【BERT】BERT模型压缩技术概览
由于BERT参数众多,模型庞大,推理速度较慢,在一些实时性要求较高、计算资源受限的场景,其应用会受到限制。因此,讨论如何在不过多的损失BERT性能的条件下,对BERT进行模型压缩,是一个非常有现实意义的问题。
本文先介绍模型压缩的概念及常见方法;随后,对目前出现的BERT剪枝的技术做一个整体的介绍。在后面的文章中,挑选一些典型的例子再进行深度的介绍。
作者&编辑 | 小Dream哥
1 模型压缩
所谓模型压缩,就是在尽可能不改变模型效果的情况下,减少模型的尺寸,使得模型有更快的推理速度。
随着深度学习技术越来越多的得到应用,模型压缩越来越受到重视,因为当模型的准确度达到一定程度后,如何用更少的硬件成本去达到相同的效果,就变得很有价值;另一方面,随着深度学习模型变得越来越“大”,在很多涉及边缘计算的嵌入式设备中部署就变得困难,模型压缩就变成一个必须的事情。

目前,模型压缩主要有4种方法,包括如下:
1.parameter pruning and quantization
参数剪枝(parameter pruning),顾名思义,就是对模型的参数进行删减;
量化(quantization)是一种通过降低数值精度来提高模型推理速度的方法,例如将通常的64位浮点型,转化为16位浮点型进行运算。
2.low-rank factorization
通过低秩因式分解,将参数矩阵分解成两个较小矩阵的乘积来逼近原始参数矩阵,降低模型的参数量,ALBERT中就用了这种方法。
3.transferred/compact convolutional filters
设计特殊结构的卷积滤波器以减少存储和计算的复杂度。
4.knowledge distillation
知识蒸馏,即先训练一个大模型得到较好的效果;再设计和训练一个小模型来获得与大模型相当的效果。
[1] Cheng Y , Wang D , Zhou P , et al. A Survey of Model Compression and Acceleration for Deep Neural Networks[J]. 2017.
[2] Cheng J , Wang P S , Gang L I , et al. Recent advances in efficient computation of deep convolutional neural networks[J]. Frontiers of Information Technology & Electronic Engineering, 2018, 19(01):64-77.
[3] Liu Z , Sun M , Zhou T , et al. Rethinking the Value of Network Pruning[J]. 2018.
[4] Frankle J , Carbin M . The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks[J]. 2018.
2 BERT模型压缩
BERT模型的参数量巨大,这导致几乎没有BERT或者 BERT-Large 模型可直接在GPU及智能手机上应用,因此模型压缩方法对于BERT的未来的应用前景非常有价值。下面介绍一些BERT模型压缩的工作,可作参考。
(1) BERT剪枝
去掉BERT中不必要的部分,剪枝的内容包括权重大小剪枝、注意力剪枝、网络层以及其他部分的剪枝等。还有一些方法也通过在训练期间采用正则化的方式来提升剪枝能力(layer dropout)。
BERT模型包括输入层(嵌入层),self-attention层,feed-forward等,针对BERT系列模型的结构,可采取的剪枝策略如下:
1)减少层数
在BERT模型的应用中,我们一般取第12层的hidden向量用于下游任务。可以根据不同的任务,接不同层进行finetune。
2)维度剪枝[1]
可以通过因式分解等方法,降低BERT隐藏层的维度,从而降低BERT的参数量。
3)Attention剪枝
在多头注意力中,每头维度是64,最终叠加注意力向量共768维。有研究[2]表明:在推理阶段,大部分头在被单独去掉的时候,效果不会损失太多;将某一层的头只保留1个,其余的头去掉,对效果基本不会有什么影响。
[1] Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning
[2] Are Sixteen Heads Really Better than One?
[3] Pruning a BERT-based Question Answering Model
[4] Reducing Transformer Depth on Demand with Structured Dropout
[5] Reweighted Proximal Pruning for Large-Scale Language Representation
2) BERT权重因子分解
通过低秩因式分解,将参数矩阵分解成两个较小矩阵的乘积来逼近原始参数矩阵,降低模型的参数量。最典型的就是ALBERT模型,其提出者认为,词向量只是记忆了相对少量的词语的信息,更多的语义和句法等信息时由隐藏层记忆的。因此,他们认为,词嵌入的维度可以不必与隐藏层的维度一致,可以通过降低词嵌入的维度的方式来减少参数量。
感兴趣的同学看这篇博文详细了解ALBERT的内容:
【NLP】ALBERT:更轻更快的NLP预训练模型
[1] Structured Pruning of Large Language Models
[2] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
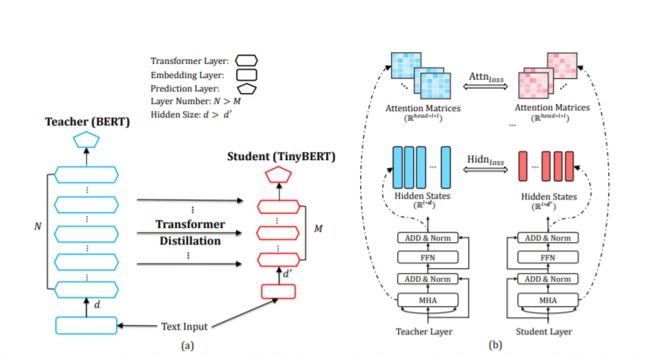
3)BERT知识蒸馏
知识蒸馏的本质是让超大线下teacher模型来协助线上student模型的训练,本质上是一种超大模型的知识迁移过程。
对Bert的知识蒸馏,研究的是如何将一个大型网络的泛化能力,迁移到一个相对小型的网络,从而达到以下两个目标:
1) 不需要从零开始训练小模型;
2) 蒸馏学习得到的模型效果优于直接训练。
理论上来说,模型在训练的时候需要尽可能多的神经元连接,而一旦训练完成,其中的部分连接其实是冗余的,可以用一个相对紧凑的结构来代替。
[1] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
[2] Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
[3] Distilling Transformers into Simple Neural Networks with Unlabeled Transfer Data
[4] Attentive Student Meets Multi-Task Teacher: Improved Knowledge Distillation for Pretrained Models
[5] Patient Knowledge Distillation for BERT Model Compression
[6] TinyBERT: Distilling BERT for Natural Language Understanding
[7] MobileBERT: Task-Agnostic Compression of BERT by Progressive Knowledge Transfer
4)BERT量化
量化(quantization)是一种通过降低数值精度来提高模型推理速度的方法,例如将通常的64位浮点型,转化为8位浮点型进行运算,BERT的量化的基本理论也是如此。
Q-BERT模型微调后的 BERT_BASE 模型同样包含三部分:嵌入、基于 Transformer 的编码器层、输出层。BERT_BASE 模型不同层的参数大小为:嵌入 91MB、编码器 325MB、输出 0.01MB,减少了非常多。
量化过程更多涉及具体的工程化问题,想了解同学可以参考如下的论文了解。
[1] Q8BERT: Quantized 8Bit BERT
[2] Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
总结
BERT模型在多种下游任务表现优异,但庞大的模型结果也带来了训练及推理速度过慢的问题,难以满足对实时响应速度要求高的场景,模型轻量化就显得非常重要。
后续我们分别详细介绍不同类型的BERT模型压缩方法。
下期预告:暂无
知识星球推荐

