2018 ATEC NLP比赛 15th 总结
这次比赛跟以往的比赛似乎很不一样(虽然这个是我第一次参加),以往比赛的特征技巧,融合技巧,以及一些典型的模型都在这次比赛都失效。我一度怀疑蚂蚁金服是故意设计了数据。。。。
赛题介绍
问题相似度计算,即给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义。
示例:
“花呗如何还款” --“花呗怎么还款”:同义问句
“花呗如何还款” – “我怎么还我的花被呢”:同义问句
“花呗分期后逾期了如何还款”-- “花呗分期后逾期了哪里还款”:非同义问句
对于例子a,比较简单的方法就可以判定同义;对于例子b,包含了错别字、同义词、词序变换等问题,两个句子乍一看并不类似,想正确判断比较有挑战;对于例子c,两句话很类似,仅仅有一处细微的差别 “如何”和“哪里”,就导致语义不一致。
比赛思路
初赛期间,我花了大量时间做特征工程,收效甚微。因为如前面所说,这次比赛传统方法在这次数据里面都没有效果。但是,正因为我在前期做了大量的特征分析,在后期我在设计网络结构的时候能够更加得心应手,比如DIIN 这个网络模型结构,很多top20的队伍都尝试过,可是他们都说这个模型不给力,而这个模型恰恰是我的最强模型,这个跟我之前做的特征工程这部分工作有着紧密的联系。
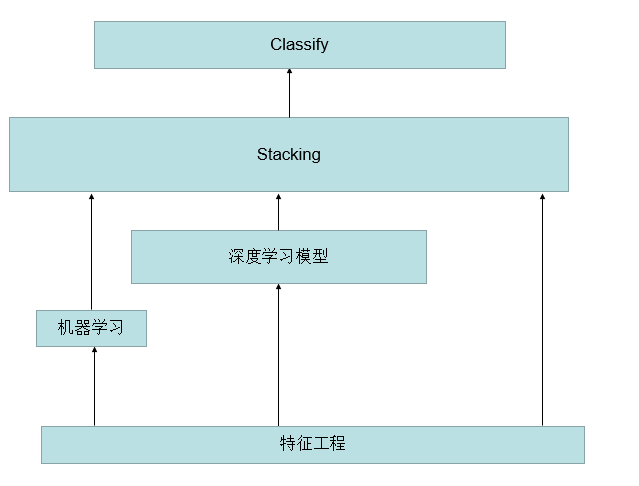
我预想的比赛的整体流程应该是下图这样,但是最终还是没有用stacking,因为觉得提升不会很大。
这次比赛,我是非常遗憾的,也吐槽一下阿里PAI平台,每次模型训练都要排很久的队。。。 这次我进复赛的排名很低,前100名进复赛,我是第70进的,排位在前的一些大佬有认识的,但是由于排名低,最终决定自己一个人打比赛。自己一个人打比赛,随之而来的问题很多,其中最严重的问题是对时间利用效率非常低,以至于最终我的模型还没有完全收敛,就提交了最终的分数,而且期间因为一些突发事故,我丢失了几次线上提交机会,在仅剩最后一次提交机会的时候,选择了稳妥一点,但是分数低一些的模型融合。
特征工程
1)n-gram similiarity(blue score for n-gram=1,2,3…);
-
get length of questions, difference of length
-
how many words are same, how many words are unique
-
question 1,2 start with how/why/when(wei shen me,zenme,ruhe,weihe)
5)edit distance
- cos similiarity using bag of words for sentence representation(combine tfidf with word embedding from word2vec)
7)manhattan_distance,canberra_distance,minkowski_distance,euclidean_distance
深度学习模型
Siamese LSTM
这个模型如果实现好,单模型在初赛B榜上排名 150名左右。
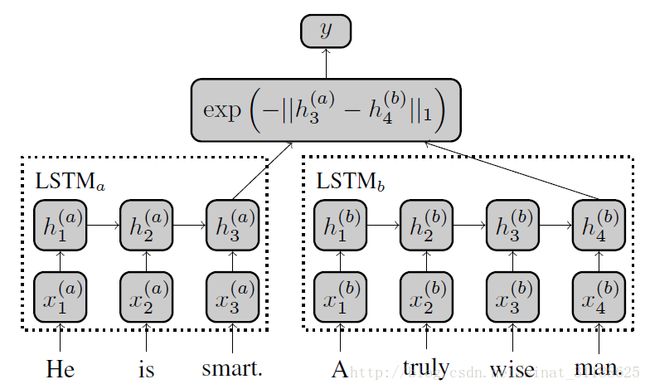
这是一个非常直观的模型,这个是大多数参赛选手首先会想到的模型结构。但是有一个很重要的一点是要预训练词向量,并在训练期间固定 这个trick 其实在Quora比赛中就有很多经验帖子提过,但是没人郑重提过,以至于我当时并没有在意。在这次比赛中如果update embedding vector during training 的话,看到的现象就是非常容易过拟合,在训练数据上几个epoch之后loss 已经降低到最低,而在验证集上的loss却开始上升,F1值变为0。 很多人在这个时候就会认为是模型不行,而去尝试别的模型去了,其实在这个时候,稍微分析一下就会知道,模型在验证集上表现如此异常,就好像是遇到了从未见过的数据一样(我称之为陌生感 哈哈),就好像训练数据和验证集完全没有联系一样,这个时候我们需要在训练数据和验证机之间搭接一个桥梁,就是固定词向量。
