NTT Masque: 多风格生成式阅读理解(Multi-Style Generative Reading Comprehension)
文章目录
- 问题形式化
- 提出的模型
- 问句-段落阅读器(Question-Passages Reader)
- 词向量层
- 共享编码层
- 双重注意力
- 建模编码层
- 段落排序(Passage Ranker)
- 可问答分类器(Answer Possibility Classifier)
- 答案句解码器(Answer Sentence Decoder)
- 词向量层
- 注意力解码器层
- 多源指针生成器
- 损失函数
- 附录:实验数据
【Reference】
1. Multi-Style Generative Reading Comprehension
2. 论文笔记–Multi-Style Generative Reading Comprehension (Masque)
截止2020年8月21日,本文提出的Masque模型是在MS MARCO和NarrativeQA数据集上表现最好的模型。
RC研究领域多使用范围抽取式方法,生成式方法面临开放领域训练数据匮乏。本文提出多风格问答阅读理解摘要模型,从问句和多个段落生成指定风格的summary作为答案。
- 多源摘要: 使用指针生成器机制从问句、多段落中生成多样化风格的答案,并扩展至Transformer,允许生成器从词表,或从问句、段落原文中以复制方式生成答案;
- 多风格学习: 控制答案输出样式,满足RC所有形式输出,引入风格化的人工token扩展指针生成器为条件解码器,给定风格下,每一步解码控制三个分布占解码输出的权重;
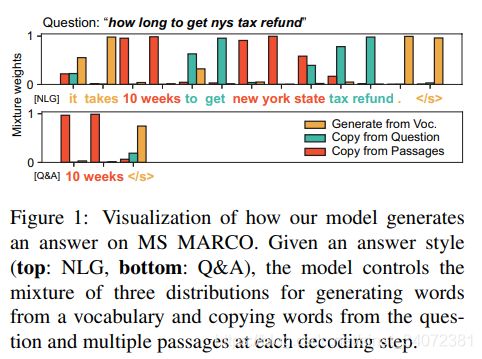
问题形式化
给定含 J J J个单词的问句 x q = { x 1 q , ⋯ , x J q } x^q=\{x_1^q,\cdots,x_J^q\} xq={x1q,⋯,xJq}, K K K个段落,其中第 k k k个段落包含 L L L个单词,表示为 x p k = { x 1 p k , ⋯ , x L p k } x^{p_k}=\{x_1^{p_k},\cdots,x_L^{p^k}\} xpk={x1pk,⋯,xLpk},风格标签 s s s,RC模型输出答案 y = { y 1 , ⋯ , y T } y=\{y_1,\cdots,y_T\} y={y1,⋯,yT}。
模型简化为:给定三元组 ( x q , { x p k } , s ) (x^q,\{x^{p_k}\},s) (xq,{xpk},s),模型预测输出 P ( y ) P(y) P(y)。训练数据具有6个三元组: ( x q , { x p k } , s , y , a , { r p k } ) (x^q,\{x^{p_k}\},s,y,a,\{r^{p_k}\}) (xq,{xpk},s,y,a,{rpk}),其中 a a a和 { r p k } \{r_{p_k}\} {rpk}可选, a = 1 a=1 a=1表示问句可以回答, r p k = 1 r^{p_k}=1 rpk=1表示段落对回答问句有效。
提出的模型
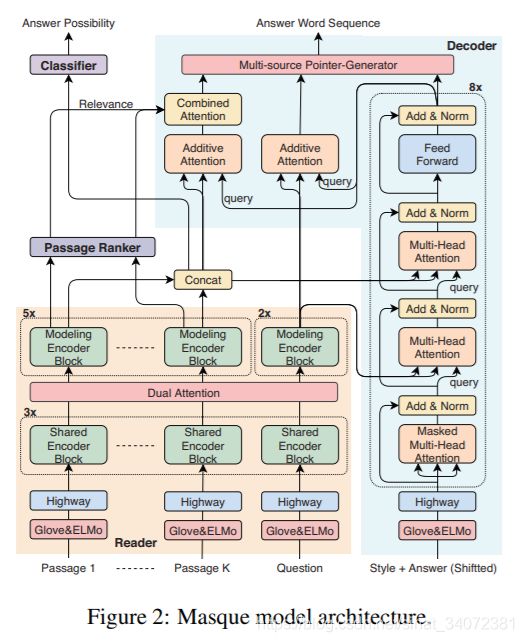
多风格问答摘要模型 Masque,直接建模条件概率 p ( y ∣ x q , { x p k } , s ) p(y|x^q,\{x^{p_k}\},s) p(y∣xq,{xpk},s),模型结构如上,包含:
- 问句-段落阅读器,建模问句和段落之间的交互;
- 段落排序,找到与问句相关的段落;
- 可问答二分类器,识别问句是否可回答;
- 答案句编码器,输出给定风格下的答案;
模型基于多任务学习:段落排序、可回答二分类器、NLG,NLG的学习具有风格独立性,并可将其输出转化为目标风格。
问句-段落阅读器(Question-Passages Reader)
词向量层
分别得到问句和段落中各词的预训练Glove词向量和具有上下文表示的ELMo词向量,使用两层Highway Network(问句和段落参数共享)融合两种词向量。
共享编码层
