【论文解析】如何将Bert更好地用于文本分类(How to Fine-Tune BERT for Text Classification?)
论文How to Fine-Tune BERT for Text Classification?基于Bert模型,在6份英文语料和1份中文预料上(包括情感分析、问题分类和主题分类),进行了翔实的文本分类效果对比实验结果,虽然fine-tune的最终效果取决于具体的task,但文中采用的思路和策略仍值得学习和尝试。
Bert作为强有力的预训练模型,用作下游任务的常见手段包括:(1)作为特征提取器;(2)fine-tune;(3)直接pre-train
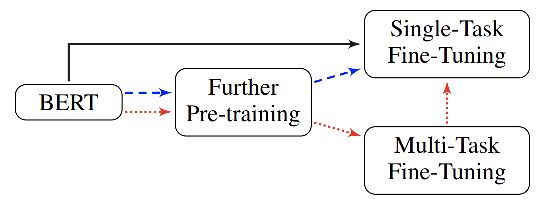
论文充分借鉴了ULMFiT的思想,设计了一系列fine-tune和pre-train的策略,根据使用语料的范围可分为:
(1)直接针对task的fine-tune
(2)基于In-Domain语料的pre-train+fine-tune
(3)基于In-Domain语料的pre-train+多任务fine-tune
(4)基于In-Out-Domain语料的pre-train+fine-tune
(5)基于In-Out-Domain语料的pre-train+多任务fine-tune
论文大部分试验采用了L12-H768-A12的base-bert模型,通过对后一层或若干层上的[CLS] output+FC的方式得到文本分类结果。
1. fine-tune结论
1.1 长文本处理
Bert的文本极限长度为512,因此并不能直接用于长文本的下游任务。其可行的解决方案包括:
方案一:截断文本,包括保留首部文本(head-only,510个token),保留尾部文本(tail-only,510个token),保留首尾(head+tail,其中首128+尾382),剩余的2个token留给[CLS]和[SEP]
方案二:分层方案,将文本分为 L / 510 L/510 L/510个子句,输入共享的bert,然后将每个字句的[CLS]输出通过max-pooling、avg-pooling和self-attention的方式进行连接后接FC。
论文发现,在给定文本上,采用head+tail的方法效果最佳。
1.2 分层学习率
和CV领域的预训练模型类似,bert这样深层模型的不同层可视为对语言的不同层次的表达,越低层的表示越抽象和共性,而顶层的表示更接近于训练任务本身。
为了保留抽象表示,而让顶层表示更适合于具体任务,一种显而易见的做法是越底层的学习率可以设置的小一些。本文就采用了逐层线性衰减的试验方法:
θ t l = θ t − 1 l − η l ∇ θ l J ( θ ) , η k − 1 = ξ η k \theta_t^l=\theta_{t-1}^l- \eta^l \nabla_{\theta^l}J(\theta), \eta^{k-1}=\xi \eta^{k} θtl=θt−1l−ηl∇θlJ(θ),ηk−1=ξηk对比发现,设置基础 l r = 2 e − 5 lr=2e-5 lr=2e−5, ξ = 0.95 \xi=0.95 ξ=0.95比较合适。
1.3 各层信息的提取
bert中各层网络具有不同的词/句法/语义信息,因此可以提取不同layer的输出,同时将其加以拼接和pooling操作在送入分类器。
本论文对比了12个Encoder层,以及最低/高4层特征提取的分类结果,发现只取最后一层输出,和最后四层+max-pooling在IMDb数据集上效果最优。
1.4 训练超参设置
论文在采用base-bert时,batch=32,序列长度设为128,学习率5e-5,整个训练steps为100,000,其中10%采用了warm-up的学习率策略。
在采用bert时,batch=24,dropout=0.1,优化器采用Adam, β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9,\beta_2=0.999 β1=0.9,β2=0.999,同样采用了的warm-pu策略,基础学习率2e-5,warm-up比例为10%。
训练epoch=4,基于验证数据集上的最优模型作为最终模型。
1.5 遗忘灾难
对于bert这种基于大量语料、经过精心设计和调参的网络架构,在具体下游任务进行调参时,其学习率需要设置的较小,以防止目标文本对原始网络参数的破坏,即遗忘灾难(catastrophic forgetting )。
本论文对比了一系列学习率,发现像2e-5这样的学习率对bert而言是必要的,而当学习率大于4e-4时,网络训练发散。同时,采用分层学习率的做法,也能有效避免遗忘灾难。
2. pre-training结论
论文在得到fine-tune最优策略的基础上,又开展了一系列pre-training的试验对比。
2.1 不同语料上pre-training的效果
论文分别尝试了在task、in-domain和cross-domain语料上进行pre-training后,再处理分类task的效果。发现三者相较于原始的bert,以及诸如bert+biLSTM+self attention等其它模型都能不同程度的提高结果,其中cross-domain的收益较小,作者认为这是因为bert已经是基于大量universal语料训练的结果,而cross-domain的知识与task语料分布的不一致。
2.2 多任务fine-tuning
基于上述pre-training结果,作者又分别对各子任务进行了进一步的fine-tune,发现在大部分语料上略有收益。
2.3 Bert-large
作者尝试了基于Bert-large的task-pre-train,取得了SOTA。