固定了词向量,效果果然有明显的提升,在线下测试集分数可以到0.52左右,提交上去之后分数在0.59左右。排名150名。
Siamese LSTM 改进方案
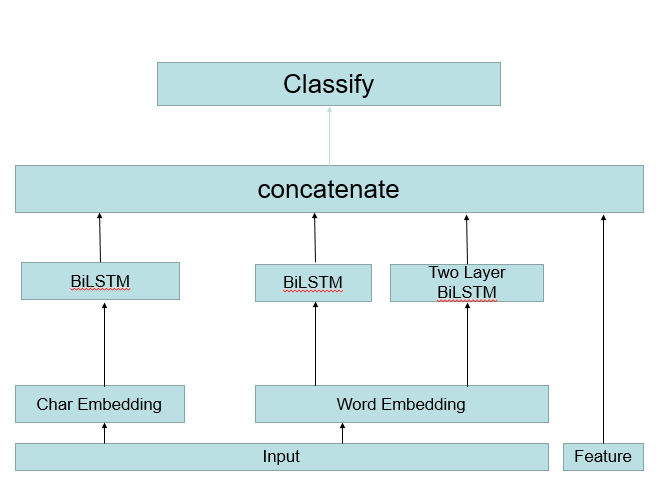
这个模型在word 和 char 级别的 embedding 一同送入同一个神经网络去训练,并增加了传统特征。这个单模型线下测试集合可以到0.54,线上分数在0.61。做k-fold之后提交,分数可以到0.63的线上分数,排名73名。 我也是靠这个模型进入到复赛
(在这里需要提一下的是,传统特征在初赛数据上是比较有用的,只是到了复赛平台就不行了。)
Decompose Attention
到了复赛阶段,我主要是尝试Attention的方法,最先尝试的模型就是这个。
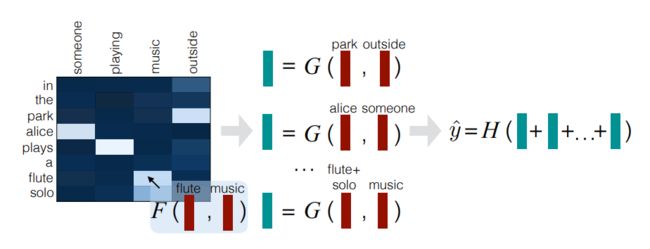
这个模型在复赛平台上分数可以到0.70(word char 级别 embedding 一同送入神经网络训练)
这个模型有效,很大程度上是因为通过attention的方式学习到字与字之间的关系。
Decompose Attention 改进方案
word char 级别的 decompose attention 结构如下:
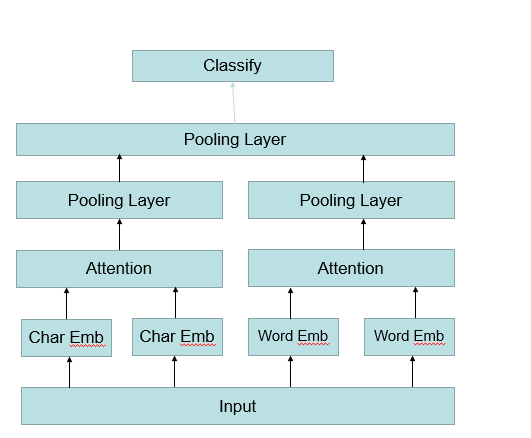
在Pooling Layer 中 我采用的是 AvgPooling 和 MaxPooling 拼接。还有其他的一些模型细节是 ,对F函数我采用的是一层线性结构(如果线性层数增多会产生Bug,最终还是找了古师兄帮忙调了这个bug,这bug如果调不出来,这模型就要丢掉了),relu激活函数,没有使用drop out(这主要是为了加速收敛,效果上可能会打折扣)。
ESIM 模型

这个模型我没有进行细致的调试,最终提交到线上的分数是0.705 。后来知道这个模型是很多队伍融合模型之一的时候,还是比较遗憾的。
这次比赛,我用的最成功的模型是DRCN模型和DIIN模型。据我了解,在前20的队伍里,把DIIN模型用好的只有我一个人,哈哈哈。这里解释一下,即使是同一个模型,每个队伍之间实现方式都是不一样的,大家对模型改造程度都非常大,这跟平时的炼丹经验息息相关。
先来说一下DRCN 。论文名字叫《Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information》

我从打比赛的角度分析一下这么模型,打比赛如果完全照着这个模型去实现的话,分数会很低。很多人模型实现几个,分数不高就心灰意冷跑路了。
首先我们来看看Word Representation Layer部分。
作者使用了fix word embedding 和 trainable word embedding 拼接的方式。但是这个比赛数据,做过特征分析就知道,样本之间很独立,差异非常大,我们应该花大力气在词和词,字和字之间关系的学习上,如果使用fix word embedding, 那么attention的学习压力都落在线性层上,在蚂蚁金服这个比赛是很吃亏的。 我的做法是只用trainable word embedding。
还有作者用CNN去提取char 级别的特征,我觉得如果这么用,在模型融合的时候会很吃亏(没有理论根据,直觉谈谈)。不如分别训练char level 和 word level 模型最终进行融合。
接着我们再来看看 他的attention 计算方式。

看到这个attention 计算方式,感觉作者太随意搞了。怎么拿余弦相似度计算attention呢? 作者在论文里没有说,但我跑了几个实验之后就非常理解作者的做法,这个模型最需要克服的点是层数深,梯度回传费劲,模型很可能会因为多加了几个线性层就崩掉了。我们传统的计算Attention 都是线性变换,在计算权重送入softmax,作者用余弦相似度就是想少用点线性层。但是在蚂蚁金服这个比赛,不能用这种方式。因为蚂蚁金服句子都比较短,我们用的残差网络层用两层就够了,所以权衡之后,在计算attention的时候,还是用线性变换会更好一些。要知道作者的残差网络层数是5层,6层。。。所以,对论文的理解深浅会直接影响你对这个模型的使用效果。