使用问句和段落各词在堆叠Transformer的顶层输出作为各单词的词向量表示,首层是将词向量线性变换 d d d维,编码器共享层输出段落词向量 E p k ∈ R d × L E^{p_k}\in\R^{d\times L} Epk∈Rd×L和问句词向量 E q ∈ R d × J E^q\in\R^{d\times J} Eq∈Rd×J。
编码器块由两个子层构成:多头自注意力层和位置感知前馈网络层。
与GPT模型一致,前馈网络由使用GELU激活函数连接的两层线性网络构成。每个子层内部使用残差连接(所有子层网络输出维度均为 d d d维)和层标准化,如给定输入 x x x和子层网络函数 f f f,则子层网络输出 LN ( f ( x ) + x ) \text{LN}(f(x)+x) LN(f(x)+x)。
由于词向量使用ELMo词向量,本身具有位置信息,因此本文模型中不使用位置嵌入。
双重注意力
使用双重注意力,融合问句表示和段落表示的彼此信息。
首先计算问句和每个段落的相似度矩阵 U p k ∈ R L × J U^{p_k}\in\R^{L\times J} Upk∈RL×J,其中第 k k k个段落的第 l l l个单词与问句的第 j j j个单词的相似度为
U i j p k = w q ⊤ [ E l p k ; E j q ; E l p k ⊙ E j q ] U_{ij}^{p_k}=w^{q\top}[E_l^{p_k};E_j^q;E_l^{p_k}\odot E_j^q] Uijpk=wq⊤[Elpk;Ejq;Elpk⊙Ejq]
参数 w a ∈ R 3 d w^a\in\R^{3d} wa∈R3d, ⊙ \odot ⊙表示Hadamard product(对应元素相乘), ; ; ;表示按行拼接。接着按行标准化(段落不同单词对问句同一单词的注意力)相似矩阵、按列标准化(问句不同单词对段落同一单词的注意力)相似矩阵:
A p k = softmax j ( U p k ⊤ ) , B p k = softmax l ( U p k ) A^{p_k}=\text{softmax}_j(U^{p_k\top}),\quad B^{p_k}=\text{softmax}_l(U^{p_k}) Apk=softmaxj(Upk⊤),Bpk=softmaxl(Upk)
使用Dynamic Coattention Networks, DCN,获取段落词向量的双重注意力表示 G q → p k ∈ R 5 d × L G^{q\to p_k}\in\R^{5d\times L} Gq→pk∈R5d×L,问句词向量的双重注意力表示 G p → q ∈ R 5 d × J G^{p\to q}\in\R^{5d\times J} Gp→q∈R5d×J:
G q → p k = [ E p k ; A ˉ p k ; A ^ p k ; E p k ⊙ A ˉ p k ; E p k ⊙ A ^ p k ] G p → q = [ E q ; B ˉ ; B ^ ; E q ⊙ B ˉ ; E q ⊙ B ^ ] \begin{aligned} G^{q\to p_k}&=[E^{p_k};\bar A^{p_k};\hat A^{p_k};E^{p_k}\odot \bar A^{p_k};E^{p_k}\odot \hat A^{p_k}]\\[.5ex] G^{p\to q}&=[E^q;\bar B;\hat B;E^q\odot\bar B;E^q\odot\hat B] \end{aligned} Gq→pkGp→q=[Epk;Aˉpk;A^pk;Epk⊙Aˉpk;Epk⊙A^pk]=[Eq;Bˉ;B^;Eq⊙Bˉ;Eq⊙B^]
以下各矩阵列向量的含义:
- E p k E^{p_k} Epk,段落各位置词向量;
- A ˉ p k = E q A p k \bar A^{p_k}=E^qA^{p_k} Aˉpk=EqApk,段落各位置attention的问句词向量;
- B ˉ p k = E p k B p k \bar B^{p_k}=E^{p_k}B^{p_k} Bˉpk=EpkBpk,问句各位置attention的段落词向量;
- A ^ p k = B ˉ p k A p k \hat A^{p_k}=\bar B^{p_k}A^{p_k} A^pk=BˉpkApk,段落各位置attention的段落词向量,即根据问句信息融入上下文信息的段落词向量;
