Redis实现主从复制
文章目录
- 一. 配置主从概述
- 二. 配置主从复制
- 三. 配置主从原理
- 1. 全量复制
- 2. 部分复制
- 四. 配置主从问题
- 1. 读写分离
- 2. 主从配置不一致
- 3. 规避全量复制
- 4.规避复制风暴
一. 配置主从概述
主从复制(Replication):也叫主从同步,它是将Redis主服务器的数据同步到任意数量的从服务器上,同步使用的是发布/订阅机制。Redis的持久化功能,只能保障在宕机等情况下恢复大部分数据 ,但在硬盘故障、系统崩溃等单点故障情况下,仍可能引发灾难性后果。而主从复制可以更好的解决这一问题,达到故障转移的目的。
Redis通过`持久化`、`主从复制`、`哨兵模式`、`集群`保证了数据是安全和服务的高可用性。
二. 配置主从复制
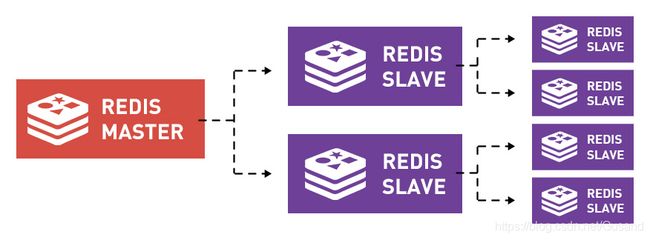
主从复制有两种实现方式:命令方式和配置方式(推荐), 示例拓扑图如下:
| role | ip | port |
|---|---|---|
| Master | 127.0.0.1 | 6379 |
| Slave1 | 127.0.0.1 | 6380 |
| Slave2 | 127.0.0.1 | 6381 |
准备工作:
- Redis安装包提供了名为
redis.conf的Redis配置文件,以此为模板,新建三个Redis配置文件: 如redis_6379.conf的内容如下:
# 拷贝一份新配置
$ cat /etc/redis/redis.conf | grep -v "#"|grep -v "^$" > redis_6379.conf
# 修改redis_6379.conf配置内容如下:
# cat ./redis_6379.conf|grep -E "port|dbfilename|appendfilename|logfile|pidfile"
$ cat ./redis_6379.conf
cat ./redis_6379.conf|grep 6379
port 6379
pidfile "/var/run/redis_6379.pid"
logfile "redis_6379.log"
dbfilename "dump_6379.rdb"
appendfilename "dump_6379.aof"
- 以此为例,创建
redis_6380.conf、redis_6381.conf文件
$ sed "s/6379/6380/g" redis_6379.conf > redis_6380.conf
$ cat ./redis_6380.conf|grep 6380
$ sed "s/6379/6381/g" redis_6379.conf > redis_6381.conf
$ cat ./redis_6381.conf|grep 6381
- 依次启动6379、6380、6381三个Redis服务
$ redis-server ./redis_6379.conf
$ redis-server ./redis_6380.conf
$ redis-server ./redis_6381.conf
命令方式实现主从复制: 这种方式简单方便,但重启服务后会断掉Replication状态
- 进入6380、6381,将他们以命令方式,指向主Redis服务(6379) ,如下:
$ redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379 # 设置为从服务,将6379作为Master
OK
# 无需重启redis服务
配置文件方式实现主从复制: 推荐该方式,但需要重启Redis服务
- 修改
redis_6380.conf、redis_6381.conf相关配置项,内容如下:
# 检查复制相关的配置项
$ cat ./redis_6380.conf|grep -v "#"|grep replica
replicaof 127.0.0.1 6379 # 关键项,指向master
replica-serve-stale-data yes
replica-read-only yes # 关键项
replica-priority 100
replica-lazy-flush no
client-output-buffer-limit replica 256mb 64mb 60
- 重启6380、6381两个Redis从服务,使之重新加载配置文件,操作如下:
$ redis-cli -p 6380 shutdown
$ redis-server ./redis_6380.conf
验证主从复制服务:
- 查看从服务(slave)状态信息
$ redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:slave # 角色Slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:7
master_sync_in_progress:0
slave_repl_offset:42
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:6f0624789e4178643a526dfc707293344b4e20cf
