
java爬虫&html解析-Jsoup(绿盟极光报告)
一、类库选取
Java爬虫解析HTML文档的工具有:htmlparser, Jsoup。
主要是实现的功能需求,选取Jsoup,对html进行解析,爬去数据。
Jsoup可以直接解析某个URL地址、HTML文本内容,它提供非常丰富的处理Dom树的API。
Jsoup最强大的莫过于它的CSS选择器支持:
例如:document.select("div.content > div#image > ul > li:eq(2)
二、包引入方法
https://mvnrepository.com/artifact/org.jsoup/jsoup/1.12.2

可以通过maven在pom.xml添加
还可以下载jar包直接添加到项目里面
三、Jsoup解析方法
Jsoup支持四种方式解析Document,即可以输入四种内容得到一个Document:
解析字符串
解析body片段
从一个URL解析
从一个文件解析
字符串解析
字符串中必须包含head和body元素。
String html = "
Parsed HTML into a doc.
"; Document doc = Jsoup.parse(html);HTML片段解析
String html = "
Lorem ipsum.
"; Document doc = Jsoup.parseBodyFragment(html); Element body = doc.body();URL解析
Document doc = Jsoup.connect("http://example.com/").get(); String title = doc.title();
还可以携带cookie等参数:(和Python的爬虫类似)
Document doc = Jsoup.connect("http://example.com") .data("query", "Java") .userAgent("Mozilla") .cookie("auth", "token") .timeout(3000) .post();
本地文件解析
File input = new File("/tmp/input.html"); Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
本次的项目需求是本地的文件解析
重新编写一下文件读取方法:
/** * 提取文件里面的文本信息 */ public static String openFile(String szFileName) { try { BufferedReader bis = new BufferedReader(new InputStreamReader(new FileInputStream(new File(szFileName)), ENCODE)); String szContent = ""; String szTemp; while ((szTemp = bis.readLine()) != null) { szContent += szTemp + "\n"; } bis.close(); return szContent; } catch (Exception e) { return ""; } }
四、Jsoup遍历DOM树的方法
使用标准的DOM方法
根据id查找元素: getElementById(String id) 根据标签查找元素: getElementsByTag(String tag) 根据class查找元素: getElementsByClass(String className) 根据属性查找元素: getElementsByAttribute(String key) 兄弟遍历方法: siblingElements(), firstElementSibling(), lastElementSibling(); nextElementSibling(), previousElementSibling() 层级之间遍历: parent(), children(), child(int index)
些方法会返回Element或者Elements节点对象,这些对象可以使用下面的方法获取一些属性:
attr(String key): 获取某个属性值 attributes(): 获取节点的所有属性 id(): 获取节点的id className(): 获取当前节点的class名称 classNames(): 获取当前节点的所有class名称 text(): 获取当前节点的textNode内容 html(): 获取当前节点的 inner HTML outerHtml(): 获取当前节点的 outer HTML data(): 获取当前节点的内容,用于script或者style标签等 tag(): 获取标签 tagName(): 获取当前节点的标签名称 有了这些API,就像JQuery一样很便利的操作DOM。
强大的CSS选择器支持
htmlparse支持xpath,可以很方便的定位某个元素,而不用一层一层地遍历DOM树。调用方法如下: document.select(String selector): 选择匹配选择器的元素,返回是Elements对象 document.selectFirst(String selector): 选择匹配选择器的第一个元素,返回是一个Element对象 element.select(String selector): 也可以直接在Element对象上执行选择方法 Jsoup能够完美的支持CSS的选择器语法,可以说对应有前端经验的开发者来说简直是福音,不用特意去学习XPath的语法。
下面列出一些常见的选择器:
标签选择(如div): tag id选择(#logo): #id class选择(.head): .class 属性选择([href]): [attribute] 属性值选择: [attr=value] 属性前缀匹配: [^attr] 属性简单正则匹配: [attr^=value], [attr$=value], [attr*=value], [attr~=regex]
另外还支持下面的组合选择器:
element#id: (div#logo: 选取id为logo的div元素) element.class: (div.content: 选择class包括content的div元素) element[attr]: (a[href]: 选择包含href的a元素) ancestor child: (div p: 选择div元素的所有p后代元素) parent > child: (p > span: 选择p元素的直接子元素中的span元素) siblingA + siblingB: (div.head + div: 选取div.head的下一个兄弟div元素) siblingA ~ siblingX: (h1 ~ p: 选取h1后面的所有p兄弟元素) el, el, el: (div.content, div.footer: 同时选取div.content和div.footer)
还支持伪元素选择器:
:lt(n): (div#logo > li:lt(2): 选择id为logo的div元素的前3个li子元素) :gt(n) :eq(n) :has(selector) :not(selector) :contains(text)
Jsoup修改DOM树结构
Jsoup还支持修改DOM树结构,真的很像JQuery。
// 设置属性 doc.select("div.comments a").attr("rel", "nofollow"); // 设置class doc.select("div.masthead").attr("title", "jsoup").addClass("round-box");
