项目。尽管已为CRS做出了一些努力,但仍有两个主要问题有待解决。首先,对话数据本身缺少足够的上下文信息,无法准确地了解用户的偏好。第二,自然语言表达与项目级用户偏好之间存在语义鸿沟。
为了解决这些问题,我们结合了面向单词和面向实体的知识图谱(KG)以增强CRS中的数据表示,并采用互信息最大化来对齐单词级和实体级的语义空间。基于对齐的语义表示,我们进一步开发了用于KG增强的推荐程序组件,以及可以在响应文本中生成信息丰富的关键字或实体的KG增强的对话框组件。大量的实验证明了我们的方法在推荐和会话任务上都能产生更好的效果。

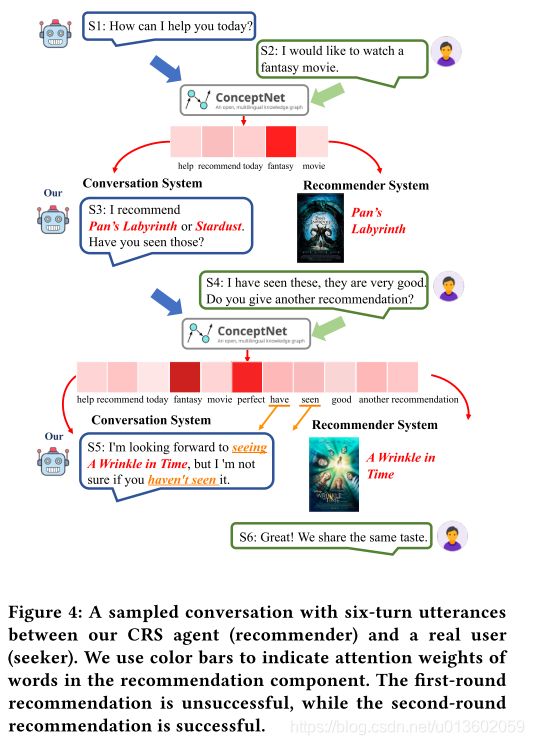
上图展示了一个具体的实例,红色单词表示一些重要的上下文信息,蓝色单词代表电影名称。
2、KGSF模型
整体模型框架如下:
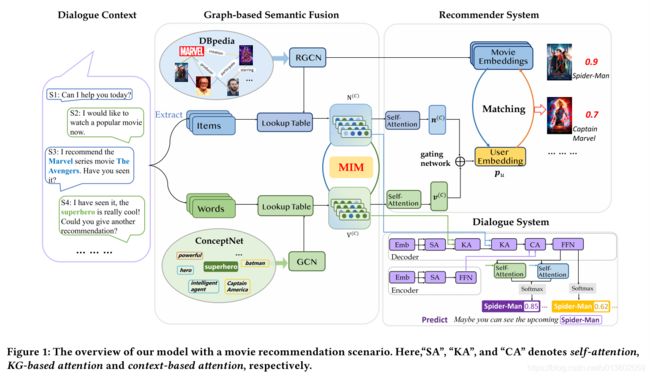
主要包括4个部分:对话信息、基于知识图谱的语义融合(项目图谱DBpedia和单词图谱ConceptNet)、推荐系统和会话系统等。
2.1、编码外部知识图谱
2.1.1、编码面向单词的知识图谱
使用的知识图谱为ConceptNet,首先从整个知识图谱中筛选出与对话相关的单词,组成一个小型知识图谱,然后使用GCN学习单词节点的嵌入表示,即 V ( l ) = R e L U ( D − 1 2 A D − 1 2 V ( l − 1 ) W ( l ) ) V^{(l)}=ReLU(D^{-\frac{1}{2}}AD^{-\frac{1}{2}}V^{(l-1)}W^{(l)}) V(l)=ReLU(D−21AD−21V(l−1)W(l))这里 A A A代表邻接矩阵,忽略了知识图谱中的关系信息。这样,每个单词 w w w得到一个 d w d_w dw维的向量表示 v w \textbf{v}_w vw。
2.1.2、编码面向项目的知识图谱
使用的知识图谱为DBpedia,首先从整个知识图谱中筛选出与对话内容相关的项目实体,组成一个小型知识图谱,然后使用R-GCN学习单词节点的嵌入表示,即 n e ( l + 1 ) = σ ( ∑ r ∈ R ∑ e ′ ∈ E e r 1 Z e , r W r ( l ) n e ′ ( l ) + W ( l ) n e ( l ) ) \textbf{n}_e^{(l+1)}=\sigma(\sum_{r\in\mathcal{R}}\sum_{e'\in\mathcal{E}_e^r}\frac{1}{Z_{e,r}}W_r^{(l)}n_{e'}^{(l)}+W^{(l)}n_e^{(l)}) ne(l+1)=σ(r∈R∑e′∈Eer∑Ze,r1Wr(l)ne′(l)+W(l)ne(l))这里 E e r \mathcal{E}_e^r Eer代表实体e在关系类型 r r r下的邻居实体集合。这样,每个实体 e e e得到一个 d e d_e de维的向量表示 n e \textbf{n}_e ne。
2.2、通过互信息最大化融合两个知识图谱
