决策树结合网格搜索交叉验证的例子
决策树结合网格搜索交叉验证
如下是常见的模型评估的指标定义及决策树结合网格搜索交叉验证的例子。详见下文:
混淆矩阵:
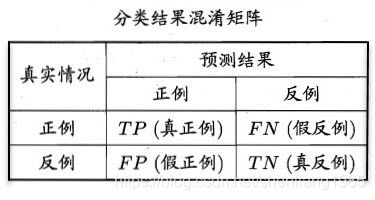
准确率:

精准率(预测为正样本真实也是正例的比值,又称为查准率):

召回率(真实为正例的样本中预测为正例的比值,又称为查全率):
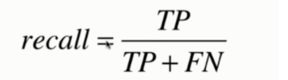
F1 Socre (反映模型的稳健型):

###as_matrix
import pandas as pd
from sklearn import tree
from sklearn.tree import export_graphviz
import graphviz
def decisontreeSimple():
filename= '../input/sales_data.xls'
data = pd.read_excel(filename,index_col=u'序号')
##print(data)
data[data == u'好'] = 1
data[data==u'是'] = 1
data[data==u'高'] = 1
data[data!=1] = -1
x= data.iloc[:,:3].values.astype(int)
y= data.iloc[:,3].values.astype(int)
import sklearn.model_selection as cross_validation
train_data, test_data, train_target, test_target = cross_validation.train_test_split(x, y, test_size=0.3,
train_size=0.7,
random_state=67897) # 划分训练集和测试集
from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion='entropy')
dtc.fit(train_data, train_target)
'''
train_est = dtc.predict(train_data) # 用模型预测训练集的结果
train_est_p = dtc.predict_proba(train_data)[:, 1] # 用模型预测训练集的概率
test_est = dtc.predict(test_data) # 用模型预测测试集的结果
test_est_p = dtc.predict_proba(test_data)[:, 1] # 用模型预测测试集的概率
res_pd = pd.DataFrame({'test_target': test_target, 'test_est': test_est, 'test_est_p': test_est_p}).T # 查看测试集预测结果与真实结果对比
pd.set_option('precision', 2)
pd.set_option('max_colwidth', 20)
pd.set_option('display.max_columns', 20)
print(res_pd)
import sklearn.metrics as metrics
print(metrics.confusion_matrix(test_target, test_est, labels=[0, 1])) # 混淆矩阵
print(metrics.classification_report(test_target, test_est)) # 计算评估指标
print(pd.DataFrame(list(zip(data.columns, dtc.feature_importances_)))) # 变量重要性指标
'''
import sklearn.metrics as metrics
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
import sklearn.tree as tree
param_grid = {
'criterion': ['entropy','gini'],
'max_depth': [3, 4, 5, 6, 7, 8],
'min_samples_split': [4,5,6,7,8,9, 12, 16, 20, 24]
}
clf = tree.DecisionTreeClassifier(criterion='entropy')
clfcv = GridSearchCV(estimator=clf, param_grid=param_grid,
scoring='roc_auc', cv=4)
clfcv.fit(train_data, train_target)
# %%
# 查看模型预测结果
train_est = clfcv.predict(train_data) # 用模型预测训练集的结果
train_est_p = clfcv.predict_proba(train_data)[:, 1] # 用模型预测训练集的概率
test_est = clfcv.predict(test_data) # 用模型预测测试集的结果
test_est_p = clfcv.predict_proba(test_data)[:, 1] # 用模型预测测试集的概率
# %%
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_est_p)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_est_p)
plt.figure(figsize=[6, 6])
plt.plot(fpr_test, tpr_test, color='blue')
plt.plot(fpr_train, tpr_train, color='red')
plt.title('ROC curve')
plt.show()
print(clfcv.best_params_)
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=3, min_samples_split=6) # 当前支持计算信息增益和GINI
clf.fit(train_data, train_target) # 使用训练数据建模
'''
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
x = pd.DataFrame(x)
print(x)
with open("../output/tree.dot",'w') as f:
f= export_graphviz(dtc,feature_names=x.columns,out_file=f)
'''
x = pd.DataFrame(x,columns=[u"weather",u"weekend",u"promotion"])
#x = pd.DataFrame(x)
dot_data = export_graphviz(dtc,feature_names=x.columns,out_file=None)
graph = graphviz.Source(dot_data)
''' dot文件里追加中文字体支持,需要手动编辑该文件
graph [bb="0,0,712,365"];下面追加
edge[fontname = "SimHei"];
node[fontname = "SimHei"];
'''
##graph.render(filename="../output/tree",format="dot",cleanup="False")
##直接转PDF会有乱码
##graph.render(filename="../output/tree",format="pdf",cleanup="False")
'''或者直接执行,但是需要先dot配置环境变量'''
import os
os.system('dot -Tpdf "../output/tree33.dot" -o "../output/tree33.pdf"')
'''或者直接执行'''
#with open("../output/tree.dot",'w') as f:
# f = export_graphviz(dtc,feature_names=x.columns,out_file=f)
with open("../output/tree33.dot",'w') as f:
f = export_graphviz(clf,feature_names=x.columns,out_file=f)
##代码参考至<>
def decisontreeTitanic():
##titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
titanic = pd.read_csv('../input/titanic.txt')
print("行数:"+str(titanic.shape[0])+"\t"+"列数:"+str(titanic.shape[1])+"\t"+"行数:"+str(len(titanic))+"\t"+"总数:"+str(titanic.size))
'''
row.names pclass survived name age embarked home.dest room ticket boat sex
序号 乘客等级 获救情况 姓名 年龄 登船港口 目的地 房间号 船票信息 票价 性别
'''
#print(titanic[:7])
#print(titanic.info())
X = titanic[['pclass','age','sex']]
y = titanic['survived']
print(X[X['age'].notnull()]['age'].sum()/X[X['age'].notnull()].shape[0]) #19745.9166/636