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:29
repl_backlog_histlen:14
- 查看主(master)服务状态信息
$ redis-cli info replication
# Replication
role:master
connected_slaves:2 # 显示多个slave状态信息
slave0:ip=127.0.0.1,port=6380,state=online,offset=392,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=392,lag=0
master_replid:c9db0ed52f30faa0138914f5d9fc3c77c01a675b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:392
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:392
- 向Master写入数据,验证Slave的Replaction是否成功
$ redis-cli set test "hello world"
OK
$ redis-cli -p 6380 get test
"hello world"
$ redis-cli -p 6381 get test
"hello world"
关闭主从复制服务: 在从服务上操作,操作如下:
127.0.0.1:6380> slaveof no one
OK
三. 配置主从原理
$ redis-cli info server | grep run_id #查看服务ID
$ redis-cli info replication | grep offset #复制偏移量
1. 全量复制
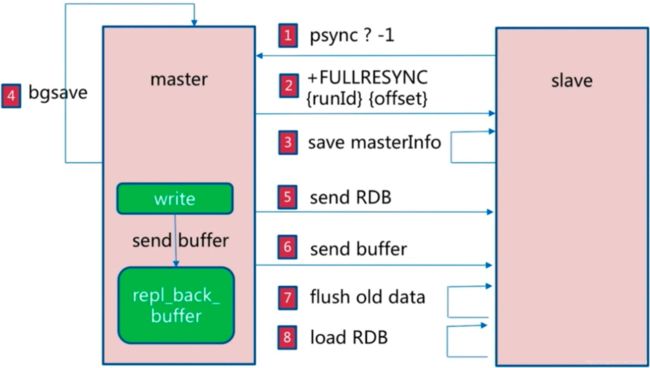
1.1 复制过程: 在出现网络抖动或服务重启(服务ID改变)时,会引发全量复制。复制过程如下:
- 第1步:slave向master发送psync(
runid为问号,偏移量为-1); - 第2步:master根据
runid和offset判断要做全量复制,并向slave发送FullResync(runid,offset)数据; - 第3步:slave保存master信息;
- 第4步:master保存全量复制到快照,同时将增量数据保存到
buffer; - 第5步:master向slave发送
RDB数据; - 第6步:master发送
send buffer数据; - 第7步:slave删除老数据;
- 第8步:slave加载新的
RDB;
1.2 复制开销:
- bgsave时间
- RDB文件网络传输时间
- 从节点清空数据时间
- 从节点加载RDB文件时间
- 可能的AOF重写时间
2. 部分复制
2.1 复制原理: Redis2.8+提供部分复制,即复制断开后会发送缓冲(默认1M),如果偏移量大于1M,则进行全量复制。

四. 配置主从问题
- 单个服务实例是故障可能是个小概率事件,但当服务的规模达到一定数量的时候,故障的产生就变成一个必然问题。
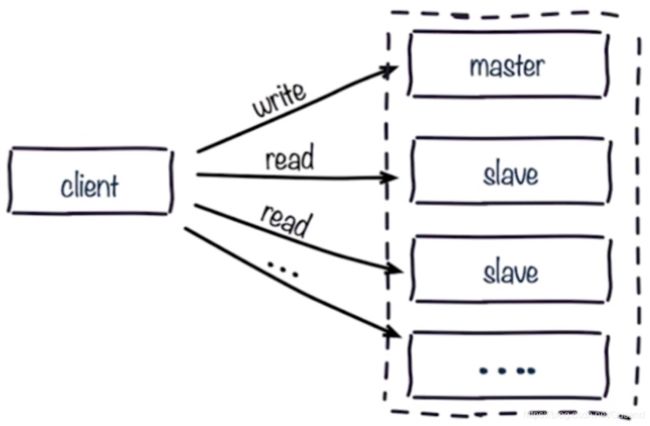
1. 读写分离
Replication除了数据备份(数据安全),另外一个重要的应用就是读写分离。读写分离可以提升系统性能,但也增加了系统的复杂性
- 1. 复制数据延迟: 由于网络延迟或程序阻塞,出现主从数据不一致,可判断数量偏移量,进行数据回溯查询,但这大大增加了复杂性。
- 2. 读到过期数据 : 由于对Slave的过期数据采取
懒惰删除或定时任务进行删除,难免出现读到过期数据。新版本(v3.2+)已经解决了该问题。 - 3. 从节点故障: 优先优化主节点,其次可使用哨兵模式、集群等方案。
2. 主从配置不一致
- 1. Maxmemery不一致:,master和slave内存大小设置不一致,在主从切换等情况下导致丢失数据,建议使用标准安装工具,对数据进行监控和校验。
- **2. 数据结构优化参数(hash-max-ziplist-entries):**主从设置不一致而导致的不可预知的问题。
3. 规避全量复制
- 1. 第一次全量复制: 无法避免,可才低峰(如晚上)进行,其次可使用小主节点(切片)减少全量复制的性能损耗。
- 2. 节点运行ID不匹配: 主节点重启(运行ID变化),可使用故障转移,将slave晋升为master,如哨兵或集群。
- 3. 复制积压缓冲区不足: 如网络中断,缓冲区不足1M,导致的全量复制,可调整
rel_backlog_size参数。
4.规避复制风暴
- 1. 单主机复制风暴: 即主节点重启,多从节点复制。可调整
复制拓扑,如"master->slave->slave"。 - 2. 单机器复制风暴: 即一台主机有多个redis实例,在机器重启后,导致大量全量复制。可将节点分散到多机器,当然也可以使用
高可用。
参考:
http://www.redis.com.cn/topics/replication
https://www.cnblogs.com/wdliu/p/9407179.html