- B ^ p k = A ˉ p k B p k \hat B^{p_k}=\bar A^{p_k}B^{p_k} B^pk=AˉpkBpk,问句各位置attention的问句词向量,即根据段落信息融入上下文信息的问句词向量;
- B ˉ = max k B ˉ p k \bar B=\max_k\bar B^{p_k} Bˉ=maxkBˉpk,问句各位置的最大池化不同段落的段落词向量;
- B ^ = max k B ^ p k \hat B=\max_k\hat B^{p_k} B^=maxkB^pk;问句各位置的最大池化不同段落的问句词向量;
建模编码层
使用堆叠的5层和2层的Transformer编码块分别作为段落、问句编码器,编码段落词向量表示 M p k ∈ R d × L M^{p_k}\in\R^{d\times L} Mpk∈Rd×L,问句词向量表示 M q ∈ R d × J M^q\in\R^{d\times J} Mq∈Rd×J。 M q M^q Mq和 M p k M^{p_k} Mpk用于答案解码, { M p k } \{M^{p_k}\} {Mpk}用于段落排序和可问答分类。
段落排序(Passage Ranker)
各段落词向量表示为 { M p k } \{M^{p_k}\} {Mpk},使用各分段的第一个单词词向量 M 1 p k M_1^{p_k} M1pk作为分段词向量表示,引入参数向量 w r ∈ R d w^r\in\R^d wr∈Rd,计算各段落与问句的相关性:
β p k = sigmoid ( w r ⊤ M 1 p k ) \beta^{p_k}=\text{sigmoid}(w^{r\top}M_1^{p_k}) βpk=sigmoid(wr⊤M1pk)
可问答分类器(Answer Possibility Classifier)
同样使用 M 1 p k M_1^{p_k} M1pk作为各分段词向量表示,拼接各分段词向量表示作为分类器输入,引入参数向量 w c ⊤ ∈ R K d w^{c\top}\in\R^{Kd} wc⊤∈RKd,计算可问答概率:
P ( a ) = sigmoid ( w c ⊤ [ M 1 p 1 ; ⋯ ; M 1 p K ] ) P(a)=\text{sigmoid}(w^{c\top}[M_1^{p_1};\cdots;M_1^{p_K}]) P(a)=sigmoid(wc⊤[M1p1;⋯;M1pK])
答案句解码器(Answer Sentence Decoder)
解码器以自回归形式,使用上一步结果产生当前步输出。
词向量层
除使用单向ELMo之外(对未来位置信息位置),解码器词向量层与阅读器词向量层具有相同结构。
为满足生成不同风格答案,解码器使用与风格有关的token作为初始输入,产生对应风格输出,此外,解码器引入初始风格化标记,可避免阅读器依赖于风格化答案。
注意力解码器层
使用堆叠Transformer解码器块作为解码器层,首先将输入线性变换至 d d d维,输出 d d d维序列 { s 1 , ⋯ , s T } \{s_1,\cdots,s_T\} {s1,⋯,sT}。
除编码器块中的两个子层之外,解码器块在两个子层之间,额外引入第二、三子层。自注意力层使用后向序列mask避免解码时看见未来信息,第二、三子层为多头注意力层,分别使用 M q M^q Mq和 M p a l l M^{p_{all}} Mpall作为输入,其中:
M p a l l = [ M p 1 , ⋯ , M p K ] ∈ R d × K L M^{p_{all}}=[M^{p_1},\cdots,M^{p_K}]\in\R^{d\times KL} Mpall=[Mp1,⋯,MpK]∈Rd×KL
多源指针生成器
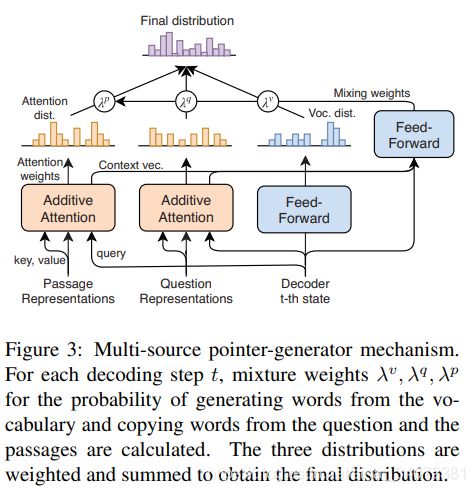
扩展生成机制,使得可从词典或从问句、多段落原文复制生成单词,我们希望复制机制能够共享答案风格。
多元分布生成简述:解码器顶层输出隐状态作为查询向量,输入至段落和问句注意力层,产生两个上下文向量和注意力权重,注意力权重作为复制分布输出概率,上下文向量用于计算复制分布在混合分布的权重。
扩展词典分布
将词典中常见单词,以及输入问句和段落原文单词,组合为扩展词典 V ext V_\text{ext} Vext,则问答句第 t t t单词概率:
P v ( y t ) = softmax ( W 2 ⊤ ( W 1 s t + b 1 ) ) P^v(y_t)=\text{softmax}(W^{2\top}(W^1s_t+b^1)) Pv(yt)=softmax(W2⊤(W1st+b1))
式中输出嵌入矩阵 W 2 ∈ R d word × V ext W^2\in\R^{d_\text{word}\times V_\text{ext}} W2∈Rdword×Vext是输入词向量矩阵的子集,参数 W 1 ∈ R d word × d W^1\in\R^{d_\text{word}\times d} W1∈Rdword×d, b 1 ∈ R d word b^1\in\R^{d_\text{word}} b1∈Rdword。当 y t y_t yt为OOB时,输出概率为0。
复制分布
基于Transformer的Ptr-Net任意选择注意力头产生复制分布,对摘要无显著改进,我们向解码器顶层的复制分布添加注意力层,如对于所有段落,将解码器输出 s t s_t st作为注意力查询向量,输出注意力权重 α t p ∈ R K L \alpha_t^p\in\R^{KL} αtp∈RKL,上下文向量 c t ∈ R d c_t\in\R^d ct∈Rd:
e l p k = w p ⊤ tanh ( W p m M l p k + W p s s t + b p ) α t p = softmax ( [ e p 1 ; ⋯ ; e p K ] ) c t p = ∑ l α t l p M l p a l l , l = 1 , ⋯ , K L \begin{aligned} e_l^{p_k}&=w^{p\top}\tanh(W^{pm}M_l^{p_k}+W^{ps}s_t+b^p)\\[.5ex] \alpha_t^p&=\text{softmax}([e^{p_1};\cdots;e^{p_K}])\\[.5ex] c_t^p&=\sum_{l}\alpha_{tl}^pM_l^{p_{all}},\quad l=1,\cdots, KL \end{aligned} elpkαtpctp=wp⊤tanh(WpmMlpk+Wpsst+bp)=softmax([ep1;⋯;epK])=l∑αtlpMlpall,l=1,⋯,KL
式中,参数 w p , b p ∈ R d w^p,b^p\in\R^d wp,bp∈Rd, W p m , W p s ∈ R d × d W^{pm},W^{ps}\in\R^{d\times d} Wpm,Wps∈Rd×d。
对于问句,使用同样结构的注意力层输出 α t ∈ R J \alpha_t\in\R^J αt∈RJ, c t q ∈ R d c_t^q\in\R^d ctq∈Rd,从而得到在扩展词汇的两个分布:
P q ( y t ) = ∑ j : x j q = y t α t j q , P p ( y t ) = ∑ l : x l p k ( l ) = y t α t l p P^q(y_t)=\sum_{j:x_j^q=y_t}\alpha_{tj}^q,\quad P^p(y_t)=\sum_{l:x_l^{p_{k(l)}}=y_t}\alpha_{tl}^p Pq(yt)=j:xjq=yt∑αtjq,Pp(yt)=l:xlpk(l)=yt∑αtlp
式中, k ( l ) k(l) k(l)表示拼接所有段落得到的序列的第 l l l个单词。
最终分布
使用三个分布的混合作为最终分布:
P ( y t ) = λ v P v ( y t ) + λ q P q ( y t ) + λ p P p ( y t ) , λ v , q , p = softmax ( W m [ s t ; c t q ; c t p ] + b m ) P(y_t)=\lambda^vP^v(y_t)+\lambda^qP^q(y_t)+\lambda^pP^p(y_t),\quad \lambda^{v,q,p}=\text{softmax}(W^m[s_t;c_t^q;c_t^p]+b^m) P(yt)=λvPv(yt)+λqPq(yt)+λpPp(yt),λv,q,p=softmax(Wm[st;ctq;ctp]+bm)
式中,参数 W m ∈ R 3 × 3 d W^m\in\R^{3\times 3d} Wm∈R3×3d, b m ∈ R 3 b^m\in\R^{3} bm∈R3。