#X=X['age'].fillna(X['age'].mean(),inplace=True)
#cc1 = X['age'].fillna(age_mean, inplace=True)
#print(cc1)
#X.info()
X= X.copy() #要先拷贝,然后再进行fillna操作。
X['age'].fillna(X['age'].mean(), inplace=True)
print(X[:20])
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.01,random_state=33)
print(X_test)
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
##转换特征后,类别型特征都被剥离出单独的特征,数值型的保持不变
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
print(vec.feature_names_)
X_test = vec.fit_transform(X_test.to_dict(orient='record'))
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(X_train,y_train)
y_predict = dtc.predict(X_test)
#y_pd = pd.concat(pd.DataFrame([X_test]),pd.DataFrame([y_predict]),axis=1)
print(y_predict)
print(type(y_predict))
#import numpy as np
#print(np.concatenate((X_test,y_predict),axis=1))
X_test_df = pd.DataFrame(X_test)
y_predict_df = pd.DataFrame(y_predict)
print("################")
#print(pd.concat([X_test_df,y_predict_df],axis=0))
'''print(X_test.ndim )
print(y_predict.ndim)'''
''' 如果对所有字段都应用这个规则,可以沿用如下写法
for column in list(X.columns[X.isnull().sum() > 0]):
mean_val = X[column].mean()
X[column].fillna(mean_val, inplace=True)'''
###模型评估
from sklearn.metrics import classification_report
print(dtc.score(X_test,y_test))
print(classification_report(y_predict,y_test,target_names=['died','survived']))
def irisdt():
from sklearn import tree
from sklearn import model_selection
from sklearn.datasets import load_iris
#from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
iris = load_iris()
x = iris.data
y = iris.target
X_train, X_test, y_train, y_test = model_selection \
.train_test_split(x, y, test_size=0.2,
random_state=123456)
parameters = {
'criterion': ['gini', 'entropy'],
'max_depth': range(1,30),#[1, 2, 3, 4, 5, 6, 7, 8,9,10],
'max_leaf_nodes': [2,3,4, 5, 6, 7, 8, 9] #最大叶节点数
}
dtree = tree.DecisionTreeClassifier()
grid_search = GridSearchCV(dtree, parameters, scoring='accuracy', cv=5)
grid_search.fit(x, y)
print(grid_search.best_estimator_) # 查看grid_search方法
print(grid_search.best_score_) # 正确率
print(grid_search.best_params_) # 最佳 参数组合
dtree = tree.DecisionTreeClassifier(criterion='gini', max_depth=3)
dtree.fit(X_train, y_train)
pred = dtree.predict(X_test)
print(pred)
print(y_test)
print(classification_report(y_test, pred,target_names=['setosa', 'versicolor', 'virginica']))
print(dtree.predict([[6.9,3.3,5.6,2.4]]))#预测属于哪个分类
print(dtree.predict_proba([[6.9,3.3,5.6,2.4]])) # 预测所属分类的概率值
##print(iris.target)
print(list(iris.target_names)) #输出目标值的元素名称
#print(grid_search.estimator.score(y_test, pred))
def irisdecisontree():
from sklearn import datasets
iris = datasets.load_iris()
X_train = iris.data[:,[0,1]][0:150]
y_train = iris.target
#print(iris.feature_names)
#print(type(X_train))
##print(X_train[:,[0,1]][0:150])
clf = tree.DecisionTreeClassifier(max_depth=3,criterion='entropy')
clf = clf.fit(X_train, y_train)
with open("../output/iristree.dot",'w') as f:
f = export_graphviz(clf,feature_names=['sepallength','sepalwidth'],out_file=f)
import os
os.system('dot -Tpdf "../output/iristree.dot" -o "../output/iristree.pdf"')
def kfolddemo():
'''
1 shuffle=True结合random_state=整数 等效于shuffle=False 即出来的顺序不变
2 验证集和训练集的比例大于1:8 小于1:2
'''
from numpy import array
from sklearn.model_selection import KFold
# data sample
data = array([0.1, 0.2, 0.3, 0.4, 0.5,0.6,0.7,0.8,0.9])
# prepare cross validation
kfold = KFold(n_splits=5, shuffle=True)
# enumerate splits
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train], data[test]))
if __name__ == '__main__':
##decisontreeSimple()
##decisontreeTitanic()
##irisdecisontree()
irisdt()
##kfolddemo() 运行结果:
"D:\Program Files\Python37\python.exe" "E:/Decision tree/decisiontree.py"
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=3,
max_features=None, max_leaf_nodes=6,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
0.9733333333333334
{'criterion': 'gini', 'max_depth': 3, 'max_leaf_nodes': 6}
[0 2 0 1 0 0 2 2 2 0 1 2 2 0 0 2 1 2 1 0 1 2 1 1 1 2 2 2 1 1]
[0 2 0 1 0 0 2 2 2 0 1 2 2 0 0 2 1 2 1 0 1 2 1 1 1 2 2 2 2 1]
precision recall f1-score support
setosa 1.00 1.00 1.00 8
versicolor 0.90 1.00 0.95 9
virginica 1.00 0.92 0.96 13
accuracy 0.97 30
macro avg 0.97 0.97 0.97 30
weighted avg 0.97 0.97 0.97 30
[2]
[[0. 0. 1.]]
['setosa', 'versicolor', 'virginica']
Process finished with exit code 0