在以上的两个部分,我们分别得到了单词的表示 v w \textbf{v}_w vw和实体的表示 n e \textbf{n}_e ne,为了进行信息融合,我们对同时出现在一个对话中的单词和项目实体进行编码,使他们在隐空间中尽可能地接近,即 g ( e , w ) = σ ( n e ⊤ ⋅ T ⋅ v w ) g(e,w)=\sigma(\textbf{n}_e^{\top}\cdot \textbf{T}\cdot\textbf{v}_w) g(e,w)=σ(ne⊤⋅T⋅vw)然后最大化互信息,即优化下面的式子: M I ( X , Y ) ≥ E P [ g ( x , y ) ] − E N [ g ( x ′ , y ′ ) ] MI(X,Y)\geq\mathbb{E}_P[g(x,y)]-\mathbb{E}_{N}[g(x',y')] MI(X,Y)≥EP[g(x,y)]−EN[g(x′,y′)]这里 E P \mathbb{E}_P EP和 E N \mathbb{E}_N EN分别表示正负样本。
由于在一个对话中有大量的单词-实体对,如果对每一个都这样计算,复杂度较高,因此,提出一个super token w ~ \tilde{w} w~来编码整个对话中的所有单词的融合表示,使用的方法为自注意力机制: v w ~ = V ( C ) ⋅ α \textbf{v}_{\tilde{w}}=V^{(C)}\cdot\alpha vw~=V(C)⋅α α = s o f t m a x ( b ⊤ ⋅ t a n h ( W α V ( C ) ) ) \alpha=softmax(b^{\top}\cdot tanh(W_{\alpha}V^{(C)})) α=softmax(b⊤⋅tanh(WαV(C)))这里, V ( C ) V^{(C)} V(C)表示出现在一个对话 C C C中的所有上下文单词的嵌入表示。出现在同一个对话中的项目的表示也是采用类似的方法。
2.3、KG增强的推荐模块
根据自注意力机制,我们可以得到在一个对话 C C C中的所有上下文单词的表示 V ( C ) V^{(C)} V(C)以及所有出现的项目的表示 N ( C ) N^{(C)} N(C),接下来对这两部分进行融合,得到用户 u u u的偏好表示 p u \textbf{p}_u pu: p u = β ⋅ V ( C ) + ( 1 − β ) ⋅ N ( C ) \textbf{p}_u=\beta\cdot V^{(C)}+(1-\beta)\cdot N^{(C)} pu=β⋅V(C)+(1−β)⋅N(C) β = σ ( W g a t e [ V ( C ) ; N ( C ) ] ) \beta=\sigma(W_{gate}[V^{(C)};N^{(C)}]) β=σ(Wgate[V(C);N(C)])得到用户的偏好表示之后,把项目集中的某个项目 i i i推荐给用户 u u u的概率为 P r r e c ( i ) = s o f t m a x ( p u ⊤ ⋅ n i ) Pr_{rec}(i)=softmax(\textbf{p}_u^{\top}\cdot\textbf{n}_i) Prrec(i)=softmax(pu⊤⋅ni)整个损失函数为 