关于caffe中的blob结构及卷积计算汇总
传送门:根据博主这篇文章汇总:http://www.cnblogs.com/zjutzz/p/5960289.html
关于caffe中的blob结构及卷积计算
blob是caffe中的基本数据结构,简单理解就是一个“4维数组”。但是,这个4维数组有什么意义?
TensorFlow这款google出的框架,带出了tensor(张量)的概念。虽然是数学概念,个人还是倾向于简单理解为“多维数组”,那么放在这里,caffe的blob就相当于一个特殊的tensor了。而矩阵就是二维的张量。
首先,看看blob的4个维度:
num: 图像数量
channel:通道数量
width:图像宽度
height:图像高度
caffe中默认使用的SGD随机梯度下降,其实是mini-batch SGD
每个batch,就是一堆图片。这一个batch的图片,就存储在一个blob中。
当然,blob并不是这么受限的、专门给batch内的图片做存储用的。实际上,参数、梯度,也可以用blob存储的。只要是caffe的网络中传递的数据,都可以用blob存储。
而且,blob实际上也并不一定是4维的。它在实现上其实就是1维的指针,而我们作为用户感受到的“多个维度”是通过shape来操作的。
在用faster-rcnn训练的时候使用了ZF网络,有篇博客写到(下面有传送门)
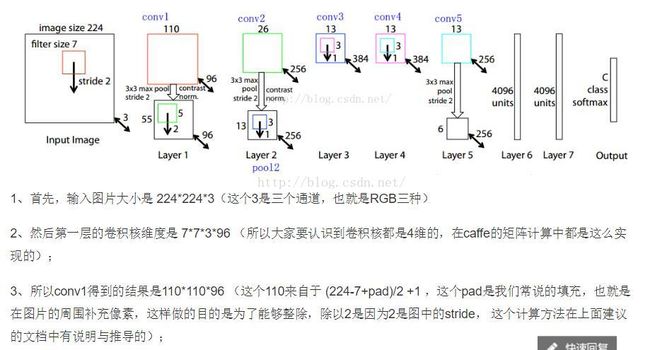
参考博客:http://blog.csdn.net/sloanqin/article/details/51545125
卷积之后有一个∑和sigmoid的两个过程,前者是累加,后者是映射到0-1之间。具体到faster-rcnn,∑对应的就是:各个通道上对应位置做累加;而激活函数使用的应该是ReLU。anyway,这里的累加和激活函数处理后,通道数就变成了一个;也就是,对于一个滤波器,滑窗滤波+累加、激活函数后,得到的一个feature map。
具体点说,这里的滤波器(卷积核),是3维的,(Width,Height,Channel)这样;我们用它在一个feature map上按滑窗方式做卷积,其实是所有Channel上同时做sliding window的操作;每个sliding windows位置上,所有通道卷积的结果累加起来,再送给激活函数ReLU处理,就得到结果feature map中的一个像素的值。
值得注意的是,滤波器的通道数量,和要处理的feature map的通道数量,其实可以不一样的,可以比feature map维度少一点,这相当于可以自行指定要选取feature map中的某些channel做卷积操作,相当于有一个采样的过程,甚至可以仅仅使用一个channel的卷积结果。
参考博客:http://blog.csdn.net/u014114990/article/details/51125776
总结
1. 在caffe中,Blob类型是(Width,Height,Channel,Number)四元组,表示宽度、高度、通道数量、数量
2. 图像本身、feature map、滤波器(kernel),都可以看做是Blob类型的具体例子
3. 一个“层”,可以理解为执行相应操作后,得到的结果。比如,执行卷积操作,得到卷积层;执行全连接操作,得到全连接层。通常把池化层归属到卷积层里面。池化就是下采样的意思,有最大池化和平均池化等。
4. 对于一个卷积层,其处理的“输入”是多个feature maps,也就是一个Blob实例:(H1,W1,C1,N1),比如(224,224,3,5),表示5张图像(这里的5,可以认为是一个minibatch的batch size,即图片数量)
卷积操作需要卷积核的参与,卷积核也是Blob的实例:(H2,W2,C2,N2),比如(7,7,3,96),表示有96个卷积核,每个卷积核是一个3维的结构,是7x7的截面、3个通道的卷积核
卷积层的输出也是若干feature maps,也是一个Blob实例:(H3,W3,C3,N3),是根据输入的feature maps和指定的卷积核计算出来的。按上面的例子,得到feature map的Blob描述为(110,110,96,5),表示有5个feature maps,每个feature map是110x110x96大小。
通常可以这样理解:卷积核的个数,作为结果feature maps中的通道数量。
关于Caffe中Blob卷积计算实现:
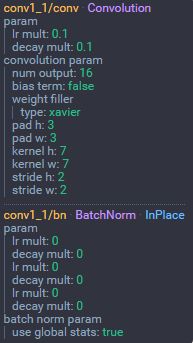
列出各个参数
Caffe中的卷积计算是将卷积核矩阵和输入图像矩阵变换为两个大的矩阵A与B,然后A与B进行矩阵相乘得到结果C(利用GPU进行矩阵相乘的高效性)

三个矩阵的说明如下:
(1)在矩阵A中
M为卷积核个数,K=k*k,等于卷积核大小,即第一个矩阵每行为一个卷积核向量(是将二维的卷积核转化为一维),总共有M行,表示有M个卷积核。
(2)在矩阵B中
N=((image_h + 2*pad_h – kernel_h)/stride_h+ 1)*((image_w +2*pad_w – kernel_w)/stride_w + 1)
image_h:输入图像的高度
image_w:输入图像的宽度
pad_h:在输入图像的高度方向两边各增加pad_h个单位长度(因为有两边,所以乘以2)
pad_w:在输入图像的宽度方向两边各增加pad_w个单位长度(因为有两边,所以乘以2)
kernel_h:卷积核的高度
kernel_w:卷积核的宽度
stride_h:高度方向的滑动步长;
stride_w:宽度方向的滑动步长。
因此,N为输出图像大小的长宽乘积,也是卷积核在输入图像上滑动可截取的最大特征数。
K=k*k,表示利用卷积核大小的框在输入图像上滑动所截取的数据大小,与卷积核大小一样大。
(3)在矩阵C中
矩阵C为矩阵A和矩阵B相乘的结果,得到一个M*N的矩阵,其中每行表示一个输出图像即feature map,共有M个输出图像(输出图像数目等于卷积核数目)
(在Caffe中是使用src/caffe/util/im2col.cu中的im2col和col2im来完成矩阵的变形和还原操作)
参考知乎:https://www.zhihu.com/question/28385679
比较简单的理解就是下面这个
使用im2col的方法将卷积转为矩阵相乘
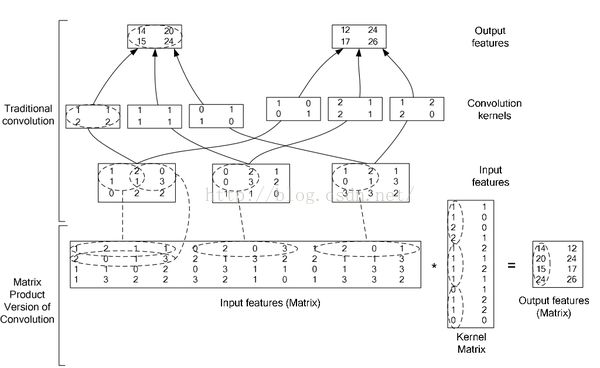
参见论文:
High Performance Convolutional Neural Networks for Document Processing
https://hal.archives-ouvertes.fr/file/index/docid/112631/filename/p1038112283956.pdf