下面的API可以直接操作DOM树结构:
text(String value): 设置内容 html(String value): 直接替换HTML结构 append(String html): 元素后面添加节点 prepend(String html): 元素前面添加节点 appendText(String text), prependText(String text) appendElement(String tagName), prependElement(String tagName)
五、项目实战(绿盟扫描器结果html数据爬虫整理)
获取2.1 漏洞概况数据获取
//绿盟扫描结果
public static Listgetlist1(Document doc, String ip){
//获取2.1 漏洞概况
//System.out.println(doc+"---------");
Elements elList=doc.getElementsByAttributeValue("id","vuln_list");
if(!elList.isEmpty()) {
Element el=elList.first();
Elements trLists = el.select("tr");//获取第一个tr
//System.out.println(doc+"---------");
for (int i = 0; i < trLists.size(); i++) {
Elements tds = trLists.get(i).select("td");//获取td标签
for (int j = 0; j < tds.size() - 1; j++) {
String text = tds.get(j).text();
}
}
}
}
}
获取2.2 漏洞详情数据获取
blic static Listgetlist2(Document doc){
//获取2.2 漏洞详情
ListcList2 = new ArrayList();//获取相关的漏洞表述和CVSS数值
ListcList3 = new ArrayList();//获取漏洞的名称
ListcList4 = new ArrayList();//最后获取完整的 漏洞名称、漏洞描述、整改方法、CVSS评分
Listlist3 = new ArrayList();//对应漏洞和漏洞描述和CVSS评分的数组
Elements elList1=doc.getElementsByAttributeValue("id","vul_detail");//获取 2.2大模块的全部代码
Element el1 = elList1.first();
Elements trLists1 = el1.select("tr");//抽取其中的tr标签
//根据tr和td的循环获取 漏洞描述、整改方法、CVSS评分
for (int i = 0; i < trLists1.size(); i++) {
Elements tds1 = trLists1.get(i).select("td");
for (int j = 0; j < tds1.size(); j++) {
//Elements trLists2 = el1.select("[data-port]");
for (int u = 0; u < trLists2.size(); u++) {
rsas_scan2 = new RSAS_scan2();//防止list类方法添加数据出现最后一行
rsas_scan2.setAsset_name(trLists2.get(u).text());
}
}
}
}
最后数据汇总关联处理:
public Object Scan(String path1) throws Excel4JException, IOException {
List
String path = path1+"/";
File file = new File(path);
File[] files = file.listFiles();
List
for (File hosts : files) {
String szContent = openFile(path + hosts.getName());
try {
Document doc = Jsoup.parse(szContent);
//获取本IP地址
String ip = hosts.getName().replace(".html", "");
System.out.println("\n"+ip);
//获取2.1 漏洞概况输出
List
//获取2.2 漏洞详情
List
//data1和data2通过漏洞名称关联 遍历匹配输出
for (int da1 = 0; da1 < data1.size(); da1++) {
for (int da2 = 0; da2 < data2.size(); da2++) {
rsas_total = new RSAS_total();
rsas_total.setIp(data1.get(da1).getIp());
rsas_total.setAsset_point(data1.get(da1).getAsset_point());
rsas_total.setAsset_name(data1.get(da1).getAsset_name());
rsas_total.setAsset_description(data2.get(da2).getAsset_description());
}
}
} catch(Exception e){
e.printStackTrace();
}
}
}
System.out.println("------------------Finished-详情查看-绿盟扫描结果.xlsx------------------");
//Excel无模版导出
Excel.getInstance().exportObjects(rsas_totals, RSAS_total.class, true, null, true, "绿盟扫描结果.xlsx");
}
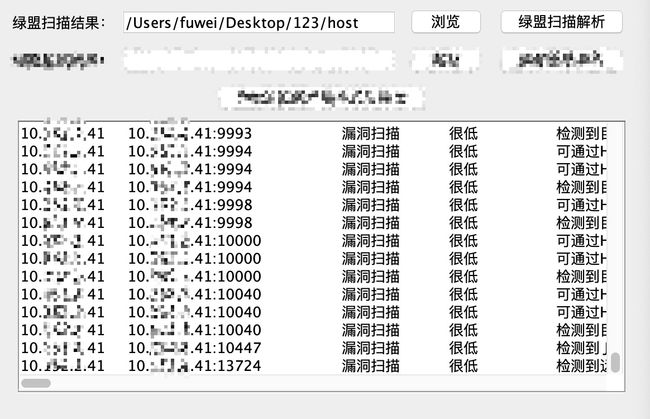
运行效果:
GUI界面化:
Console打印输出:

同时导出到excel

六、总结:
1、数据获取过程中的问题:
A、Java的Jsoup爬去html的选择器在选择的时候,选取的是一个集合,需要设置不同的类去来存储这个集合的不同地方对应的值。有的时候需要多层的数据嵌套循环选择。
B、还有就是数据的父节点和子节点的承继关系,在不同的区域选取,怎么讲数据关联。(对比python爬虫,Java的爬虫比较冗余一些,倒是Java的代码复用率高,尤其是相同模块,可以拆分不同的模块,处理不同的数据,Java的不同的类封装,再嵌套实现,python一个页面写一个。)
2、感悟:
如果是爬虫还是python轻量便捷,如果设计到对模块重复使用,还有重复关联数据交叉较大,建议使用java来实现,Swing的Gui开发也比较便捷。
七、参考文献:
https://www.cnblogs.com/youyoui/p/11065923.html
https://blog.csdn.net/lxacdf/article/details/73200906
https://www.cnblogs.com/shaosks/p/9625878.html
https://blog.csdn.net/qq_39569480/article/details/93980313
公众号:

thelostworld:

个人知乎:https://www.zhihu.com/people/fu-wei-43-69/columns
个人:https://www.jianshu.com/u/bf0e38a8d400