我们再来说说auto encoder 这个我用了之后效果不好,可能是因为作者的网络层数确实太深,最终的FC layer 太大,需要用auto encoder去提取特征,这种东西在比赛中真心觉得不实用,个人浅薄见解。
再说说 Prediction Layer,我没有用绝对值特征,又加了max和 相乘的特征。这个是评感觉加的,实验效果也确实好点。
最后来说说DIIN 模型。这个模型是我最后一天写的,用三个小时写模型,加调试,然后就放到平台训练了。在平台开始训练时间是下午1点,一直到晚上12点,模型还没完全收敛,然后跟其他模型融合提交了。之前成绩我是24名,最后靠这个模型上分,我觉得非常神奇。而且这个模型我提交的只是char level model,word level model没有来得及写。对此我是感觉很遗憾的。
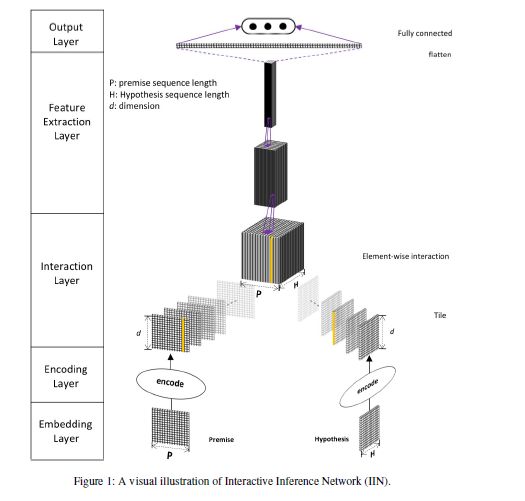
我当时看到这个模型的时候,看到他最后的特征提取是CNN提特征,而我之前的模型都是RNN 所以我觉得用这个模型是可以有效提升分数的。
这个模型在embedding layer用了fuse gate ,效果不好,别用! 我是有时候很纳闷为啥论文里面的模型总是喜欢大而全,什么都往里加。
Interaction Layer:
在这里我用的是 decompose attention 没有用self attention ,self attention效果也不行。
最后的CNN层我是用DenseNet 网络。
这个模型收敛很慢,最后提交的时候都没有收敛完。这也是我这次比赛比较遗憾的一点。
接下来讲讲模型融合
当时B榜开放就一周,评测机会就7次左右。我的有效提交是三次。因为我那段时间基本白天写代码,晚上看论文,经常会因为当天模型没有训练完就没办法提交,中间又因为几次失误,发生评测错误。 这就直接导致我最后提交的时候,畏手畏脚。
我最终提交的模型 drcn word + drcn char + diin char,然而 siamese 和 decompose 都是很work的模型 ,我的最强模型融合应该是: siamese word and char with feature + drcn word + drcn char + diin char + decompsoe atten char + decompose atten word。
主要我听很多其他队伍因为模型过拟合掉榜,其中第一队伍直接掉到11名,skyhigh 则是通过减模型 排名回到第二。所以我就没敢把siamese 模型加进去,所以最终提交也是以求稳的策略提交。
以上是这次比赛的总结,这次比赛收获很多,也认识了很多人,very cool
如果有时间再继续更新 我当时失败的实验过程。失败的实验过程其实包含更多 我对这个任务的思考。
参考论文:
[1].Siamese recurrent architectures for learning sentence similarity.
[2].Enhanced LSTM for Natural Language Inference.
[3].A Decomposable Attention Model for Natural Language Inference
[4].Shortcut-Stacked Sentence Encoders for Multi-Domain Inference
[5].Attention is All you Need
[6].Natural Language Inference over Interaction Space
[7].Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information