https://www.cnblogs.com/Allen-win/articles/6816376.html
-宝宝为啥听不懂他们在讨论的时间复杂度 0.0
-我怎么知道这个算法运行得比那个算法快 0.0
-我究竟会不会超时0.0
-我为什么还会超时0.0
-时间复杂度怎么算0.0
在别人还不会求时间复杂度的时候而你会了是不是很酷
在别人都会求时间复杂度的时候而你不会是不是很尴尬
千里之行始于足下
希望这篇文章能祝你一臂之力=w=
此篇详解,希望能帮助各位稍微解决一下不解=w=
好的算法应该具备时间效率高和存储量低的特点,这里只介绍前者
一、定义(理解不了没关系,理解得了还写什么博客)
一般情况下,算法中 基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等 于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度(O是数量级的符号 ),简称时间复杂度。
1、咱们来搞懂定义=w=
(1)时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道算法花费的时间多少(魔镜魔镜告诉我,那个算法是跑得快的算法0.0)
一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。
一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)时间复杂度
n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n))
称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
注意,时间频度与时间复杂度是不同的,时间频度不同但时间复杂度可能相同。
如:T(n)=n^2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n^2)。
常见的时间复杂度有:
常数阶O(1)<对数阶O(log2n)<线性阶O(n),<线性对数阶O(nlog2n)
<平方阶O(n^2)<方阶O(n3)
<指数阶O(2^n)

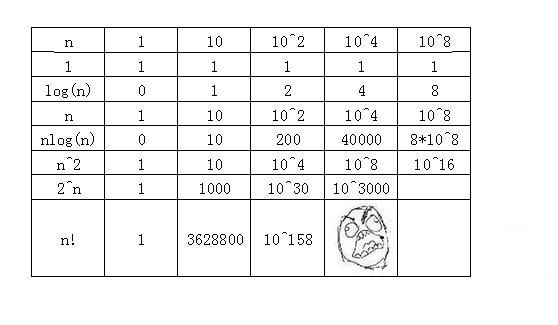
(3)最坏时间复杂度和平均 时间复杂度 最坏情况下的时间复杂度称最坏时间复杂度。一般不特别说明,讨论的时间复杂度均是最坏情况下的时间复杂度。 这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的上界,这就保证了算法的运行时间不会比任何更长。
在最坏情况下的时间复杂度为T(n)=0(n),它表示对于任何输入实例,该算法的运行时间不可能大于0(n)。 平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,算法的期望运行时间。
指数阶0(2n),显然,时间复杂度为指数阶0(2n)的算法效率极低,当n值稍大时就无法应用。
2、最坏时间复杂度和平均时间复杂度
对于时间复杂度的分析,一般是这两种方法:
(1)最坏时间复杂度
最坏情况运行时间(运行时间将不会再坏了=A=)。
通常,除非特别指定,我们提到的运行时间都是最坏情况的运行时间
对于追问为什么是最坏时间复杂度的好奇宝宝:
1、如果最差情况下的复杂度符合我们的要求,我们就可以保证所有的情况下都不会有问题。(完美=w=)
2、也许你觉得平均情况下的复杂度更吸引你(见下),但是:第一,难计算第二,有很多算法的平均情况和最差情况的复杂度是一样的. 第三,而且输入数据的分布函数很可能是你没法知道。
(2)平均时间复杂度
平均时间复杂度也是从概率的角度看,更能反映大多数情况下算法的表现。当然,实际中不可能将所有可能的输入都运行一遍,因此平均情况通常指的是一种数学期望值,而计算数学期望值则需要对输入的分布情况进行假设。平均运行时间很难通过分析得到,一般都是通过运行一定数量的实验数据后估算出来的。
3、闲聊
到此,基本介绍已经完成了=w=,下一部分就是怎么去计算了,
当你看到这里的时候,
你就能明白那些大犇所说的时间复杂度是个什么鬼,
知道哪个算法跑得快也就是择优的标准(虽然你还不会求=。=),