扫描上面的二维码,就可以加入我们的星球,助你成长为一名合格的自然语言处理算法工程师。
知识星球主要有以下内容:
(1) 聊天机器人。
(2) 知识图谱。
(3) NLP预训练模型。
转载文章请后台联系
侵权必究


往期文章
【完结】 12篇文章带你完全进入NLP领域,掌握核心技术
【年终总结】2019年有三AI NLP做了什么,明年要做什么?
【NLP-词向量】词向量的由来及本质
【NLP-词向量】从模型结构到损失函数详解word2vec
【NLP-NER】什么是命名实体识别?
【NLP-NER】命名实体识别中最常用的两种深度学习模型
【NLP-NER】如何使用BERT来做命名实体识别
【NLP-ChatBot】我们熟悉的聊天机器人都有哪几类?
【NLP-ChatBot】搜索引擎的最终形态之问答系统(FAQ)详述
【NLP-ChatBot】能干活的聊天机器人-对话系统概述
【知识图谱】人工智能技术最重要基础设施之一,知识图谱你该学习的东西
【知识图谱】知识表示:知识图谱如何表示结构化的知识?
【知识图谱】如何构建知识体系:知识图谱搭建的第一步
【知识图谱】获取到知识后,如何进行存储和便捷的检索?
【知识图谱】知识推理,知识图谱里最“人工智能”的一段
【文本信息抽取与结构化】目前NLP领域最有应用价值的子任务之一
【文本信息抽取与结构化】详聊文本的结构化【上】
【文本信息抽取与结构化】详聊文本的结构化【下】
【信息抽取】NLP中关系抽取的概念,发展及其展望
【信息抽取】如何使用卷积神经网络进行关系抽取
【NLP实战】tensorflow词向量训练实战
【NLP实战系列】朴素贝叶斯文本分类实战
【NLP实战系列】Tensorflow命名实体识别实战
【NLP实战】如何基于Tensorflow搭建一个聊天机器人
【NLP实战】基于ALBERT的文本相似度计算