用HMM模型进行中文分词
用HMM模型进行中文分词
问题情况
中文分词任务,采用的是Sighan2004(backoff2005微软数据)数据。给出训练集和测试集,对测试集进行中文分词,要求给出的分词结果F-score尽量大。
常见解法介绍
首先是两个naive版本,但是对于这个特定的任务,虽然naive版本原理实现简单,但是效果却很好。
1.正向(逆向)最大匹配
以选出匹配的单词尽可能长为目标分词,具体操作是从一个方向不断尝试匹配出最长单词,再进行下一次匹配,直到匹配完成为止。
2.双向最大匹配
同样以选出匹配的单词尽可能长为目标分词,具体操作可以给分词结果打分,找一个合适的打分函数下,匹配单词较长且单词出现次数较多则比较合算,同时希望求解打分函数最大值的复杂度比较低。
在上一篇report中详细介绍过我的双向最大匹配实现方法,原理简单但是效果很好,是我目前能实现效果最好的一个版本。
下面有四个基于概率的版本,算法相对高级一点。
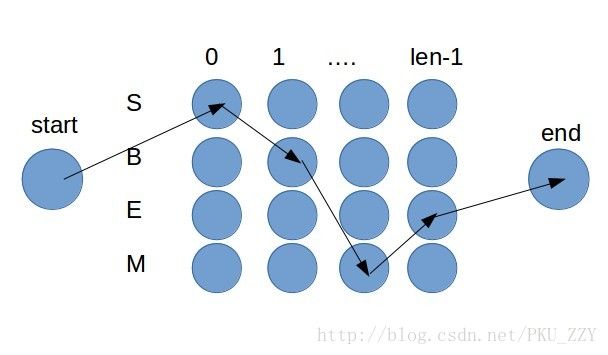
*这四个版本都把分词结果看作汉字的4-tag序列(‘S’单字,’B’词首,’E’词尾,’M’词中),那么分词转化为找到一个最合适的序列。
3.最大熵模型
最大熵模型基于4-tag,并且使得分词留下信息量最大的信念来做,用到了信息论里的一些理论基础。
4.CRF模型
CRF模型基于4-tag的随机向量场方法,用到了一些概率方法。
5.HMM模型
与CRF相似的,HMM也是基于4-tag的概率模型,HMM模型找出概率最大的一个4-tag序列作为分词结果,其中的转移概率由训练获得。
6.结构化感知器
读到有人写的源代码,但是具体还没有仔细学习过。等学习了自己实现一个专门写一篇report来阐述原理。
HMM模型原理
设 l 为序列长度, tag[0:l] 为tag序列, char[0:l] 为character序列,其中 [:] 切片用法和python一样为左闭右开区间。
如果画出状态转移图像,发现状态只能在层间点转移,转移路径上的分数为概率,求一条概率最大的路径。这可以用维特比算法计算,本质上就是一个动态规划,属于很简单的算法问题。以下为我的实现。
def mostPossibleTag(char):
char = numberFormatter(char)
l = len(char)
if l == 0:
return []
p0 = {t: getStartPro(char[0], t) for t in TAG}
tag0 = {t: [t] for t in TAG}
for i in range(1, l):
p = {t: 0 for t in TAG}
tag = {t: [] for t in TAG}
for t in TAG:
for prevT in TAG:
tranP = p0[prevT] * getTranPro(char[i-1], prevT, char[i], t)
if tranP > p[t]:
p[t] = tranP
tag[t] = tag0[prevT] + [t]
p0 = p
tag0 = tag
maxP = -1
maxT = ''
for t in TAG:
tranP = p0[t] * getEndPro(char[l-1], t)
if tranP > maxP:
maxP = tranP
maxT = t
return tag0[maxT]具体实现
1.对于未登录词或未登录用法的处理
可以给一些字典外的字一个平均水平的估计值。例如吃馕,馕是一个生字,那么馕就作为吃后面接的字的平均水平。那么通过吃饭,吃醋等高概率出现词汇大致可以学习出吃馕是’B‘->’E‘。
但是对一些非法转移序列必须给出0分的概率(例如’S’->’M’之类的)。
还有一种情况,对于字典里常见字但是从没见过用法的组合,应该给一个很低的惩罚估计概率,例如吃饭,这个搭配很常见,但是‘E’->’B’这个组合可能从来没见过,所以再计算这个组合的时候应该给一个惩罚低概率,但是不能为0。
我的实现不是特别仔细,只大致实现了惩罚情况,仔细的实现边界条件不好处理,一直出现错误,我后来索性try except,一出现错误(汉字,用法没见过,用法次数为0之类的未登录问题)就开启惩罚估计。
2.数字和百分号小数点特殊处理
3.标点
因为标点符号必然独立成词,所以可以切开标点符号再对于每一小句切词,可以降低句子长度。
4.运算精度
如果句子比较长,概率会很小,应该取对数来计算,但是我的代码没有,因为经过了3.的切分,句子不是很长了。
测试结果
| 模型 | F-score |
|---|---|
| HMM模型 | 0.915 |
| 双向最大匹配 | 0.951 |
| 最大熵模型 | 0.839 |
| CRF模型 | 0.964 |
最后
本来很早就想自己实现一个HMM模型了,但是看了别人的代码和文章一直觉得自己不行。真的动手实现了,原来HMM也没有我想象中的那么难(虽然我的最终版本没有发挥出HMM的完全威力,而且写的时候边界情况也够呛)。所以不要自己给设置障碍,不要一直告诉自己自己不行。与诸君共勉。