于是你也能知道在数据范围下,大概会选用哪种时间复杂度的方法以及你会不会TLE(虽然你还不会求=。=)
举个栗子(就不给你吃),比如 我要求你在字典里查同一个字,告诉我这个字在字典的那一页。如果一页一页的翻,你需要多少时间呢?最优的情况就是这个字在第一页,最坏的情况就是这个字是 整本字典的最后一个字。所以即使我故意为难你,你也不会花费比找整本字典最后一个字还长的时间。
当然,此时聪明的你就会想用部首、笔画等去查,才不要傻乎乎的一页一页翻,此时的你就会择优选择,因为此时你最坏得情况就是我给你部首笔画最多、除部首外笔画最多的一个超级复杂的一个字,但显然比翻整本字典快得多。
诶呀,一不小心已经不仅会选择而且还会优化了呢=w=
二、求时间复杂度
1、根据定义,可以归纳出基本的计算步骤
(1.)计算出基本操作的执行次数T(n)
基本操作即算法中的每条语句的执行次数一般默认为考虑最坏的情况。
(2)计算出T(n)的数量级
求T(n)的数量级,只要将T(n)进行如下一些操作:
忽略常量、低次幂和最高次幂的系数
令f(n)=T(n)的数量级。
(3)用大O来表示时间复杂度
例:
for(i=1;i<=n;++i)
{
for(j=1;j<=n;++j)
{
c[ i ][ j ]=0; //该步骤属于基本操作 执行次数:n^2
for(k=1;k<=n;++k)
c[ i ][ j ]+=a[ i ][ k ]*b[ k ][ j ]; //该步骤属于基本操作 执行次数:n^3
}
}
则有 T(n)= n^2+n^3,根据上面括号里的同数量级,我们可以确定 n^3为T(n)的同数量级
则有f(n)= n^3,然后根据T(n)/f(n)求极限可得到常数c
则该算法的 时间复杂度:T(n)=O(n^3)
2、于是我们发现根本没必要都算,所以我们有了精简后的步骤:
1.找到执行次数最多的语句
2. 计算语句执行次数的数量级
3. 用大O来表示结果
eg:
(1) for(i=1;i<=n;i++) //循环了n*n次,当然是O(n^2)
for(j=1;j<=n;j++)
s++;
(2)for(i=1;i<=n;i++) //循环了(n+n-1+...+1)≈(n^2)/2 ,同上
for(j=i;j<=n;j++)
s++;
(4) i=1;k=0;
while(i<=n-1){
k+=10*i;
i++; }
//循环了
//n-1≈n次,所以是O(n)
(5) for(i=1;i<=n;i++)
for(j=1;j<=i;j++)
for(k=1;k<=j;k++)
x=x+1;
//循环了(1^2+2^2+3^2+...+n^2)=n(n+1)(2n+1)/6≈(n^3)/3,
//即O(n^3)
(6)
x=91; y=100;
while(y>0) if(x>100) {x=x-10;y--;} else x++;
//T(n)=O(1),与n无关
(7)i=n-1;
while(i>=0&&(A[i]!=k))
i--;
return i;
//此算法中的语句(3)的频度不仅与问题规模n有关,还与输入实例中A的各元素取值及K的取值有关: ①若A中没有与K相等的元素,则语句(3)的频度f(n)=n; ②若A的最后一个元素等于K,则语句(3)的频度f(n)是常数0。
综上:
1、取决于执行次数最多的语句,如当有若干个循环语句时,算法的时间复杂度是由嵌套层数最多的循环语句中最内层语句的频度f(n)决定的。
2、如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)
3、算法的时间复杂度不仅仅依赖于问题的规模,还与输入实例的初始状态有关。
3、闲聊
好了,到此为止,你已经会了求时间复杂的基本方法,可以找出你手中的代码去求一下就当练习了
读到这里,考试时或平时应用时便能判断出你所采用的算法会不会TLE,不再是感觉一定正确的算法结果TLE的一脸震惊和大写的生无可恋而是一脸胸有成竹的自信和“我就知道是这样”的淡定。
这个时候我再让你去那个字在哪页的时候你就会选择一种简约时尚有内涵的方法,并且对你需要做多少步、翻多少页能做到心中有数,而不是累死累活的一页一页翻一边翻还一边画个圈圈诅咒我=。=(怪我喽)
——by Eirlys
转自:http://blog.csdn.net/eirlys_north/article/details/52959540