L r e c = − ∑ j = 1 N ∑ i = 1 M [ − ( 1 − y i j ) ⋅ log ( 1 − P r r e c ( j ) ( i ) ) + y i j ⋅ log ( P r r e c ( j ) ( i ) ) ] + λ ∗ L M I M L_{rec}=-\sum_{j=1}^N\sum_{i=1}^M\left[-(1-y_{ij})\cdot\log\left(1-Pr_{rec}^{(j)}(i)\right)+y_{ij}\cdot\log\left(Pr_{rec}^{(j)}(i)\right)\right]+\lambda*L_{MIM} Lrec=−j=1∑Ni=1∑M[−(1−yij)⋅log(1−Prrec(j)(i))+yij⋅log(Prrec(j)(i))]+λ∗LMIM其中, j j j为对话的索引, i i i为项目的索引。
2.4、KG增强的应答生成模块
对于用户提出的一个为题,为了生成一个应答,这里采用Transformer模型来形成一个encoder-decoder框架。为了在decoder中生成应答,我们在子注意力模块之后加入两个基于KG的注意力层,以此来融合外部KG信息:

使用copy mechanism来增强生成的应答的质量: P r ( y i ∣ y 1 , ⋯ , y i − 1 ) = P r 1 ( y i ∣ R i ) + P r 2 ( y i ∣ R i , G 1 , G 2 ) Pr(y_i|y_1,\cdots,y_{i-1})=Pr_1(y_i|R_i)+Pr_2(y_i|R_i,\mathcal{G}_1,\mathcal{G}_2) Pr(yi∣y1,⋯,yi−1)=Pr1(yi∣Ri)+Pr2(yi∣Ri,G1,G2)损失函数为 L g e n = − 1 N ∑ t = 1 N log ( P r ( s t ∣ s 1 , ⋯ , s t − 1 ) ) L_{gen}=-\frac{1}{N}\sum_{t=1}^N\log(Pr(s_t|s_1,\cdots,s_{t-1})) Lgen=−N1t=1∑Nlog(Pr(st∣s1,⋯,st−1))这里 N N N代表在一个对话 C C C中的对话轮数,我们为 C C C中的每个句子 s t s_t st分别计算损失。
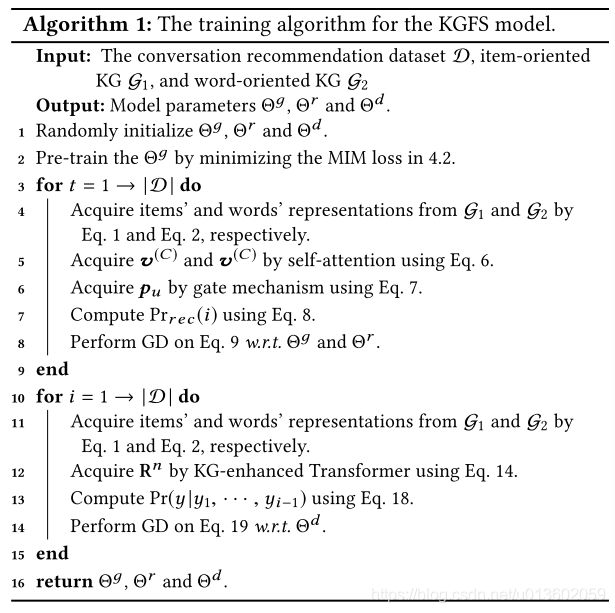
整个算法流程为:
3、实验
实验数据集为REcommendations through DIALog(REDIAL),划分训练集、验证机和测试集的比例为8:1:1。
推荐任务实验结果:
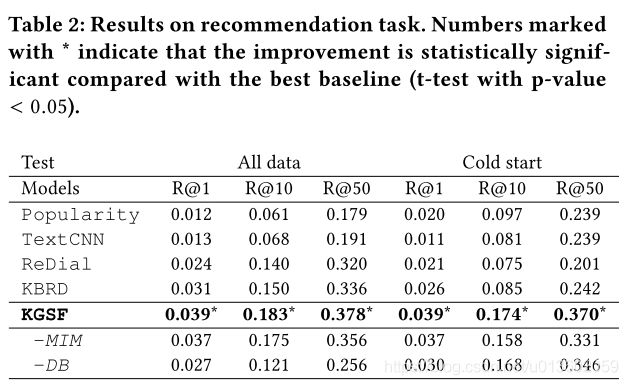
有无MIM loss对实验结果的影响:

对话生成任务实验结果:

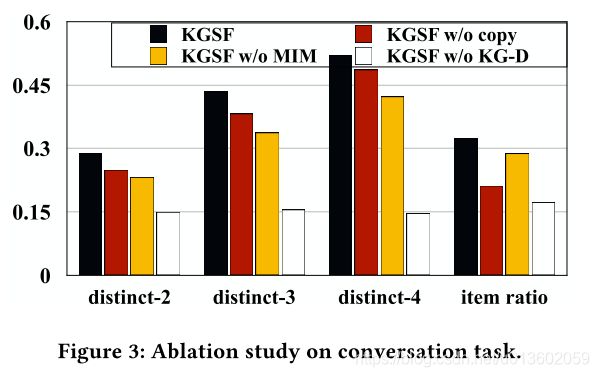
消融实验:
case study:
4、展望
- 融合更多的外部信息,比如,用户的统计特征等。
- 如何生成高质量的应答。
- 如何融入用户-项目交互信息。