联合注意力
为使得不对不相关片段产生注意力,我们对段落单词注意力重新定义:
α t l p = α t l p β p k ( l ) ∑ l ′ α t l ′ p β p k ( l ′ ) \alpha_{tl}^p=\frac{\alpha_{tl}^p\beta^{p_{k(l)}}}{\sum_{l'}\alpha_{tl'}^p\beta^{p_{k(l')}}} αtlp=∑l′αtl′pβpk(l′)αtlpβpk(l)
损失函数
训练损失
L ( θ ) = L dec + γ rank L rank + γ cls L cls L(\theta)=L_\text{dec}+\gamma_\text{rank}L_\text{rank}+\gamma_\text{cls}L_\text{cls} L(θ)=Ldec+γrankLrank+γclsLcls
式中, θ \theta θ是所有参数, γ rank \gamma_\text{rank} γrank, γ cls \gamma_\text{cls} γcls是平衡参数。解码损失 L dec L_\text{dec} Ldec使用所有可回答样本的平均负对数似然:
L dec = − 1 N able ∑ ( a , y ) ∈ D a T ∑ t log P ( y t ) L_\text{dec}=-\frac{1}{N_\text{able}}\sum_{(a,y)\in\mathcal D}\frac{a}{T}\sum_t\log P(y_t) Ldec=−Nable1(a,y)∈D∑Tat∑logP(yt)
分段排序和可回答二分类器损失使用所有样本真实值和预测值的交叉熵:
L rank = − 1 N K ∑ k ∑ r p k ∈ D ( r p k log β p k + ( 1 − r p k log ( 1 − β p k ) ) ) L cls = − 1 N ∑ a ∈ D ( a log P ( a ) + ( 1 − a ) log ( 1 − P ( a ) ) ) \begin{aligned} L_\text{rank}&=-\frac{1}{NK}\sum_k\sum_{r^{p_k}\in\mathcal D}(r^{p_k}\log\beta^{p_k}+(1-r^{p_k}\log(1-\beta^{p_k})))\\[.5ex] L_\text{cls}&=-\frac{1}{N}\sum_{a\in\mathcal D}(a\log P(a)+(1-a)\log(1-P(a))) \end{aligned} LrankLcls=−NK1k∑rpk∈D∑(rpklogβpk+(1−rpklog(1−βpk)))=−N1a∈D∑(alogP(a)+(1−a)log(1−P(a)))
附录:实验数据
- batch_size:80;
- hidden_size d: 304;
- num_heads: 8;
- ffn_inner_state_size: 256;
- num_layers: shared encoding blocks, modeling blocks for a question, modeling blocks for passages, and decoder blocks were 3, 2, 5, and 8;
- embedding_size: Glove 300, ELMo 512 lowercased;
- Vext: 5000;
- seq_len: passages and question 100;
- optiimizer: Adam beta1 0.9, beta2 0.008 eps 1e-8, learning rate 0 -> 2.5e-4 (2,000 steps) -> 0, exponential moving average decay rate 0.9995;
- initializer: N(0, 0.02) for kernel, Zeros for bias;
- regularization: dropout rate 0.3, L2 w 0.01, smoothed positve labels to 0.9;
8块P100 GPU在MS MARCO数据集上跑8个epochs大概6天。